- VOX
- Compliance
- Enterprise Vault
- Re: MBX Archiving task hangs
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
MBX Archiving task hangs
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-26-2016 12:04 AM
Hello,
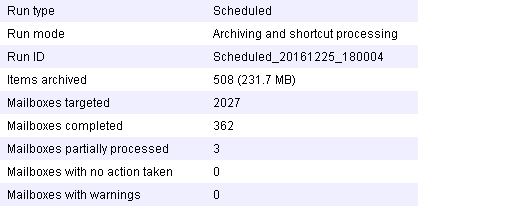
We have a strange issue with archiving tasks. We have 4 PRD Exchange servers and MBX archiving tasks for them. Scheduled tasks, Run Now and Sync of all mailboxes work properly only for the first one, but when it launches by Schedule or I do it manually for other 3 server- nothing happens, it means that I can't see event logs 3442\3448 that the task has started to work and finished, also no new running archiving reports and no Sync of mailboxes. We can see that previous task is working, as you can see on screenshot the task is working since yesterday, but nothing happens inside it, no progress since yesterday. Also, there is no any critical or error Event logs, it means that the task just hangs. Restarting of archiving tasks doesn't help, one time, setting backup mode and clearing backup mode helped to finish activing task without a progress, but the next scheduled task hanged again.
At the same time we can easily enable\disable users, check user archves from affected servers. The same issue was beetwen 16.12.2016 and 20.12.2016, the EV server was restarted and the issue has been fixed for 2-3 days. Could you clarify what is the best way to determine the root cause of the issue? Thx.
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-28-2016 09:51 AM
Hi!
From Screenshot 2 it looks you have a ressource issue.
Could be database fragmentation issue if you see warnings regarding this in monitoring.
Could also a issue with MAPI-Profiles.
You have to check the monitoring and EV Eventlog for Warnings and Errors.
KR
https://twitter.com/pmcs_ev
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-29-2016 02:28 PM
Hello,
I've already raised a ticket to Veritas, because it's a quite urgent issue for our customer. Veritas technician found out that the issue related to our Leaver process- we disable AD account and mailbox for the user before items clean from Pending items, Ev tries to reach the item multiple time on mailbox server, fails multiple time and Private queues cleaning is gettings stucked for each task. The issue might be related to DS server as well, we set in registry our CAS array to prevent failing in archiving tasks. The situation is better now, but it's necessary to handle queues for 2-3 previous weeks when the issue has started.
- MBX Archiving task hangs in Enterprise Vault
- EV FSA 11.0.1 CHF5 File Shares Hanging. in Enterprise Vault
- The EVConverterSandbox has high CPU - Full disk in Enterprise Vault
- Exchange Vault Store Reporting, hang and nothing happens in Enterprise Vault
- Enterprise Vault 10 SQL server crashed in Enterprise Vault
