- VOX
- Data Protection
- Backup Exec
- sbora, Desperate to find a
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Backup Exec 2012 SP4 - Job ends with Completed status: Canceled
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-09-2014 08:14 AM
Hello All,
I am looking for a solution to fix this pesky error I receive on a few jobs: Completed status: Canceled
The job was canceled because the response to a media request alert was Cancel, or because the alert was configured to automatically respond with Cancel, or because the Backup Exec Job Engine service was stopped.
I am hoping it is just an auto-response setting somewhere, but I cant figure out where. Seems that all the TECH notes relate to tape media which I have none.
This is the backup path: Windows 2003/2008 (Client-Side Dedup) >> Windows 2008R2 (Backup Exec 2012 SP4, CASO, DeDup Folder) >> 100Mbps WAN Connection to >>Windows 2008 R2 (MMS, DeDup Folder).
The job is Backup Server on CASO then Duplicate to MMS and works for the other 6 jobs just not these two. The backup stage is completing successfully, just not the duplicate. Very strange since there is no tape device in the loop. Also, the job engine has not stopped so, that's where I believe it must be a setting somewhere.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-09-2014 09:56 AM
...have you tried to recreate this partcular job?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-09-2014 10:05 AM
Hello Syntex,
If you go to the Backup Exec button, Configuration and Settings click on Error-Handling Rules and see if the Job Cancellation Setting is enabled.
Check the Windows Event logs of these servers for errors that occur during the backup window.
try recreating one of the jobs to see if that helps
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-09-2014 03:29 PM
Recreated the job and ran the full backup again, Same thing: Cancelled
Also, the error handling is stock/default:
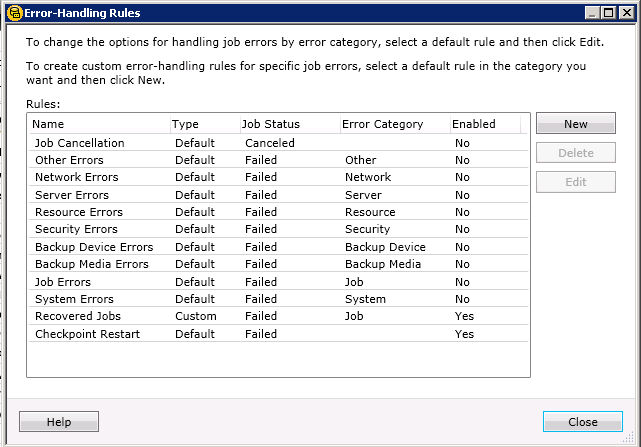
Still looking for ideas
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-09-2014 11:34 PM
..what resources are those jobs backing up?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-10-2014 04:41 AM
Hello Syntex,
Are you backing up system state with GRT in this backup job? Please have a look at this technote and check if it relates to your issue:
http://www.symantec.com/docs/TECH211192
Thanks,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-10-2014 12:53 PM
Hello, Both jobs are broken-out SQL database backups per BE 2012 Best Practices. They are Monthly-Full-52 Week Retention, Weekly-Full-26 Week Retention, Daily-Incremental-26 Week Retention, and 3 hour incremental durning day- 26 Week Retention. All stages duplicate to the second datacenter with 2 week retention on the MMS just incase the NOC falls down. No System State. I have 4 other jobs running the same job spec/retention without any issue.
Here is a little more info:
I removed the duplication stages from the job and let it run as scheduled @ 8:00am, All looks good with that.
I addad back the duplicate stages to the job and let it run as scheduled @ 11:00am and it failed with the cancel job.
To further isolate it; I re-ran only the canceled 11:00am duplicate and watched the job progress. The job ran the duplicate (Loading Media, Pre-Processing, Running, Verify, Loading Media, Running) and ended with canceled.
I removed the "Verify" from the 11:00am duplicate stage and selected "Run Now" directly on the 11:00am duplicate job, same result.
Data seems to be duplicating:

Altho this is very old post: http://www.symantec.com/connect/forums/duplicate-jobs-failing-0 the second comment is very similar because his is also all disk based storage.
I am going to catalog the MMS to see if there is any bad OST media and report the results back here.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-10-2014 06:24 PM
Well the Inventory and Catalog on the MMS Deduplication folder was sucessful. I had 15 minutes of quiet time on both servers where no jobs were running so, I re-ran the canceled 4:00pm duplication job with SGMon and it reviled a few curious things.
The things that I noticed were these lines:
DeviceIo: STS: Error: impl_open_image impl_image_handle error (2060018:file not found)
VerifyJob::GetTargetMediaDeviceName(): Execute(ADAMM_MOVER_EXECUTE_GET_SERVER_INFO) No server found.
I really do not understand these logs and I was hoping someone could help me decode them? The log is kinda long to post.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-11-2014 05:39 AM
Hello Syntex,
I have sent you a PM with the information on the log we need to further investigate the issue. Can you please create a support case and provide us with the logs? You can PM me the case id once you have a created a case.
Thanks,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-11-2014 12:56 PM
sbora, Desperate to find a solution and try to understand why some duplicate jobs were successful and two were not, I paused the queue and waited for everything to quiet down again. Running SGMon on the CASO; I reran the job again with a slightly different result:
DS session handle: 0000000004172C20(0000000001570A50) closed.
ndmp_readit: Caught message on closed connection. Socket 0x484 len 0xffffffff
ndmp_readit: ErrorCode :: 0 :
ERROR: ndmpcSendRequest->connection error
ERROR: ndmpSendRequest failed:
ndmp_writeit: NDMP Socket Error when trying to write message. Socket 0x484 len 0x1c
CSecuritySSLConnection::Shutdown: SSL_shutdown returned 336195711 (error:1409F07F:SSL routines:SSL3_WRITE_PENDING:bad write retry).
I thought to myself SSL connection issue, Lets rebuild SSL:
1. Shut down BE services on the MMS.
2. From the Symantec\Backup Exec\Agents\RAWSX64 folder, I ran Setupaax64 and Setupaofox64.
3. Moved the .crt and .key files to the desktop from the Symantec\Backup Exec\Data folder.
4. Restarted the services and reestablished trust with all the servers in the list.
5. Re-Ran the 2 auto-canceled jobs, Success!!!!!
Ending job 'server1.mydomain.com Backup SQL-Duplicate-Weekly' with success status
Ending job 'server2.mydomain.com Backup SQL-Duplicate-Weekly' with success status
I am not saying my procedure to correct SSL issues is the correct one but, It has been the silver bullet for me before with connection issues to remote servers. Day 1: Lets see how the backups go tonight ![]()
