Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- VOX
- Availability
- Cluster Server
- Relation between groups of resources and ClusterSe...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Relation between groups of resources and ClusterService
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-14-2009 10:22 AM
Hi,
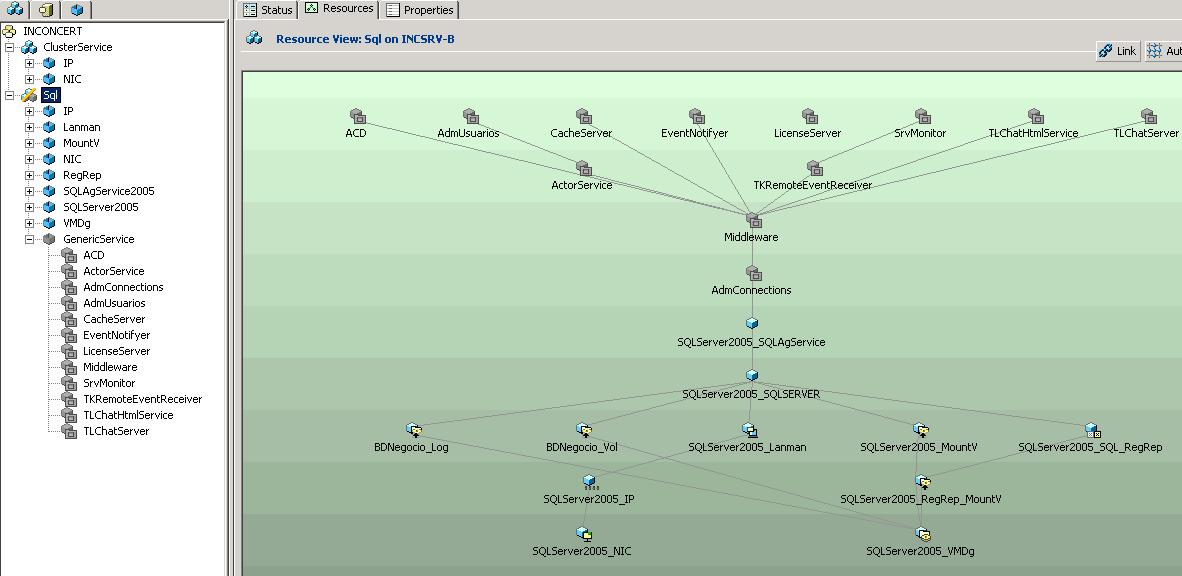
1 - A VCS SQL2005 Service group creates following the manuals. But encounter in the administration console that I have created 2 groups of resources. First it is the ClusterService that create at the beginning of the manual and VCS SQL 2005 Service group that was the one that finally needed.
- what is the relation between the 2 groups?
- It is necessary that it maintains the ClusterService in my solution?
2 - I am adding own services (GenericServices) in the VCS SQL2005 Service group so that they rise as soon as the service of SQL.
The consultation in this point:
-It is advisable and possible to create a Group of resources and to do a Link between the group of SQL and the one of GenericsServices that I try to create?
3 - In the manual to create the VCS SQL2005 Service group it indicates that a Volume in the shared disc for storage of the registry of Veritas is due to create. In the same way I create a resource to mount the volume and a RegRep to talk back registry indicated.
-So that it is so necessary to make this replication?
-There is possibility that when recovering itself registry in the other node no longer rises by differences in the configuration of the nodes (ex, different disk drives where settled Veritas ARE 5,1)?
Please see the attach with the image of cluster configuration.
Regards.
1 - A VCS SQL2005 Service group creates following the manuals. But encounter in the administration console that I have created 2 groups of resources. First it is the ClusterService that create at the beginning of the manual and VCS SQL 2005 Service group that was the one that finally needed.
- what is the relation between the 2 groups?
- It is necessary that it maintains the ClusterService in my solution?
2 - I am adding own services (GenericServices) in the VCS SQL2005 Service group so that they rise as soon as the service of SQL.
The consultation in this point:
-It is advisable and possible to create a Group of resources and to do a Link between the group of SQL and the one of GenericsServices that I try to create?
3 - In the manual to create the VCS SQL2005 Service group it indicates that a Volume in the shared disc for storage of the registry of Veritas is due to create. In the same way I create a resource to mount the volume and a RegRep to talk back registry indicated.
