- VOX
- Data Protection
- Backup Exec
- Hi Is there any different in
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Backup Exec 2012 Convert to Virtual (P2V) Problems
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-24-2012 10:04 AM
Hi all,
I ran in to a few problems while testing out the P2V features in Backup Exec 2012, I hope someone could help.
Environment and Setups:
Everything at BE2012 SP1a level.
Everything running on Windows 2008 R2 SP1
1x VMware vCenter 5 server with a few ESXi hosts; everything running VM hardware version 8.
1x Central Admin Server (CASO) called BUEXEC2012
1x Managed server call BE2012-M1. This server is a deduplication device host. It uses Centrally managed Backup Exec server mode and Unrestricted access to catalogs and backup sets for restore mode.
1x Server to be converted, called R-2008R2-01. It is actually a VM itself. It has 2 vmdk disks. The first vmdk has the C: and D: drive, the second vmdk has the E: drive.
Note: All Logon Accounts are copied from BUEXEC2012 to BE2012-M1; they have an identical list of credentials on the Logon Account Management screen.
Steps to reproduce problem:
1. Create a job on BUEXEC2012 (This is the CAS, remember?) to fully backup everything on R-2008R2-01. SDR mode is confirmed to be ON.
Job sends data to the dedupe device that is hosted on BE2012-M1 (The managed server).
2. Backup completes successfully.
3. Use the "Convert to Virtual from Point-In-Time" button to create a conversion job.
Select everything: System State, C:, D:, and E:.
Configure VM related settings: vCenter credentials, datastores, VM RAM, disks, VMware Tools Iso location, etc.
VMware Tools Iso image is located at a local drive path on BUEXEC2012.
Note:
If you have been following, you will see that this job is going to be delegated to BE2012-M1.
This is because the backup went to the dedupe disk that is managed by BE2012-M1, therefore when the data is requested, BE2012-M1 has to "handle" the job.
4. Job runs for 20 seconds, fails.
See attached screenshot named alert - job failed screen.jpg and the log file named alert - job failed log.txt.
5. Log on to BE2012-M1 locally (the managed server that hosts the dedupe disk).
6. While locally on BE2012-M1, create the exact same job and run it. (Almost the same, except that the VMware Tools Iso image now points to a local copy on BE2012-M1.)
Note:
This is different to when the job was created on BUEXEC2012 (the CAS), because this time, the job is not "delegated" to BE2012-M1; the job is now created locally on the managed server itself.
7. Job completes successfully.
(This is evidence that: Doing this from the Central Admin Server = Fail; do this from the managed server that holds the backup = success)
8. Check on vCenter, see the new VM, delete its snapshot (This must be done according to page 439 of the be2012 admin guide).
9. Edit the new VM's settings, discovers that the Network Card is missing, add it back. (Why wasn't it created?)
10. Power on the new VM, see the Windows Error Recovery screen.
See the attached screenshot named windows error recovery.jpg.
