- VOX
- Data Protection
- NetBackup
- AIR error 84 during Replication,status 191
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
AIR error 84 during Replication,status 191
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-20-2019 01:06 AM
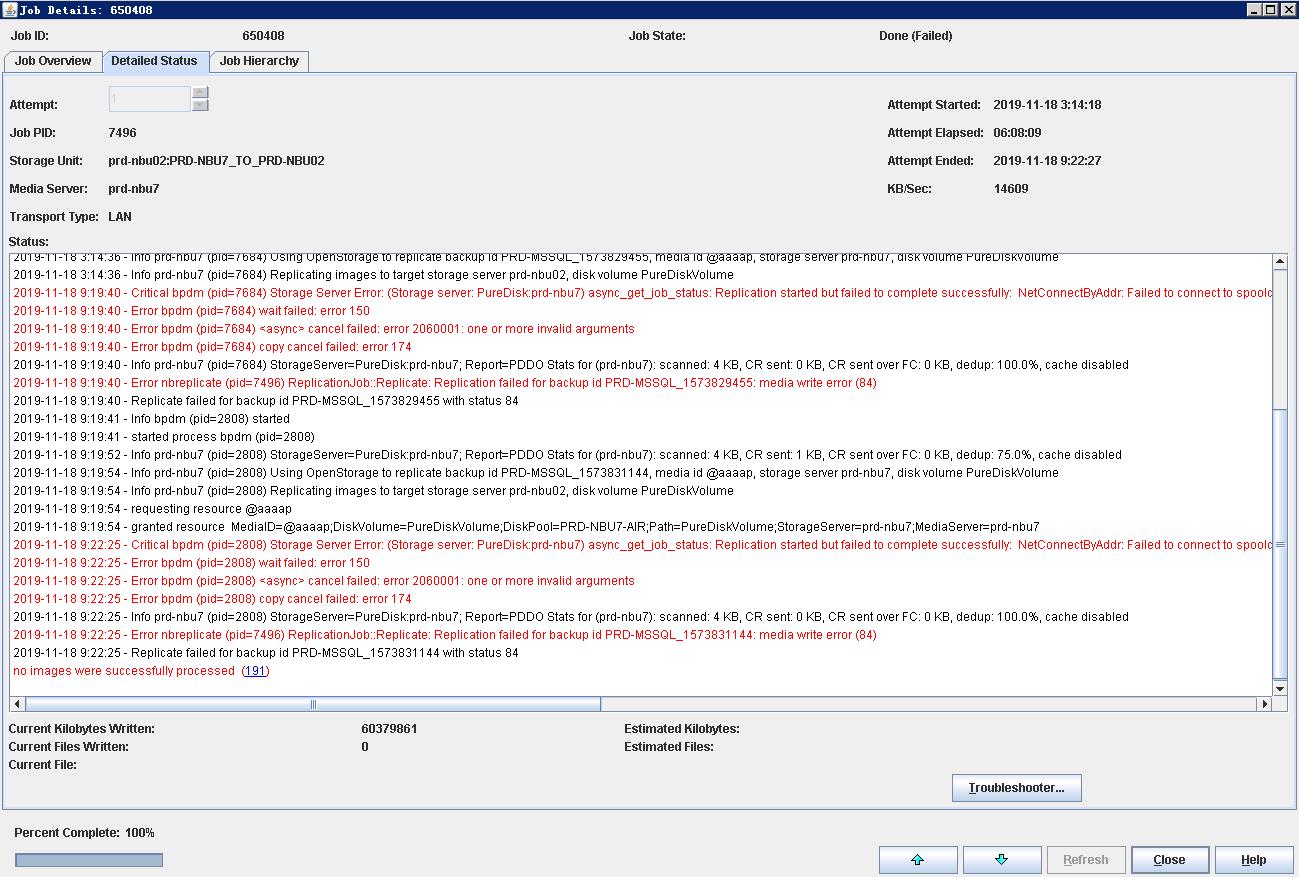
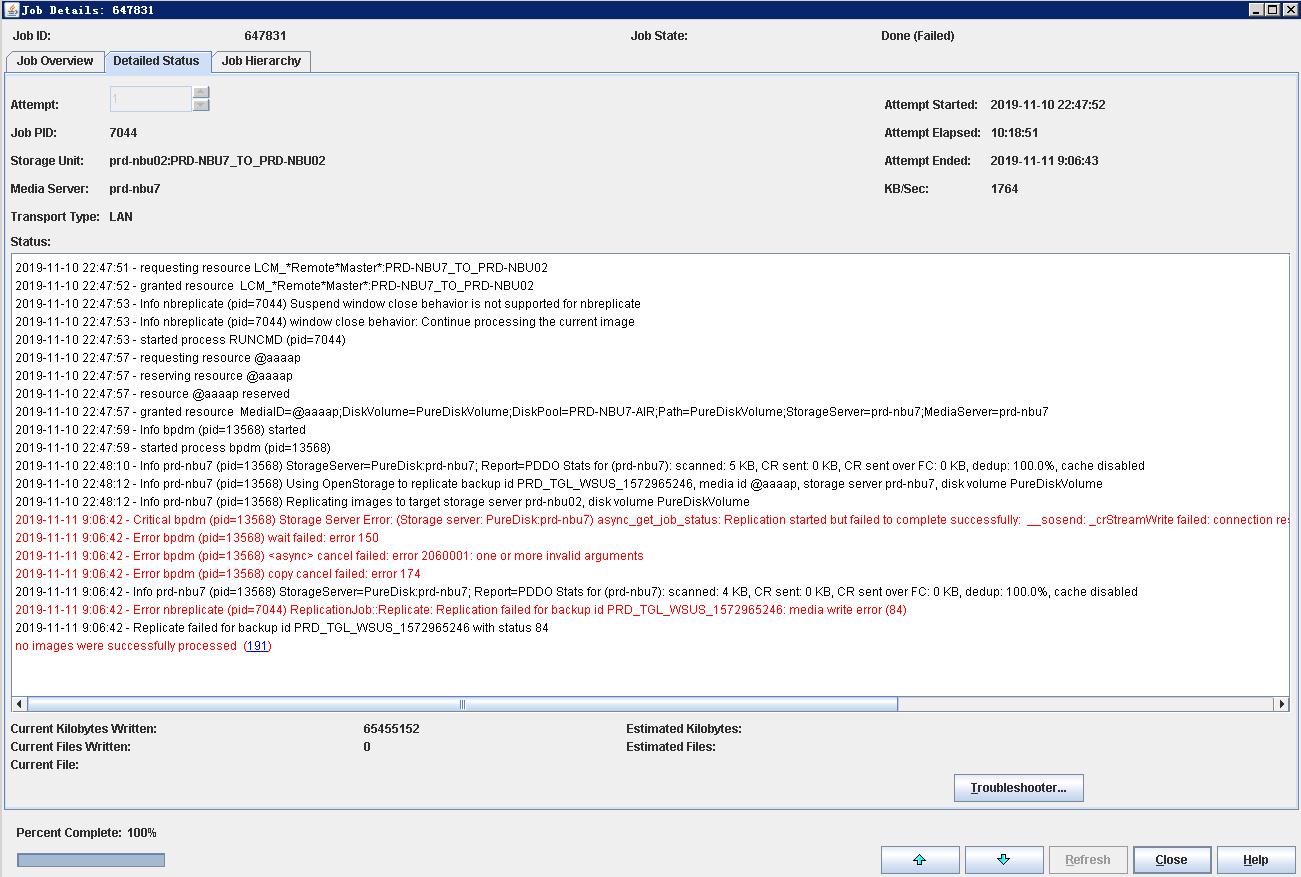
I have some issues with AIR. OS isWindows 2008 R2and Windows 2012,NBU version is 7.7.3 .AIR will error,status 191.Please check the attached details.Please help me.Thank you.