-So that it is so necessary to make this replication?
-There is possibility that when recovering itself registry in the other node no longer rises by differences in the configuration of the nodes (ex, different disk drives where settled Veritas ARE 5,1)?
Please see the attach with the image of cluster configuration.
Regards.
Labels:
ClusterIC.JPG
{kind=link}
77 KB
4 REPLIES 4
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-15-2009 01:51 PM
Hi DeigoT,
Below are the answers to your questions. If you require any additional detal, please let me know. Also, I was a little unclear on what you were looking for on Question #3, so please provide some clarification if the information I have provided doesn't satisfy your request.
1. There is no relationship between the 'Cluster Service' Service Group and the one configured for SQL. The Cluster Service Service Group is used in cases where a Global Cluster is being configured, or when clusting the web console available with SFW-HA and/or the Notification resource agent to allow SNMP or SMTP notifications to be sent concerning cluster activity. In regards to SQL, is has no relation and doesn't even have to exist.
2. The way your group is currently configured per the screenshot (GenerService resources linked above SQL) is a good solution as long as your goal is to ensure that not only SQL is online, but also all of the Generic Services (i.e. Generic Services are dependent on SQL and must always be brought online on the same node as SQL, and futhermore, if any of the services fail, you want the Generic Services and SQL to failover to another node.. The only reason you would consider creating a separate Disk Group with your Generic Services and creating Service Group dependencies is in cases where you wanted to alter the fail-over policies for these. For example, if SQL faults, you only want the Generic Services to fail-over if SQL comes online successfully on the fail-over node. If SQL fails to online, the Generic Services would remain on the original node. There are several different ways dependencies can be configured, and I have included a summary of these at the bottom of this post (it's pretty lengthy), but again, the way it is currently configured is good as long as these Generic Services truly depend on SQL, and you don't want to alter the way a failover occurs.
3. Sorry, but I do not believe I understand the question being asked here. The RegRep volume is used in a clustered SQL environment because there are several SQL registry keys that frequently change while SQL is online. When a fail-over occurs, these changes need to be put in place on the passive node to ensure it is in the exact same state as the original server. When the RegRep resource comes online on the node where the group is failing over to, it imports the registry informaition prior to bringing SQL online. This is definitely a requirement and needs to be put in place to ensure SQL functions properly when moving/failing over between nodes.
When a SQL server is online on a node and one of the monitored keys/values changes, that change is immediately written to the RegRep volume; therefore, even during an unexpected server failure, the necessary registry information will be on place on the volume and will be imported on the fail-over node when the RegRep resource comes online.
I hope this helps!
Cheers,
rjhanley
Here is the Service Group dependency information as mentioned in Question #2. In your case, your SQL group would be the child and your Generic Service group would be the parent. This is probably the opposite of what you would expect, but just remember, a Parent depends on a child.
Service Group Dependencies:
Online Local
A Child service group must be online on a system before a Parent service group can come online on the same system.
Online Local Soft
Child Fault: Child fails over to an available system and Parent fails over to the same system. If a failover system doesn't exist for the Child group, the Parent group continues to run on the original system. A fail-over of the Parent doesn't occur until the Child SG successfully onlines on an available system. At that time, the Parent will then follow the Child.
Parent Fault: No fail-over for Parent and Child continues to run on the original system
Online Local Firm
Child Fault: Child faults and Parent is immediately taken offline. Child fails over and starts on an available system, and the Parent will then be started on the same system as the Child. If there is no available system for the Child, Parent is taken offline and both Parent and Child remain offline.
Parent Fault: If the Parent Faults, there is no failover and Child continues to run on the original system.
Online Local Hard
Child Fault: Child faults and Parent is taken offline. Child fails over and starts on an available system, and the Parent will then be started on the same system as the Child. If there is no available system for the Child, Parent is taken offline and both Parent and Child remain offline
Parent Fault: If Parent faults, Child fails over to an available system and the Parent is then started on that same system. If no failover system is available for the Parent, then the Child remains online on the original system.
----------------------------------------------------------------------------------------------------
Online Global
A Child service group must be online on a system before the Parent service group can come online on any system in the cluster.
Online Global Soft
Child Fault: If Child faults, it will fail-over to an available system. The Parent will continue to run on the original system. If there is no system available for the Child to failover to, the Child dies and Parent remains online.