11. Choose to start Windows normally anyway.
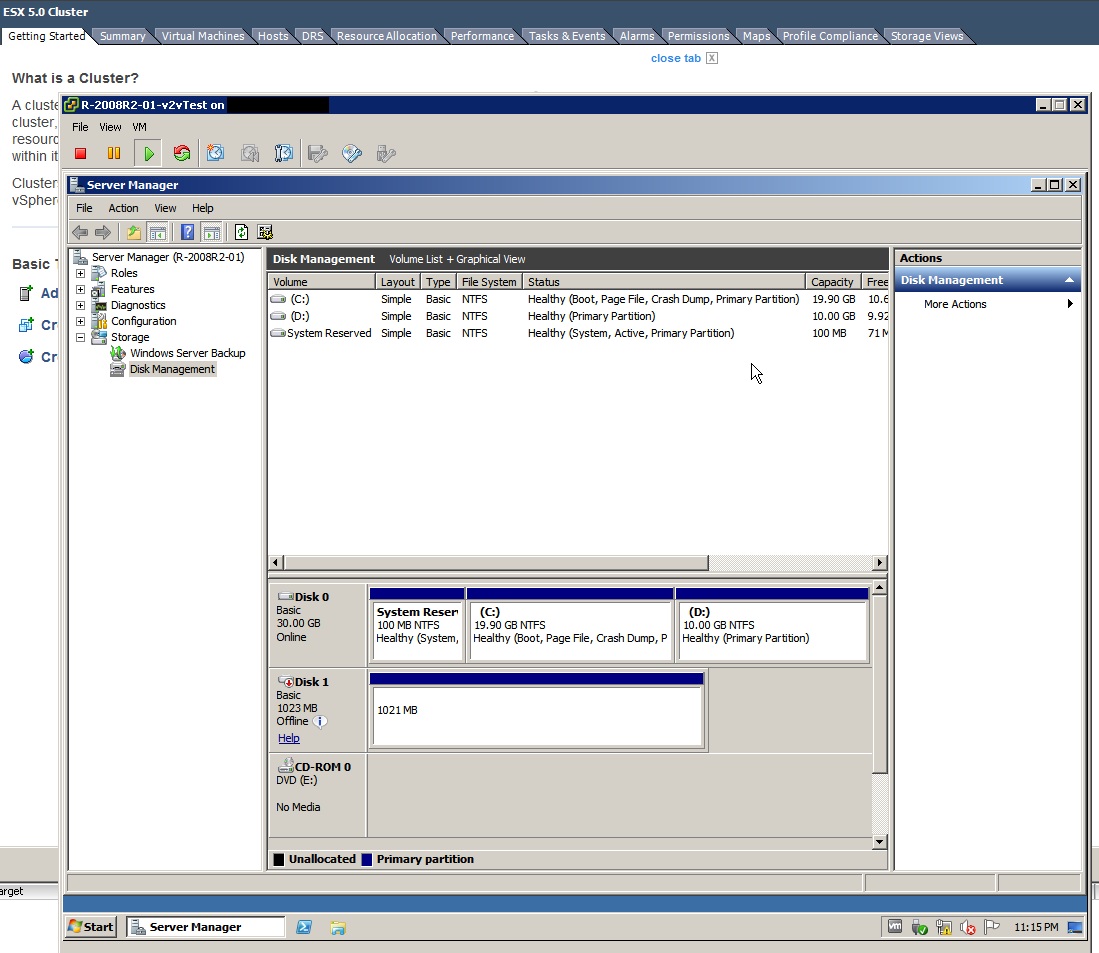
12. Boots up normally, restarts once on prompt, then inspect Windows Disk Management.
See the attached screenshot named offline uninitialized disk.jpg
So the original E: drive disk is present, but it is marked "offline" and is not initialized.
The rest of the OS seems normal.... I hope.
Summary, questions, and everything else:
A. Why does the convert job fail on the CAS, but succeeds on the managed server?
B. I have actually tested this: If the original backup goes to a storage device managed by the CAS server itself, the convert-job created on the CAS would create the VM successfully. This is evidence that the convert job would only run successfully on whichever server that "holds" the source-backup. Is that normal? I thought I could do everything from the CAS and not having to worry about doing things locally on managed servers.
C. After a P2V job completes successfully, why isn't the VM's network interface card (NIC) created?
D. Is it true that after every successful P2V job, the first time you try to boot the VM you will see the Windows Error Recovery screen? Is this normal? If so, why isn't it documented?
E. Why is the E: drive not properly restored? It is just "offline" and "uninitialized".
Does that mean the data on it is as good as gone? Why is this happening? How do I "online" and "initalize" it without destroying its data?
F. It doesn't make any difference whether I integrate the "convert to VM stage" inside the backup job. The same problems would still happen. All of them.
Has anyone mastered P2V on Backup Exec 2012 yet? Could you offer some guidance?
Thank you in advance.
