- VOX
- Compliance
- Enterprise Vault
- Re: Odd Indexer-Service behaviour - slow accelerat...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Odd Indexer-Service behaviour - slow accelerator search
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-07-2016 03:33 AM
Hi All,
I am seeing some really odd behaviour on a journal archiving server with local Indexing.
First off, we are running 10.0.4 with both discovery and compliance accelerator. I haeva project in the pipeline to offload the indexing to an indexing group as there is a huge demand for search performance.
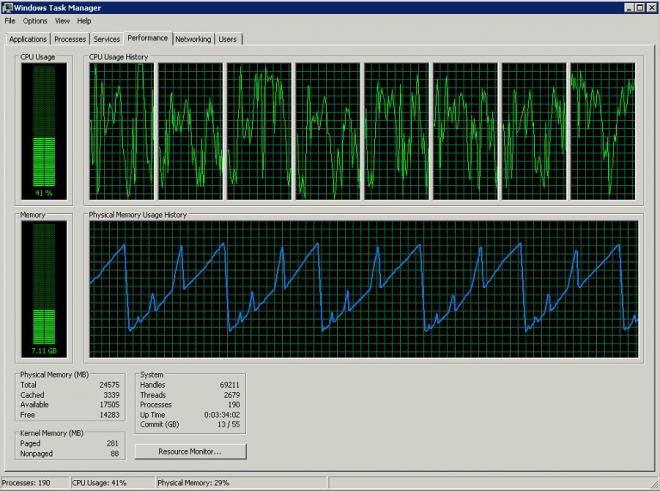
What I am seeing is an indexer-service process progressivley eat up memory until it reaches arounf 16GB then just dump out and start again. Other indexer-service processes seem to just sit there and do nothing.
I've runa DTRACE on various index processes but no luck on identifying the issue.
Any ideas?
Cheers
Guy
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-07-2016 07:40 AM
can you quantify the issue for us and include details about all the variables in your environment?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-07-2016 07:47 AM
What's the Pagefile size on the server hosting the index? Is it on a seperate drive other than C? It shoud be configured atleast one a half times the size of the server RAM.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-07-2016 08:12 AM
Hi All,
RAM is 24GB - Pagefile 32GB.
8 CPU Cores.
Essentially what we are seeing is extremely poor performance on discovery and compliance searches. Often the server runs out of virtual memory and the services halt.
I have noted that on a regular bases there is this cycling of the indexer-service.exe process where it generates the memory profile in the screen shot.
There are some known issues with the architecture which I am here to resolve, namely:
The index locations are local to the servers. all archiving servers are virtual and on the SAME datastores, alongside the index locations, MSMQ and Cache directories. Pagefile is on another drive, but still on the same datastore.
I am planning on offloading the indexing to a set of dedicated indexing servers in an indexing group attached to a Netapp, which should definiately resolve the performance issues, but in the short term (budgetry constarints, lead times, sign off etc are causing delays... it doesn't stop the compliance team screaming at directors though) I need to resolve the issues that I am seeing.
None of the dtraces I have run seem to ID the issue, and I have actually not been able to find the PID's for the odd proccessing in the logs.
So any ideas at all, super welcome!
thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-07-2016 08:19 AM
Hi,
I recently worked on a issue similar to this. We followed the steps in this article to tune EV, CA, and DA to best practices. Scroll all the way to the bottom (CA and DA tuning section)
https://www.veritas.com/support/en_US/article.000080852
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-07-2016 09:02 AM
Hi JimmyNeutron,
Thank you for that, however that is the first article I followed on arrival... :)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-07-2016 10:31 AM
Then its not Enterprise Vault... You might need to start looking at the OS side of things
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-07-2016 11:08 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-08-2016 01:42 AM
Hi All,
So yesterday I upgraded the RAM to 32GB - keeping the 32GB pagefile for the moment. Performance on the searches did improve, however I am still hitting 100 Usage on the odd occasion and during the scheduled Compliance Scans (19 of them) this morning, the services shut down again from lack of virtual memory.
I am going to double the pagefile and run some perfmons over night to monitor resource usage.
Additional background: The Journaling server has its own Datastore on a 3PAR SAN. All Drives, including the index locations are on the same datastore.
I have approached the storage team who have told me from their stats, the storage is fine. Average latency is 3ms.
As mentioned earlier, I am offloading the Indexing to a dedicated index group (2 x HP BL460 G9's) with Netapp storage. The business is actually considering Flash trays as well.
My main concern though is the memory profile I posted in the original post that seems to cycle on a scheduled bases 2 or 3 times a day that I've seen, but not aligned with any schedules I can find (Archiving, Indexing, Sync etc)... although it is most definately the indexer-service causing this. There are NO searches running at the time either.
Any input or thoughts regarding how to identify what is actually going on with this server?
- Trying to export out to PST Archived mail but not working. Application is Enterprise Vault in Enterprise Vault
- Custodian manager - Standalone POC in Enterprise Vault
- Include attachments in powershell Export-EVArchive in Enterprise Vault
- Discovery Accelerator exports.... .msg vs .eml in Enterprise Vault
- DiskMap regkey not working correctly in Enterprise Vault