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-20-2019 02:42 AM
It's right there in the error message. Did you verify the comms?
Replication started but failed to complete successfully: NetConnectByAddr: Failed to connect to spoold on port 10082 using the following interface(s): [ 10.205.8.10 ]
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-20-2019 11:17 PM
Thank you for you help. I use the command Telnet test is normal access.Port 10082 is normal access.
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-20-2019 11:42 PM
hello,
Did you test that in bidirectional?
BR.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-21-2019 12:59 AM
Yes.I did a bidirectional test.Port 10082 normal.Have some job can AIR.But some job can't AIR.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-21-2019 02:37 AM
Hello,
please check if spoold is running on the media server i guess prd-nbu7?
a restart of nbu services won't hurt (check with bpps to confirm that all the services are stopped before starting them back, if some are haning, kill them..)
the other AIR that are running, are there from/to the same media servers?
also, check logs: bpdm logs spad, spoold, storage.d replication ..
BR
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-21-2019 06:28 PM
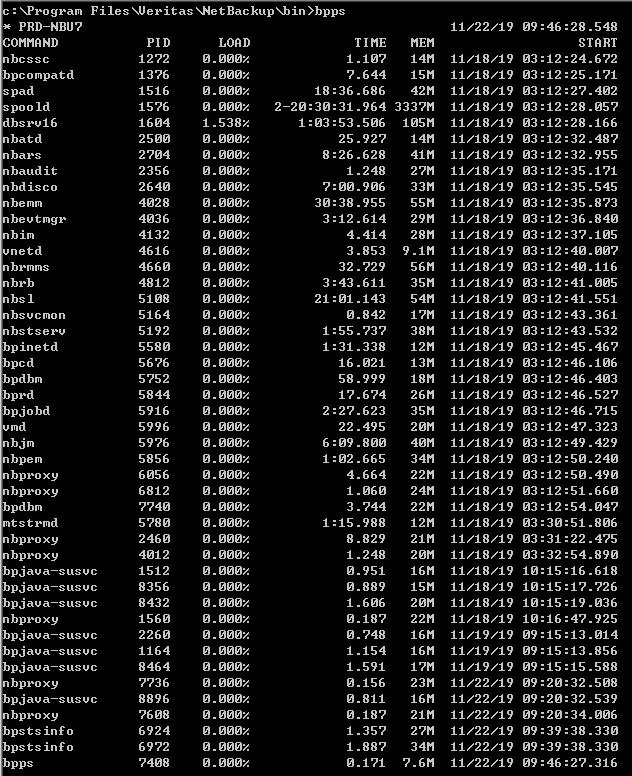
Hello,
I check PRD-NBU7 and PRD-NBU02 spooId is running.
I already use "bpdown" command kill nbu services and "bpup" command restart nbu services.
Please check the attached details.
I check Two Master not has same media servers.
You tell me check logs.I not found logs location.Thank you!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-22-2019 01:50 AM - edited 11-22-2019 05:07 AM
Hello,
as per the detailled status, it is clear said :
__sosend: _crStreamWrite failed: connection reset by peer. Look at the replication logs on the source storage server for more information.
Then to find the replications logs:
https://www.veritas.com/content/support/en_US/doc/25074086-127355784-0/v95643184-127355784
On the media server which is the prd-nbu7 (which in ur case also the master) , navigate to : /storage_path/log/spad/replication.log
Log files in the storage_path/log/spoold directory, as follows:
The spoold.log file is the main log file
The storaged.log file is for queue processing.