RLeon
{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-25-2012 12:02 AM
Found this post:
https://www-secure.symantec.com/connect/forums/be2012-p2v-and-b2v-conversion
So apparently:
AshwinApte - SYMANTEC EMPLOYEE:
This is by design. The NIC card needs to be added manually since it may cause conflicts between the current system and the converted machine and the VMware tools also needs to be installed separately depending on what version of ESX you are running the converted machine on.
I would have preferred if this important information is included in the admin guide.
But hey, that answers my question C.
Still A, B, D, E and F to go...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-26-2012 02:36 AM
Hi,
For A the issue is probably what you pointed out: location of vmware tools iso image. One question: are both CAS and Managed server in a domain? if not trying defining same Administrator password on both servers and try to see if that fixed the issue.
Regards
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-26-2012 04:02 AM
Hi Altimate1,
Thanks for taking interest!
I did forget to mention that everything is in a domain.
Both CAS and the Managed Server are installed using the domain admin account.
The VC is in the domain; the host I'm trying to convert is also part of the domain.
Things should be consistent in terms of domain, account and passwords.
The Backup Exec's own "Logon Account Management" list of accounts are also identical between the two servers.
Just to be sure, I re-setup the entire environment (ENTIRE).
This time, I made sure that both CAS and the Managed Server use the same installation path, just in case I've not accidentally triggered another "installation path glitch".
(I'm referring to this problem in my other post: https://www-secure.symantec.com/connect/forums/be-2012-caso-managed-server-missing-job-logs-unofficial-fix-included)
But, same problems. (Back to talking about this post now)
So installing both servers using the Backup Exec default-path doesn't help.
Still facing the same error when delegating the vm conversion-job to the Managed Server.
About the VMware Tools Iso image location, what do you suggest?
When you configure the vm conversion-job from the CAS, the field that asks you for the Iso seems to only accept a path to a local copy. (Local = relative to where you setup the job, in this case, I setup the job on the CAS, therefore it has to be a local path to a copy of the Iso file stored locally on the CAS)
It doesn't really let you select the copy on the Managed Server, if that is what you are implying.
RLeon
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-26-2012 08:17 AM
Wouldn't it be possible to open BE console on the managed server and connect to the CAS server... This way, may be 'local' disk offered as part of vmware tools iso image location selection will be one from the managed server.
Hope this could help
Regards
Bernard
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-26-2012 08:24 AM
I like the way you think.... This pure madness might just work...
Nope. Just tested it, it doesn't work that way.
So I logged on locally to the Managed Server, launched the BE console but stopped it from loading the local details;
connected it to the CAS so that essentailly the BE console on the Managed Server "remotely manages" the CAS operations;
went to the part where it asks for the path to the VMware Tools Iso, then guess what?
It only let me browse the CAS's files.
RLeon
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-26-2012 08:50 AM
I confirm the behavior!
It come to mind that the failure could be caused by an access right issue between CAS and managed server. Did you ensure that you are able to access the corresponding CAS folder/file from managed server?
Finally as a tentative, may I suggest adding on the managed server a hosts resolution to /etc/hosts so that the \\CAS_Server resolv to \\BE_managed_server ! (and placing a copy of windows.iso image in same tree structure on the managed server).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-26-2012 06:58 PM
I kind of see what you are getting at, but the path that must be entered to that field has to be in the following format; so if I'm doing this from the CAS, it must look like:
\\buexec2012.domain.com\D:\vmware_tools_iso.iso
And if I do this from the Managed Server, it must look like:
\\be2012-m1.domain.com\D:\vmware_tools_iso.iso
As you can see, the host must be specified, so it doesn't only look at the directory path.
As for editing the hosts file to "trick" it, even if it does work, I don't think I would go this far just so VM conversion would work in a CASO environment.
I'd rather just write this feature off as non-existent in BE2012.
(I wish the hosts file on Windows is that close to root; it'd save so much time getting to it....)
