- VOX
- Data Protection
- NetBackup
- Netbackup 5.1 - duplicate backup running longer / ...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-28-2015 02:39 PM
Hi there,
I am after some advice for an old Veritas NB 5.1 version running on HP-UX and would appreciate some help and guidance please.
Just to clarify, i understand that this version is extremely old and unsupported but unfortunately, there is no appetite from the decision makers to allow for an upgrade as the servers this NB solution supports are due to go out of support by the end of this year we are told. But i digress.....
So, we have an overnight backup that completed, and then from 8am each day, we take duplicates of the overnight backups, to be sent offsite for offsite storage.
Typically, the "duplicate" run from 08:00 till approx 17:00 each day but a few days ago, the backup was only showing as being approx 50% completed by 22:30 so i cancelled it. We have seen a few of these delays recently but we are unable to spot any pattern so suspect technical difficulties somewhere in the backup solution. Data volumes have not increased - by and large they are stable
I have saved the following files from the server but frankly i'm not overly NB familiar so the contents mean little, although i have search for errors but can't seem to find anything of relevance :
admin / bpbkar / bpbrm / bpcd / bplist / bprd / bpsched / bptm / hp-ux syslog
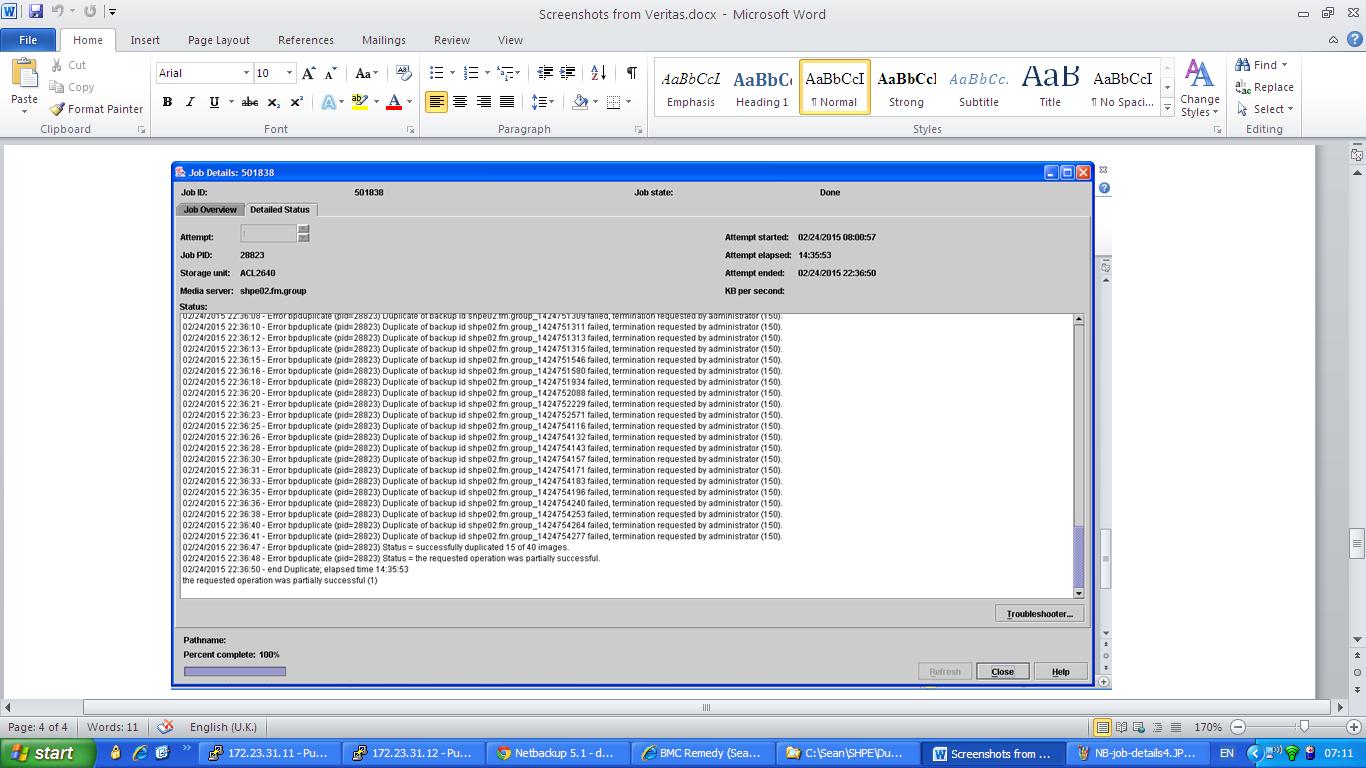
Also, i have saved screen shots from the Veritas NB job details which i have attached to this post which *seemed* to show no activity or stalling between 10:19:09 and 17:32:50
Would someone be able to give me some guidance as to what might be the issue please or some guidance as to any *classic* or *typical* things to check for and in which of the logfiles
Am happy to share any further logs or system config which may be of use and help get to the bottom of this.