The log files are in the /storage_path/log/spad directory, as follows:
spad.log
**edit** : bpdm log is on the master Media (my bad I thought it was bpdbm): (which is prd-nbu7) install_path\veritas\netbackup\logs (if the folder doesn't exist, create it) , then go to the media server's properties on the administration console and select logging > bpdm > verbosity level(3)
Then send these logs after that the replication jobs fails.
BR.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-22-2019 02:09 AM
bpdm and bptm log folders must be created on the source and destination media servers.
The log folders do not exist by default.
Please increase logging level on media servers to 3 for bpdm and bptm processes.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-25-2019 06:47 PM
Hello,
Thank you for your help! I'll follow your instructions.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-25-2019 06:50 PM
Thank you for your help! I check to see if the relevant path exists and create it
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-03-2019 07:06 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-04-2019 07:34 PM
Hello,I found the logs file.But I can't found the spad.log.And I can't read these logs.I think this problem is very difficult.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-05-2019 08:27 AM - edited 12-05-2019 08:31 AM
You might need to include your network team in troubleshooting this.
spad logs would help, please look here. Replication session logs from the target (/log/spoold/<source_master>/spad/Store)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-05-2019 09:13 AM - edited 12-05-2019 11:01 AM
@paultang - hey Paul - I had the same errors and same symptoms as you, and for me it turned out that the problem was a failing / flapping network switch port on one of four 1Gb bonded cross-site WAN pipes. This customer had four NetBackup domains, configured as two pairs :
NBU setup 1 :
one 5230 v2.7.3 Master/Media at site A one 5230 v2.7.3 Master/Media at site B
.
NBU setup 2 :
one Win 2016 Master v8.1.1 at site A one Win 2016 Master v8.1.1 at site B
one 5240 v3.1.1 Media at site A one 5340 v3.1.1 Media at site B
.
Both NBU setups were using the very same cross-site WAN links for their NetBackup AIR replication, but only the first older v2.7.3 environments were affected, in both directions, by the failing flapping network switch port. As soon as the faulty network switch port was closed then NetBackup AIR replication was ok again.
.
So I suspect that your problem is a network related issue of some sort.
A very typical problem is that network switches close down TCP conversations that the switches think have failed / timed-out / gone-idle, so the typical solution is to implement longer TCP keep alives.
.
It was never clear to me why the v8.1.1 / v3.1.1 pair of NBU setup 2 was not affected, but I think that was either down to src-mac/dst-mac bonding algo, or more likely was different routing meant that the newer NetBackup environment traffic was routed via one / two of the WAN links that did not have the faulty network switch port.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-07-2019 06:53 AM
Are you using jumbo frames for replication?
It might be worth making sure that there isn't anywhere on the network where the MTU is configured to an unsuitable value
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-08-2019 01:49 PM - edited 12-08-2019 01:50 PM
@CadenL makes a very good point... which I will attempt briefly to expand upon... in my travels I've seen weird behaviour on networks when even tunnelling affects MTU by say 20 bytes. Anyway, not all jumbo devices (and that means A and B end - i.e. TCP stacks on servers (V or P) and TCP stacks in actual physical network switches) support the same max size... e.g. some switches allow / support 9500 byte jumbo frames, whereas some only allow / suppory say 9100 byte jumbo frames... and so... if all points / sides / ends are not configured with the "correct size" (which does not necessarily mean the "same size" when tunnelling or encapsulated) - did you get that ? "same size" does not neccessarily imply "correct size"... well, if all is not of "correct size" along all hops... then, well... expect bad transfers = expect bad backups.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-10-2019 11:21 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-10-2019 11:27 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-10-2019 11:30 PM
- Final error: 0xe00095a7 - The operation failed because the vCenter or ESX server reported that the in Backup Exec
- Oracle to Netbackup Copilot in NetBackup
- Problem BackupExec 21 After Crash in Backup Exec
- Duplicating tapes fails: INF - Cannot obtain resources for this job : error [167] in NetBackup
- Disk storage unit is full, but it's not full (netbackup 10.1.1) in NetBackup