RLeon
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-27-2012 12:12 AM
I agree but let think that configured on the CAS, the path (defined elsewhere in a script will be \\buexec2012.domain.com\D:\vmware_tools_iso.iso . I guess the conversion fail because executed from managed server that can be resolved because D: don't look as a share. Therefore I think that (at least for test purpose) adding an entry in etc/hosts on the managed server so that "buexec2012.domain.com" translate to localhost would fake the script. However this can't be a long term solution!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-27-2012 12:33 AM
I guess it does look like a strange path, but it is entered automatically and there is on way to change it.
Anyhow, have you encountered the problems D and E, after a "successful" vm conversion job? (It can be 'successful', if you are not delegating it in a CASO environment, as I have documented...)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-27-2012 02:51 AM
Regarding question D ( Is it true that after every successful P2V job, the first time you try to boot the VM you will see the Windows Error Recovery screen? Is this normal? If so, why isn't it documented?)
Yes, this is true... you will have this with every snapshot based backup. Because at time the snapshot is taken, the OS is running.
Regarding E, I can't answer.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-27-2012 04:04 AM
You are the first ever person on Symantec Connect to give a firm, solid confirmation that the Windows Error Recovery screen would appear after an online (hot) snapshot backup of an entire system is restored.
I thought I was the only one.
The way I understand it, since VSS made everything consistent in the snapshot, there really is no harm.
I think Windows throws that screen because it doesn't remember being properly shutdown. (But things should be ok because everything is 'consistent'.)
You get an upvote for that. I wish I could give you some karma to go with it.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-27-2012 04:52 AM
That could be useful, thanks.
Now that I think about it, the same thing happens when you do VM level restores (AVVI; vSphere API) because of the same reason.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-27-2012 04:53 AM
Thank you. Here is a free gift which could help disabling this alert (set it in the source machine):
[HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Microsoft\Windows NT\Reliability]
"ShutdownReasonOn"=dword:00000000
I don't try it recently but I use to set it some time ago during training / demo.
Regards
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-28-2012 12:14 AM
Yes! BTW: regarding A issue, I think that you should open a case so that this issue could be taken in account.
Regards
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-28-2012 01:29 AM
While that would be an excellent suggestion under normal circumstances, I'd rather not stress them right now (which in turn, would also not cause myself unnecessary stress...).
I'd give them at least a few more months.
Or my time runs out.
Through sheer luck I'm in a position to do all the due diligence I'd ever want.
I can imagine how someone else will be forced to open a case.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-11-2012 08:51 PM
Hi
Is there any different in doing a Conversion to Virtual (P2V), without the CAS & MMS?
Thanks in advance
Kongkon
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-11-2012 09:45 PM
If you only have one Backup Exec server in your environment, you should not have this problem.
In this thread I document a problem that happens when you have more than one Backup Exec 2012 server. (1 CAS and some MMS).
However, you may still encounter my 'E' problem where some restored vmdk may appear to be offline and uninitialized in the restored and booted up Windows. Is the data actually gone too? I didn't bother checking.
This problem happened when the VM Windows only has MBR basic disk volumes. I.e., This is not even a dynamic-disk or GPT-partition related problem.
RLeon
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-19-2012 07:16 AM
Hi,
I am facing an issue where after P2V using Backup Exec (backup to disk and convert to virtual) i am unable to logon to OS (Windows) though it powered on successfuly on VMware ESX. I tried login using Local Administrator/Domain accounts of Windows. Can anyone suggest me on this? Anything else i need to take care of during this process?
Tried p2v a couple of times, restoration completed successfuly everytime but only login issue remains.
Thanks in advance,
MJ
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-19-2012 08:04 AM
You might want to try starting a new thread about this to get more exposure to your specific problem.
- NBU 10x tape 2 tape copy (inline copy) clarification. in NetBackup
- Attention DBAs! New with NetBackup 10.4, PostgreSQL Recovery to PIT in Hours/Minutes/Seconds!! in NetBackup
- Restoring VHD From Cloud, VHD file disappears - Resolved in Backup Exec
- BackUp Exec Gold 1TB 24months in Backup Exec
- Third Copy Of Data in NetBackup