Parent Fault: If Parent faults, Parent fails over to an available system. The Child will continue to run on the original system. If there is no system available for the Parent to failover to, the Parent dies and Child remains online.
Online Global Firm
Child Fault: If Child faults, Parent is taken offline. Child will then fail-over to an available system and Parent restarts on the original system. If no fail-over system exists, the Parent is taken offline and both Child and Parent will remain offline.
Parent Fault: If Parent Faults, Parent fails over to an available system and Child continues to run on the original system. If no failover system exists for the Parent, the Parent remains offline and the Child remains online.
Online Remote
A Child service group must be online on a remote system before the Parent service group can come online on the local system.
----------------------------------------------------------------------------------------------------
Online Remote Soft
Child Fault: If Child faults, Child fails over. If Child fails over to the system on which the Parent was online, the Parent restarts on a system different from the child. Otherwise, parent continues to run on original system. If there is no available system for the Child to failover to, the Child dies and the Parent continues running.
Parent Fault: If Parent faults, the Parent fails over to a system without Child. If the only system available is where the Child is running, the Parent is not brought online. If there is no available system for the Parent to failover to, the Parent dies and the Child continues running.
Online Remote Firm
Child Fault: If Child faults, Child fails over. If Child fails over to the system on which the Parent was online, the Parent restarts on a system different from the child. Otherwise, parent continues to run on original system. If there is no available system for the Child to failover to, the Parent is taken offline and both Parent and Child die.
Parent Fault: If Parent faults, the Parent fails over to a system without Child. If the only system available is where the Child is running, the Parent is not brought online. If there is no available system for the Parent to failover to, the Parent dies and the Child continues running.
Offline Local
A Parent service group can be started on a local system only if the Child service group is offline (not running) on the local system. However, that Child group can be running on any other system.
Child Fault: If Child fails over to system on which parent is running, the Parent is taken offline. If Parent is taken offline, it starts on another system, if available. If no Failover system exists for the Child, the Child faults and the Parent continues running.
Parent Fault: Parent fails over to system without Child. If no failover system exists for the Parent, the Parent dies and the Child continues running.
Below are the answers to your questions. If you require any additional detal, please let me know. Also, I was a little unclear on what you were looking for on Question #3, so please provide some clarification if the information I have provided doesn't satisfy your request.
1. There is no relationship between the 'Cluster Service' Service Group and the one configured for SQL. The Cluster Service Service Group is used in cases where a Global Cluster is being configured, or when clusting the web console available with SFW-HA and/or the Notification resource agent to allow SNMP or SMTP notifications to be sent concerning cluster activity. In regards to SQL, is has no relation and doesn't even have to exist.
2. The way your group is currently configured per the screenshot (GenerService resources linked above SQL) is a good solution as long as your goal is to ensure that not only SQL is online, but also all of the Generic Services (i.e. Generic Services are dependent on SQL and must always be brought online on the same node as SQL, and futhermore, if any of the services fail, you want the Generic Services and SQL to failover to another node.. The only reason you would consider creating a separate Disk Group with your Generic Services and creating Service Group dependencies is in cases where you wanted to alter the fail-over policies for these. For example, if SQL faults, you only want the Generic Services to fail-over if SQL comes online successfully on the fail-over node. If SQL fails to online, the Generic Services would remain on the original node. There are several different ways dependencies can be configured, and I have included a summary of these at the bottom of this post (it's pretty lengthy), but again, the way it is currently configured is good as long as these Generic Services truly depend on SQL, and you don't want to alter the way a failover occurs.
3. Sorry, but I do not believe I understand the question being asked here. The RegRep volume is used in a clustered SQL environment because there are several SQL registry keys that frequently change while SQL is online. When a fail-over occurs, these changes need to be put in place on the passive node to ensure it is in the exact same state as the original server. When the RegRep resource comes online on the node where the group is failing over to, it imports the registry informaition prior to bringing SQL online. This is definitely a requirement and needs to be put in place to ensure SQL functions properly when moving/failing over between nodes.
When a SQL server is online on a node and one of the monitored keys/values changes, that change is immediately written to the RegRep volume; therefore, even during an unexpected server failure, the necessary registry information will be on place on the volume and will be imported on the fail-over node when the RegRep resource comes online.