Many thanks in advance
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-17-2015 08:21 AM
Marianne is correct, few servers have the ability to push enough data to more than a couple of tape drives at once.
Streaming data to a tape drive requires a minimum of about 40 megabytes a second (check with your tape drive vendor for minimum streaming speeds). Anything less than that minimum will cause the tape drive to "shoe shine", constantly stopping, rewinding, and starting again, wearing out the tapes and drives and slowing your backup speeds.
Most servers generally have a maximum that they can send data across all the various buses (memory, chipsets, PCI, etc.), and they rarely reach that maximum for a sustained amount of time due to various factors like CPU, swapping to disk, deduplication, etc.
While the server, OS, and NetBackup might let you add more tape drives, that doesn't mean they can all run at maximum speed, or even the minimum streaming speeds. If your backups are writing to tape at less than about 40MB/sec, you are likely over-allocating tape drives to a server. Add another media server and split the tape drives amongst them, then see how quickly your backup window shrinks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-28-2015 03:08 PM
Few of us will open .docx files.
Can't you post screen shots in here?
If you look in the log files you'll strings in a certain place that look like <2> or <4> or <8>... these can be useful...
So, if you grep for "\<16\>" - this will show you errors.
Here's the list:
<32> critical
<16> error
<8> warning
<4> info
<2> info
Try grep'ing for the first three, i.e. critical, error and warning. Anything obvious?
Any idea how long the system has been up? How long NetBackup has been up?
Free RAM ok? Swap file not heavily used?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-28-2015 08:08 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-28-2015 11:25 PM
logfiles in zip format
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-28-2015 11:29 PM
NB job screenshots
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-28-2015 11:30 PM
thanks for both of the replies and support
bp.conf just shows "VERBOSE" with no numeric parameter and to change it will need me to raise change control so i cant do that immediately
log files uploaded in a zip file
netbackup has been running since jan 5th 2015 when the NB master server was last rebooted
jpegs attached showing screenshot of overview page for job in NB, followed by detailed also, before job was eventually cancelled around 22:30
i will do some searches for the error messages advised later today
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-28-2015 11:31 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-02-2015 01:13 AM
Any chance of bptm as well ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-02-2015 01:16 AM
Sorry Marianne - only just seen your reply - apologies but they are pretty large
Here are the files in text format
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-02-2015 01:18 AM
All files uploaded in txt format....
admin / bpbkar / bpbrm / bpcd / bplist / bprd / bpsched / bptm
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-02-2015 02:05 AM
The problem with an unsupported version of sofware is that finding assistance is very difficult.
All of us trying to assist on Connect are doing so in our own time, and sifting through anything higher than level 1 logs is extremely time consuming.
Symantec Support always insists on level 5 logs as low level logs (level 1 in your case) does not give enough info.
