- VOX
- VOX Knowledge Base
- Availability Knowledge Base
- Articles
- Achieving Zero RPO in VMware Environments with Cam...
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
on 04-11-2013 05:20 PM
Implementing fast recovery scenarios outside a single data center may become complex when using VMware environments. Most customers love the idea of using Data Stores as the way to provision storage to the Virtual Machines. The challenge in those environments is how to hold a copy of the data outside the data center, and how to instantly use that copy in case of any failure, without any service disruption.
Many of the solutions proposed by HW vendors will come from the storage virtualization layer, either in the form of replication between the data centers or providing a sync copy within a virtualized LUN. Usually, a Data Store will contain several VM images and data disks. Dedicating exclusive Data Stores is not an option because will bring back the challenges we wanted to avoid.
When using either replication or storage virtualization at the Data Store level, the granularity problem arises. Customers may want to recover VMs in another data center, but not all the ones residing in a Data Store. Replication will be working at the Data Store level, so many times it means all or nothing.
Recently I was reviewing one architecture proposed by one of the leading storage vendors, and when I was reading the details, I realized that a data center failure would need a manual intervention to bring the data back in the secondary data center. That operation, at the storage level, would mean that all the VMs was going to lose access to their storage, and therefore, a lot of manual intervention was going to be needed. Clearly that involves a big service interruption.
The recent Cluster File System supportability announcement of VMDK files as backed storage is bringing new opportunities for customers to enhance their architectures and simplify their operation. Storage Foundation Cluster File System HA offers a complete and integrated stack, composing Clustered Volume Manager, Cluster File System and Veritas Cluster Server. Each layer have a different responsibility and all of them work together to simplify management and increase resiliency in mission critical environments. This is specifically true for those environments where data reside in different data centers.
The below picture represents a configuration where ESXs reside in different data centers, and each of them can access both the local and the remote Data Store. Three Coordination Point Servers for data fencing are used. One of them residing in a third site, and therefore, supporting recovery in case of a complete data center failure.
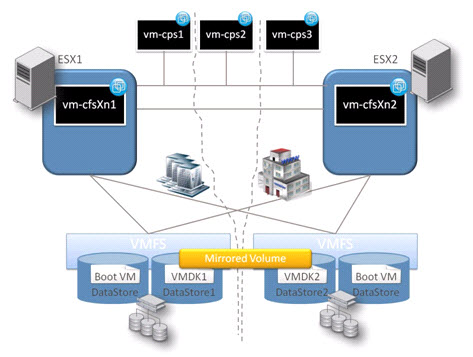
In the scenario presented, each VM will have concurrent access to the same file system. Depending on the application running on the VM it can be used as Active/Active or Active/Passive, where the passive node can be used for offline processing. The Veritas Cluster Server component will guarantee a very fast service recovery in case of any failure (application, resource, VM or ESX). The file system will be created using a mirror, where a copy of the data will reside in each data center. Either a complete storage failure or data center failure will not affect the data integrity and accessibility, as the other nodes will continue reading and writing from the remaining copy.
In order to implement this solution lets make an example with two disks where a mirrored volume will be created. First we will enable site consistency and we will tag each of the components used:
On the nodes in the first site:
# vxdctl set site=site1
On the nodes in the second site:
# vxdctl set site=site2
From one node in any of the sites:
Create a service group with the two disks to be used:
# vxdg -s init datadg vmdk0_0=vmdk0_0 # vxdg -g datadg adddisk vmdk0_1=vmdk0_1
And Tag each of the disks with the site they belong:
# vxdisk settag site=site1 vmdk0_0 # vxdisk settag site=site2 vmdk0_1
Add the disk group to the sites it may belong:
# vxdg -g datadg addsite site1 # vxdg -g datadg addsite site2
And finally enable Site Consistency
# vxdg -g datadg set siteconsistent=on
From now on, every volume and file system created on that disk group will guarantee that a copy of the data reside on each site. Here one example:
# vxassist -g datadg make vol1 maxsize VxVM vxassist INFO V-5-1-16204 Site consistent volumes use new dco log types (dcoversion=30). Creating it by default.
For those of you familiar with previous Cluster Volume Manager versions, a disk group failure policy had to be set. That requirement has been removed in 6.0.1 as now CVM will maintain connectivity to the shared disk group as long as a least one node in the cluster has access to the configuration copies.
The only setting to be decided, based on your requirements, is the disk detach policy. There are two options, the first will allow the cluster to maintain the computational process in case of a storage failure in one of the sites, by detaching the copy of the failed storage from all the nodes, but keeping all nodes up. This option is known as global detach policy.
The second option is to maintain all data copies copies in case of a storage failure affecting a number of nodes (but not all nodes). In this case, the nodes that lost access to one of the copies will also be prevented to write to the other copy, in order to guarantee data consistency. The nodes with access to all the storage copies will continue writing to all of them. This option will guarantee all the copies remain available in case of a local failure.
To minimize failures and improve resiliency, 6.0.1 release incorporate I/O shipping, which allows local writes to be transferred to other nodes of the cluster, and therefore avoiding any error when a local failure happens.
I/O shipping improves the behavior of local detach policy, because for any local partial or total failure, the IOs will be shipped to another node in the cluster, maintaining also all the plexes copies.
In the configuration explained at the beginning of this article, we are going to enable I/O shipping and set the local detach policy in order to observe the behavior with a storage failure. First we will simulate some workload in one of the nodes and then we will disconnect the storage attached in the other site. Secondly, we will remove that storage from the rest of the nodes.
# vxdg -g datadg set ioship=on # vxdg -g datadg set diskdetpolicy=local
Changes can be verified
# vxdg list datadg | egrep "ioship|detach" detach-policy: local ioship: on
Now we disconnect the disk in the second site from the node in the first site, simulating a failure in the communication with the storage. The disk is marked as local failed, because it is a local failure, given that the node in the second site still have access to that storage:
# vxdisk list DEVICE TYPE DISK GROUP STATUS vmdk0_0 auto:cdsdisk vmdk0_0 datadg online shared vmdk0_1 auto:cdsdisk vmdk0_1 datadg online shared lfailed
The IOs are still active, and because the IO Shipping policy, the node availability is not affected. The copy to the second site for every write is sent via the cluster private network.
Now, we will disconnect the disk from the second site too, simulating a local failure in that site. The storage in that site is no longer available for any node.
# vxdisk list DEVICE TYPE DISK GROUP STATUS vmdk0_0 auto:cdsdisk vmdk0_0 datadg online shared vmdk0_1 auto - - error shared - - vmdk0_1 datadg detached was:vmdk0_1
Still, there are no I/O failures and the application is still running and writing to the storage. As soon as the disk is attached back to the nodes, the last writes will be synchronized and redundancy will be recovered:
# vxdisk list DEVICE TYPE DISK GROUP STATUS vmdk0_0 auto:cdsdisk vmdk0_0 datadg online shared vmdk0_1 auto:cdsdisk vmdk0_1 datadg online shared
Therefore, service has never been interrupted even in a complete storage failure in one of the sites, providing a zero RPO.
We saw how Storage Foundation Cluster File System is resilient to storage connectivity failures that affect a subset of the nodes of the cluster by shipping I/O through nodes that remain connected to storage. Thus all copies remain online. Further, we saw that if a storage failure affected all nodes, that copy is detached. The other copy remains online and continues to service I/O
You can try this yourself by attending VISION Las Vegas 2013 next week, and sign on for the “Cluster File System Hands-on Lab”. I hope to see you there!
Carlos.-
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Very informative, I've been looking for this, im happy to find this article. nice share thank you.