I hope this helps!
Cheers,
rjhanley
Here is the Service Group dependency information as mentioned in Question #2. In your case, your SQL group would be the child and your Generic Service group would be the parent. This is probably the opposite of what you would expect, but just remember, a Parent depends on a child.
Service Group Dependencies:
Online Local
A Child service group must be online on a system before a Parent service group can come online on the same system.
Online Local Soft
Child Fault: Child fails over to an available system and Parent fails over to the same system. If a failover system doesn't exist for the Child group, the Parent group continues to run on the original system. A fail-over of the Parent doesn't occur until the Child SG successfully onlines on an available system. At that time, the Parent will then follow the Child.
Parent Fault: No fail-over for Parent and Child continues to run on the original system
Online Local Firm
Child Fault: Child faults and Parent is immediately taken offline. Child fails over and starts on an available system, and the Parent will then be started on the same system as the Child. If there is no available system for the Child, Parent is taken offline and both Parent and Child remain offline.
Parent Fault: If the Parent Faults, there is no failover and Child continues to run on the original system.
Online Local Hard
Child Fault: Child faults and Parent is taken offline. Child fails over and starts on an available system, and the Parent will then be started on the same system as the Child. If there is no available system for the Child, Parent is taken offline and both Parent and Child remain offline
Parent Fault: If Parent faults, Child fails over to an available system and the Parent is then started on that same system. If no failover system is available for the Parent, then the Child remains online on the original system.
----------------------------------------------------------------------------------------------------
Online Global
A Child service group must be online on a system before the Parent service group can come online on any system in the cluster.
Online Global Soft
Child Fault: If Child faults, it will fail-over to an available system. The Parent will continue to run on the original system. If there is no system available for the Child to failover to, the Child dies and Parent remains online.
Parent Fault: If Parent faults, Parent fails over to an available system. The Child will continue to run on the original system. If there is no system available for the Parent to failover to, the Parent dies and Child remains online.
Online Global Firm
Child Fault: If Child faults, Parent is taken offline. Child will then fail-over to an available system and Parent restarts on the original system. If no fail-over system exists, the Parent is taken offline and both Child and Parent will remain offline.
Parent Fault: If Parent Faults, Parent fails over to an available system and Child continues to run on the original system. If no failover system exists for the Parent, the Parent remains offline and the Child remains online.
Online Remote
A Child service group must be online on a remote system before the Parent service group can come online on the local system.
----------------------------------------------------------------------------------------------------
Online Remote Soft
Child Fault: If Child faults, Child fails over. If Child fails over to the system on which the Parent was online, the Parent restarts on a system different from the child. Otherwise, parent continues to run on original system. If there is no available system for the Child to failover to, the Child dies and the Parent continues running.
Parent Fault: If Parent faults, the Parent fails over to a system without Child. If the only system available is where the Child is running, the Parent is not brought online. If there is no available system for the Parent to failover to, the Parent dies and the Child continues running.
Online Remote Firm
Child Fault: If Child faults, Child fails over. If Child fails over to the system on which the Parent was online, the Parent restarts on a system different from the child. Otherwise, parent continues to run on original system. If there is no available system for the Child to failover to, the Parent is taken offline and both Parent and Child die.
Parent Fault: If Parent faults, the Parent fails over to a system without Child. If the only system available is where the Child is running, the Parent is not brought online. If there is no available system for the Parent to failover to, the Parent dies and the Child continues running.
Offline Local
A Parent service group can be started on a local system only if the Child service group is offline (not running) on the local system. However, that Child group can be running on any other system.
Child Fault: If Child fails over to system on which parent is running, the Parent is taken offline. If Parent is taken offline, it starts on another system, if available. If no Failover system exists for the Child, the Child faults and the Parent continues running.
Parent Fault: Parent fails over to system without Child. If no failover system exists for the Parent, the Parent dies and the Child continues running.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-16-2009 04:19 AM
V-16-1-13067 Thread(4) Agent is calling clean for resource(IAPP) because the resource became OFFLINE unexpectedly, on its own.