Catch 22 - we don't have time or expertise to analize level 5 logs and you don't have support for your software.
I managed to download the zip-file this morning.
During duplication we only need admin, bptm and bpbrm on the media server.
We can see that duplication was slowly ticking along, and then 'nothing' happened between 10:19 and 17:32.
Just that fragment read and write started at 10:19 and finished at 17:32.
LOTS of entries in admin log like these that just say another MPX cannot start because not all streams in current MPX group have completed duplication (3 out of 4 streams still active) :
10:19:46.187 [28823] <2> start_indep_grp: active_mpx_groups:1, active_backups:3, Not starting 10:19:46.187 [28823] <2> next_active_mpx_group: 40017a60: bptm_pid:0 10:19:46.187 [28823] <2> next_active_mpx_group: 40017aa0: bptm_pid:0 10:19:46.187 [28823] <2> next_active_mpx_group: 40017ae0: bptm_pid:0 10:19:46.187 [28823] <2> next_active_mpx_group: 40017a20: bptm_pid:28853 10:19:46.187 [28823] <2> mon_mm: called by mpxdup
We actually see a slow-down after 09:39 where this fragment took 40 minutes to duplicate as opposed to the previous ones that took a couple of seconds:
09:38:41.297 [28853] <2> io_position_for_read: positioning DXL052 to file number 43
09:39:16.909 [28853] <2> io_position_for_read: positioning DXL052 to file number 44
09:39:43.343 [28853] <2> io_position_for_read: positioning DXL052 to file number 45
10:19:09.203 [28853] <2> io_position_for_read: positioning DXL052 to file number 46
All I can suggest is that you check what is happening at OS-level when you see no updates for more than 15 minutes.
Check process table, memory usage, IO stats, etc...
It seems to me that something outside of NBU is causing the slow-down/hang.
If your NBU server has sufficient physical resources to stream the amount of drives attached to it (looks like 6???) and sufficient memory and shared memory, you can look at buffer tuning.
In all honesty I have seen very little backup servers being able to stream more than 2 or 3 tape drives.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-02-2015 02:53 AM
I've seen dirty LTO tape drives - not fail - but really slow down.
Cleaned them, and speed back to normal.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-02-2015 06:27 AM
Hi Marianne - fully understand and agree with your comments but unfortunately, we are unlikely to be moving onto a fully supported version of NB.
Regarding to moving to level 5, presumably this will produce more detailed/granular output and if so, are you able to advise just how much more (approximately) it would produce as this system isn't blessed with a huge amount of space either. Just your feeling/thoughts.
Regarding overall system performance, i am not aware of any issues but would have to check back through the performance stats to see anything relevant but as i say, i am not aware of any and all this system does is run VNB and is part of a HP ServiceGuard cluster.
You are correct - yes the attached ATL (Sun L180) has 6 drives
@sdo - thanks for your reply also. Do you see anything implicating potentially dirty tapes drives ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-02-2015 08:16 AM
Sean - I've not seen any specific which warrants cleaning the drives, so I don't mean to send you on a wild goose chase, but stable old environments really shouldn't start exhibiting behaviour like this. Have there really been no changes at any private/discreet (to this backup environment) or shared infrastructure layer? Really, none at all?
Why not rule out dirty tape drives for the sake of $100 for two cleaning tapes - and about half a man day effort arranging for old cleaning media to be ejected and replaced - and then perform a manual tape drive clean.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-02-2015 09:22 AM
sdo - "Have there really been no changes at any private/discreet (to this backup environment) or shared infrastructure layer? Really, none at all?"
not to my knowledge no
the ATL was swapped from an old quantum 2640 to an L180 back last year but for a long time, everything was running well.....occassional drive issues that were flagged in HP-UX, drives cleaned / up'ed and away we go again...what i would class as normal behaviour and the occassional drive replacements if we start seeing frequent read/write errors
before we clean any drives, we typicall wait for the HP-UX resmon errors
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-03-2015 06:15 AM
" before we clean any drives, we typicall wait for the HP-UX resmon errors "
I wonder if this is maybe what is causing the slow down or 'hang'...
