- VOX
- Compliance
- Enterprise Vault
- Enterprise Vault 9.0.5 and Event ID 41008
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Enterprise Vault 9.0.5 and Event ID 41008
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-25-2014 02:58 AM
Hi,
I'm trying to get a better understanding of Event ID 41008 and my backups and I'd appreciate any assistance.
We previously had a very large number reported in Event 41008, I have been working with the backup teams and managed to get the number down significantly.
I have now hit a wall and cannot get the last remaining items cleared, for 1 of the stores I see the below:
- Event ID 41008 reports around 1.8 million items.
- "select COUNT(*) from WatchFile" returns the same number (1.8 million).
- "select COUNT(*) from WatchFile where ItemSecured = '0'" returns 0 items.
Is something missing from my backups?
Checking the archive attribute is impractical due to the volume of files, is there a way I can identify files to check manually?
(FYI we don't use shortcuts so this is not impacting colleagues)
Thanks,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-25-2014 07:58 AM
1. it could actually be a sql issue: http://www.symantec.com/business/support/index?page=content&id=TECH64477
2. if you're using NBU http://www.symantec.com/business/support/index?page=content&id=TECH190067
3. If you're certain all the files have been backed up and there's an attribute issue, you can use a .bat file with the attrib *.* /s
4. if you're using a trigger file http://www.symantec.com/business/support/index?page=content&id=TECH35610
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-26-2014 03:15 AM
Thanks for your reponse Andrew.
Point 1, the third query in the link about the size of the JournalArchive table, the result was 0. What does this mean?
My SQL maintenance plan (Shrink, Rebuild, Update Statistics) are running successfully on a weekly basis.
Point 2, not NBU.
Point 3, as I mentioned this is impractical as I have 13 x 2TB closed partiotions, each containing about 50 million items. Running attrib commands take a significant amount of time and impacts the server performance. I believe the backups has completed, from the database is there a way to narrow down which folders to check?
My open partitions are all hosted on Hitachi HCP streamer WORM devices.
Point 4, no trigger files, we use the archive bit check.
Some more detail:
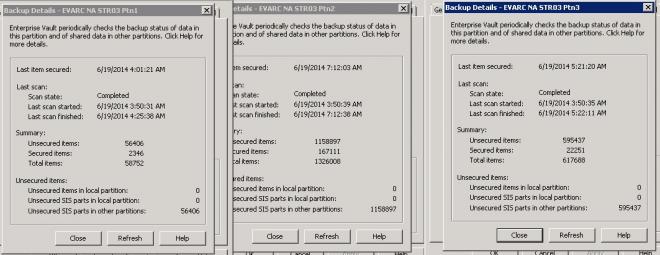
My 3rd Vault Store reports 306,734 in the 41008 event, this is matched in the WatchFile table. Looking at the partition properties I see the below, all the items are coming from "Unsecured SIS parts in other partitions" does this point to an issue with securing files from my HCP storage?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-26-2014 04:46 AM
Its possible that it's associated with ET3334299 - Expired records accumulated in the journal tables in vault store databases
Although its an EV10 issue, it could exist in 9 SP5
Basically there was a change made where it would only purge 10,000 records at a time, the issue was that it did it once per day, as opposed to continuously until the table was cleared.
Its fixed in Enterprise Vault 10 SP4 CHF3
http://www.symantec.com/business/support/index?page=content&id=TECH215093
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-26-2014 04:54 AM
Thanks for your response JesusWept3
Currently we don't do any expiry. Also we started in January with 100+ million items in the event 41008/WatchFile database and these have cleared down to the current 1 million mark, this would be more like 1 million a day rather than 10,000.
Could the ETrack still be relevant?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-26-2014 05:10 AM
A further question on this.
Looking deeper into 1 of the 3 stores. There are 306,939 items in Event 41008 and in the WatchFile database.
I've filtered on ItemName and removed the HCP hosted data (different question) to exclude them.
This leaves 79,533 items in the WatchFile database, all from my NTFS storage, all have ItemSecured = 1 and I have checked a few of the files and the archive bit is not set.
The question is should these clear down with a restart of the Storage service or set/remove backup mode?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-02-2014 06:11 AM
I've been able to dedicate some time to this and have completed numerous service restarts. Further information in case anyone can add anything else to this.
Running the below queries:
select count(*) from WatchFile
select count(*) from JournalArchive where BackupComplete = '0'
returns ~68,000 and ~130,000 respectively.
I have looked up a number of the files referenced by the SaveSetID and can see that the archive bits are cleared.
Questions:
Why are these not being marked as BackupComplete = '1'?
Is there anything I can do to "fix" this?
Again any help is greatly appreciated.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-02-2014 09:23 AM
if you're completely 100% certain that it's been backed up, and you're asking for a "fix" i suppose what you could do is:
1. put ev in backup mode or stop ev services
2. take a full backup of your EV sql databases
3. update the suspect records in the table to reflect BackupComplete=1
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-03-2014 08:11 AM
Thanks AndrewB,
Not really looking for a workaround, more what could have happened, why the disparity or the process/mechanisms of how these files are identified.
I'll keep working on it.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-03-2014 08:58 AM
perhaps you could try and analyze a dtrace of the storage service while restarting it
- Issue after March 2024 Exchange Server Security Updates in Enterprise Vault
- Enterprise Vault indexing grouping in Enterprise Vault
- EV and SQL change port with name pipes disable in Enterprise Vault
- Veeam Backup 11a and Enterprise Vault 14.1 in Enterprise Vault
- Enterprise Vault many 6578 event errors in Enterprise Vault