Jul 0000:35:25 prod1 Had[4156]: [ID 702911 daemon.notice] VCS ERROR V-16-1-10205 Group XXX is faulted on system prod1
Jul 0000:38:56 prod1 Had[4156]: [ID 702911 daemon.notice] VCS ERROR V-16-1-13067 (skypos-prod2) Agent is calling clean for resource(APP) because the resource became OFFLINE unexpectedly, on its own.
I am also getting this messages, please advise.
Cluster srvice running on node1 and application online on node2,
If I do failover, to node1, above mentioned errors come.
How can i enable failver (manual) to the node 1.
New to this setup...
BR,
AAMIR
Jul 0000:35:25 prod1 Had[4156]: [ID 702911 daemon.notice] VCS ERROR V-16-1-10205 Group XXX is faulted on system prod1
Jul 0000:38:56 prod1 Had[4156]: [ID 702911 daemon.notice] VCS ERROR V-16-1-13067 (skypos-prod2) Agent is calling clean for resource(APP) because the resource became OFFLINE unexpectedly, on its own.
I am also getting this messages, please advise.
Cluster srvice running on node1 and application online on node2,
If I do failover, to node1, above mentioned errors come.
How can i enable failver (manual) to the node 1.
New to this setup...
BR,
AAMIR
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-17-2009 08:42 AM
Aamir,
Can you start a new thread since this is not related to the issue this post was created for?
Also, can you provide the type of resource the IAPP is? Is it a VMDg, MountV, IP, LanMan, GenericService, etc...?)
If you look in the %VCS_HOME%\log directory, there will be a log file for each resource type: <resource_type>_A.txt (i.e. GenericService_A.txt, IP_A.txt, SQL2005_A.txt, etc..)
Once you determine what type of resource is failing, you can open the proper log file which should also provide more detail as to why the resource failed to online.
The error you are seeing normally occurs when a resource goes offline outside of the cluster. For example, let's say the IAPP resource was a GenericService resource that was to monitor a Service named IAPP. If you when into the services control panel (start > run > services.msc) and stopped the service manually, the next time the cluster resource performed a monitor cycle (every 60 seconds for most resources), it would see that the resource was no longer online, and you would see the exact error you reported. If this is failing during a failover operation, it appears the resource doesn't go online at first, but failes soon after, otherwise we would see a 'failed to online' error.
I hope this helps and I'll keep an eye out for a new post which additional detail.
Cheers,
rjhanley
Can you start a new thread since this is not related to the issue this post was created for?
Also, can you provide the type of resource the IAPP is? Is it a VMDg, MountV, IP, LanMan, GenericService, etc...?)
If you look in the %VCS_HOME%\log directory, there will be a log file for each resource type: <resource_type>_A.txt (i.e. GenericService_A.txt, IP_A.txt, SQL2005_A.txt, etc..)
Once you determine what type of resource is failing, you can open the proper log file which should also provide more detail as to why the resource failed to online.
The error you are seeing normally occurs when a resource goes offline outside of the cluster. For example, let's say the IAPP resource was a GenericService resource that was to monitor a Service named IAPP. If you when into the services control panel (start > run > services.msc) and stopped the service manually, the next time the cluster resource performed a monitor cycle (every 60 seconds for most resources), it would see that the resource was no longer online, and you would see the exact error you reported. If this is failing during a failover operation, it appears the resource doesn't go online at first, but failes soon after, otherwise we would see a 'failed to online' error.
I hope this helps and I'll keep an eye out for a new post which additional detail.
Cheers,
rjhanley
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-09-2009 12:26 AM
Dear Sorry for late reply.
The IAPP is a third party appication which is running on a Virtiual IP, using Physical interfaces of the both nodes individually.
Cluster service is created on the nodes , to manage failover in case one node goes down other node can keep the application running on the other node.
Best Regards,
aamir
The IAPP is a third party appication which is running on a Virtiual IP, using Physical interfaces of the both nodes individually.
Cluster service is created on the nodes , to manage failover in case one node goes down other node can keep the application running on the other node.
Best Regards,
aamir
Related Content
- Query about ICMP in GCO in Cluster Server
- Listener failed in Storage and Clustering
- Is it possible to have a Critical and Non-Critical application resource in the same service group in Cluster Server
- Unable to ONLINE a service group after disbling the application resource in Cluster Server
- VCS WARNING V-16-10031-8503 NotifierMngr:notifier:monitor:Expected correct SNMP and | or SMTP options in ApplicationHA