Extract from NBU Device Config Guide (The oldest version I have is for NBU 6.5, but I remember the same requirement in NBU 5.x and earlier):
Cautions for the HP-UX EMS Tape Device Monitor
This topic is a NetBackup Enterprise Server topic. You should configure the Tape Device Monitor (dm_stape) so it does not run on HP-UX hosts in a SAN configuration. The Tape Device Monitor is a component of the Event Monitoring System (EMS). The EMS service periodically polls the tape devices to monitor their conditions. When a server polls the devices while another server uses a tape device, backup operations may time out and fail.
You can avoid the situation in either of the following ways:
■ To disable EMS completely, run the HP-UX Hardware Monitoring Request Manager and select (K)kill (disable) Monitoring.
Invoke the Hardware Monitoring Request Manager by using the /etc/opt/resmon/lbin/monconfig command.
■ To configure EMS so it does not log any events or poll devices, set the POLL_INTERVAL value to 0 (zero). The POLL_INTERVAL parameter is in the following HP-UX configuration file:
/var/stm/config/tools/monitor/dm_stape.cfg
EMS runs but does not send any SCSI commands.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-10-2015 02:37 AM
Hi Marianne,
Thanks for your reply and apologies for the delay in responding.
I will have a read up on what you have shared but could that prevent the same EMS from monitoring internal tape drives, that are used to create boot tapes ?
In your experience, with an environment as old as this, is there a rule of thumb to follow for cleaning drives on an L180 ? Should they be cleaned on a regular cycle and not wait for EMS to flag ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-10-2015 03:16 AM
I have ALWAYS followed the instructions in Device Config manual religiously - as from my very 1st encounter ever with HP-UX back in NBU 3.1 days. (I used to be a Solaris sys-admin in a 'previous life'.)
Following the manual to disable EMS and to disabling SPC-2 SCSI reserve has always worked for me.
Device cleaning should be done by the robot itself (cleaning tapes in the special cleaning slots in STK robot), or else with NBU controlling the cleaning via TapeAlert and cleaning tapes in 'normal' slots.
O-L-D TNs (created back in NBU 3.4 days) that explains how to do this from NBU:
http://www.symantec.com/docs/TECH8452
http://www.symantec.com/docs/TECH19399
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-17-2015 02:21 AM
thanks Marianne - i will take a look at the shared docs
just checked, and the POLL_INTERVAL is indeed set to 0
Marianne...i did mean to ask, are you able to explain what you mean by the following statement you made please :
"In all honesty I have seen very little backup servers being able to stream more than 2 or 3 tape drives."
Is that an actual limitation then, or purely down to the resource that the HP-UX server has to go at, preventing it streaming to 2 or 3 drives (max) at any one time, even though device monitor will let all 6 drives on the face of it, be populated and performing backups ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-17-2015 08:21 AM
Marianne is correct, few servers have the ability to push enough data to more than a couple of tape drives at once.
Streaming data to a tape drive requires a minimum of about 40 megabytes a second (check with your tape drive vendor for minimum streaming speeds). Anything less than that minimum will cause the tape drive to "shoe shine", constantly stopping, rewinding, and starting again, wearing out the tapes and drives and slowing your backup speeds.
Most servers generally have a maximum that they can send data across all the various buses (memory, chipsets, PCI, etc.), and they rarely reach that maximum for a sustained amount of time due to various factors like CPU, swapping to disk, deduplication, etc.
While the server, OS, and NetBackup might let you add more tape drives, that doesn't mean they can all run at maximum speed, or even the minimum streaming speeds. If your backups are writing to tape at less than about 40MB/sec, you are likely over-allocating tape drives to a server. Add another media server and split the tape drives amongst them, then see how quickly your backup window shrinks.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}