- VOX
- Technical Blogs
- Availability
- Erasure coding for data storage - Primer
Erasure coding for data storage - Primer
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
Background
Hardware failure is common and the most common cause among them is disk failure be it SSD or HDD – about 80% of all failures. With such failure prone hardware, data protection has always been an essential need. Traditionally for online/operational data different RAID technologies or mirroring/replication have been in use to provide fault tolerance. Mirrors provide one or more full redundant copies of the data, with virtually no performance overhead, but costly from storage consumption perspective. Alternatives to mirroring have been RAID4/RAID5/RAID6 technologies, which in essence provided similar fault tolerance as mirroring at reduced extra storage requirement, but have limitations on the level of fault tolerance; these technologies cannot provide more than 2 fault-tolerance. With scale-out distributed systems, even if the number of nodes are in the order of 10s, traditional RAIDs do not suffice where need is to withstand more than 2 storage sub-system failures.
What is erasure coding?
Erasure coding is a technology for data protection that adds redundant data to the primary data and then encodes it such that the primary data is recoverable even if some part of encoded data is not available.
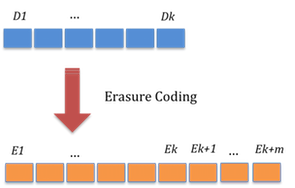
Figure 1: Erasure coding
For example in the figure above, a k-chunks data was erasure coded into k+m chunks data. In general, if m redundant data-chunks are added erasure coding provides m or lesser level of fault tolerance, i.e., the data (D1 … Dk) is recoverable as long as no more than m data chunks, any of the lot, have faulted. In erasure coding parlance, such system is referred as (k, m) erasure-coded system. Erasure codes can primarily be compared based on two properties.
- Whether the code is systematic or non-systematic. A systematic code would keep the primary data in clear form while a non-systematic code will have all data encoded.
- Whether the code is MDS (Maximum Distance Separable) or Non-MDS. If m redundant data chunks used for erasure coding and the data is recoverable even with loss of any m coded-data, it is MDS else not. So essentially it decides how efficient the erasure code is with respect to storage requirement. Storage saving comes at the cost of performance and that’s where the choice between MDS and Non-MDS would matter.
To give example of some erasure codes used in storage systems:
- Reed-Solomon (RS) codes: Systematic and MDS, the most commonly used erasure codes.
- Local Reconstruction codes with RS: Systematic and Non-MDS. Better performing than RS codes as less computation needed for encoding/decoding.
- Tornado Codes: Systematic and Non-MDS. Highly performant but not as storage-efficient.
To illustrate how the erasure codes work, let’s see an analogical example that illustrate how RS codes work. Let x be first part of the data and y be the second part of the data which we want to encode and store. For encoding we can use following equation:
p1 = x + y
p2 = x + 2ySo we have data stored, (x), (y), (x +y), (x +2y) on 4 independent storage systems. As long as any two systems are available, we would be able to re-compute the primary data (x, y) using the two corresponding equations (Note that this is just analogy and not exactly same mathematics works in RS algorithm!). Reed Solomon algorithm uses similar logic albeit it needs to have such operations (like +, -, *, /) be defined in Field* (Field as in mathematics).
How is erasure coding useful in new age storage systems?
As noted, erasure coding helps to access data even if some part of the encoded data is not available. So if the storage system is such that there are independent underlying storage systems, erasure coding can be used to encode and distribute the data across the independent storage systems so that the data is recoverable in case of faults on some underlying systems.
![]()
Figure 2: Distributed storage-system
For example, if each physical disk is independent of each other, erasure coding can be used to build a fault tolerant system over these disks. Another example would be a distributed system using storage in different servers (Refer blog "Scale compute and storage independently with InfoScale Storage 7.1" to know how Veritas Infoscale can help to setup such distributed system). In such a distributed system the data is distributed across servers/nodes so that even if some node go down the data is accessible. Consider this networked distributed system (Figure 2) comprising of 8 machines with internal storage of 2TB each. If one were to configure this system to withstand any 3 faulted nodes, with traditional technology only option would be to configure 4 mirrors.
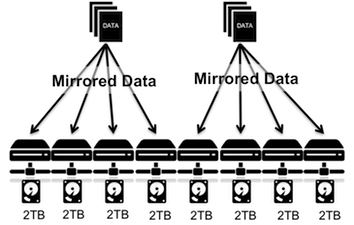
Figure 3: Storage system with mirroring for fault tolerance
So in that case the max usable storage would be 4TB (8*2T/4).
With erasure coding, one can setup (5,3) erasure coded system to withstand 3 faults and thus would be able to setup 10TB of usable storage.
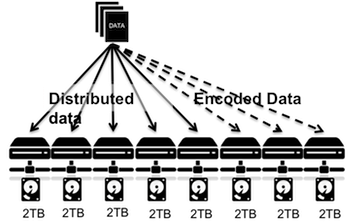
Figure 4: Storage system with erasure coding for fault tolerance
So, in comparison to mirroring in this case, erasure coding helped to provide same fault tolerance with 2.5 times better utilization of the storage.
To conclude, larger the distributed system, higher will be the requirement of fault-tolerance level and one cannot ignore erasure coding as technology when implementing such storage system.
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
- NetBackup Flex Scale provides enterprise resiliency protecting against multiple concurrent failures in Protection
- Enterprise storage management and application availability for Azure VMware Solution in Availability
- Veritas Predictive Insights: The next frontier for data protection in Availability
- Backup Exec 20.3 now available to modernize your Data Protection in Backup Exec
- Backup Exec 20.3 - A small step towards GDPR compliance in Backup Exec
