- VOX
- Data Protection
- NetBackup
- Random Error 636 on a specific SAP backup client w...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Random Error 636 on a specific SAP backup client windows - media linux
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-20-2014 12:50 AM
Good morning all,
recently i'm facing a strange issue, it is strange because at the end of the day backup the SAP FULL DB is completed well, but on the NetBackup Admin console i continue to see error 636.
This backup run every day, but, errors is random, twice or more a week, not for specific days:
5/20/2014 3:52:34 AM - Info bpbrm(pid=26401) vm767502.ams20.vzbi.caas is the host to backup data from
5/20/2014 3:52:34 AM - Info bpbrm(pid=26401) reading file list from client
5/20/2014 3:52:36 AM - Info bpbrm(pid=26401) starting bphdb on client
5/20/2014 3:52:37 AM - Info bphdb(pid=1992) Backup started
5/20/2014 4:00:00 AM - Info nbjm(pid=7131) starting backup job (jobid=439982) for client vm767502.ams20.vzbi.caas, policy MNG_AMS20_SAP_DW2_DMZ, schedule DAILY_FULL_SAP_DB
5/20/2014 4:00:00 AM - Info nbjm(pid=7131) requesting MEDIA_SERVER_WITH_ATTRIBUTES resources from RB for backup job (jobid=439982, request id:{7332B3BA-DFC2-11E3-9FF2-4BBC7D56EE44})
5/20/2014 4:00:00 AM - requesting resource ME-A2_PDSTU
5/20/2014 4:00:00 AM - requesting resource ph469702.ams20.vzbi.caas.NBU_CLIENT.MAXJOBS.vm767502.ams20.vzbi.caas
5/20/2014 4:00:00 AM - requesting resource ph469702.ams20.vzbi.caas.NBU_POLICY.MAXJOBS.MNG_AMS20_SAP_DW2_DMZ
5/20/2014 4:00:00 AM - granted resource ph469702.ams20.vzbi.caas.NBU_CLIENT.MAXJOBS.vm767502.ams20.vzbi.caas
5/20/2014 4:00:00 AM - granted resource ph469702.ams20.vzbi.caas.NBU_POLICY.MAXJOBS.MNG_AMS20_SAP_DW2_DMZ
5/20/2014 4:00:00 AM - granted resource ME-A2_PDSTU
5/20/2014 4:00:00 AM - estimated 0 Kbytes needed
5/20/2014 4:00:00 AM - Info nbjm(pid=7131) started backup (backupid=vm767502.ams20.vzbi.caas_1400551200) job for client vm767502.ams20.vzbi.caas, policy MNG_AMS20_SAP_DW2_DMZ, schedule DAILY_FULL_SAP_DB on storage unit ME-A2_PDSTU
5/20/2014 4:00:01 AM - started process bpbrm (26401)
5/20/2014 4:00:08 AM - connecting
5/20/2014 4:00:10 AM - connected; connect time: 00:00:02
read from input socket failed(636)
On the client (windows 2k8 standard 64bit) i see:
BR0280I BRBACKUP time stamp: 2014-05-20 05.47.05
BR0292I Execution of BRARCHIVE finished with return code 0
The current date is: Tue 05/20/2014
The current time is: 5:47:05.51
-END---------------------
.....
[root@ph469702]/usr/openv/netbackup/bin# /usr/openv/netbackup/bin/admincmd/bppllist MNG_AMS20_SAP_DW2_DMZ -L
Policy Name: MNG_AMS20_SAP_DW2_DMZ
Options: 0x0
template: FALSE
audit_reason: ?
Names: (none)
Policy Type: SAP (17)
Active: yes
Effective date: 08/02/2011 17:47:45
Mult. Data Stream: no
Perform Snapshot Backup: no
Snapshot Method: (none)
Snapshot Method Arguments: (none)
Perform Offhost Backup: no
Backup Copy: 0
Use Data Mover: no
Data Mover Type: 2
Use Alternate Client: no
Alternate Client Name: (none)
Use Virtual Machine: 0
Hyper-V Server Name: (none)
Enable Instant Recovery: no
Policy Priority: 100
Max Jobs/Policy: Unlimited
Disaster Recovery: 0
Collect BMR Info: no
Keyword: (none specified)
Data Classification: -
Residence is Storage Lifecycle Policy: no
Client Encrypt: no
Checkpoint: no
Residence: ME-A2_PDSTU
Volume Pool: DataStore
Server Group: *ANY*
Granular Restore Info: no
Exchange Source attributes: no
Exchange 2010 Preferred Server: (none defined)
Application Discovery: no
Discovery Lifetime: 0 seconds
ASC Application and attributes: (none defined)
Generation: 128
Ignore Client Direct: no
Enable Metadata Indexing: no
Index server name: NULL
Use Accelerator: no
Client/HW/OS/Pri/DMI: vm767502.ams20.vzbi.caas Windows-x64 Windows2008 0 1 0 0 ?
Include: C:\backup-scripts\backup-online_NetBackup.bat
Schedule: DAILY_FULL_SAP_DB
Type: FULL SSAP (0)
Calendar sched: Enabled
Allowed to retry after run day
........
Maximum MPX: 1
Synthetic: 0
Checksum Change Detection: 0
PFI Recovery: 0
Retention Level: 1 (2 weeks)
u-wind/o/d: 0 0
Incr Type: DELTA (0)
Alt Read Host: (none defined)
Max Frag Size: 0 MB
Number Copies: 1
Fail on Error: 0
Residence: (specific storage unit not required)
Volume Pool: (same as policy volume pool)
Server Group: (same as specified for policy)
Residence is Storage Lifecycle Policy: 0
Schedule indexing: 0
Daily Windows:
Day Open Close W-Open W-Close
......
Schedule: SAP
Type: UBAK SAP (2)
Frequency: 7 day(s) (604800 seconds)
Maximum MPX: 1
Synthetic: 0
Checksum Change Detection: 0
PFI Recovery: 0
Retention Level: 1 (2 weeks)
u-wind/o/d: 0 0
Incr Type: DELTA (0)
Alt Read Host: (none defined)
Max Frag Size: 0 MB
Number Copies: 1
Fail on Error: 0
Residence: (specific storage unit not required)
Volume Pool: (same as policy volume pool)
Server Group: (same as specified for policy)
Residence is Storage Lifecycle Policy: 0
Schedule indexing: 0
Daily Windows:
Day Open Close W-Open W-Close
.....
I wonder if some timeout is wrongly setup for this specific couple of client/media, since they work both into a DMZ zone and only the MASTER is into TRUST zone, with all FIREWALL ACL correctly configured.
It is true because i see other servers working fine, even on the same MEDIA, without any glitches.
I have no idea why it is impacting only this one, and only this DB backup, not even mswindows FULL or INC.
Thank you for any advice.
Regards,
Michele
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-20-2014 07:33 AM
Please post the backint log from the client as a file.
Set CLIENT_READ_TIMEOUT = 1800 on master, media and client
Ensure TCP_KEEP_ALIVE is configured on master, media and client to prevent firewall closing them. Cisco firewall closes inactive session per default after ½ a hour. So configure it to send keep alive packages after 15 minutes.
http://www.symantec.com/docs/TECH125896
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-20-2014 11:49 PM
Hi Nicolai,
thanks for the advices.
But it is already so.
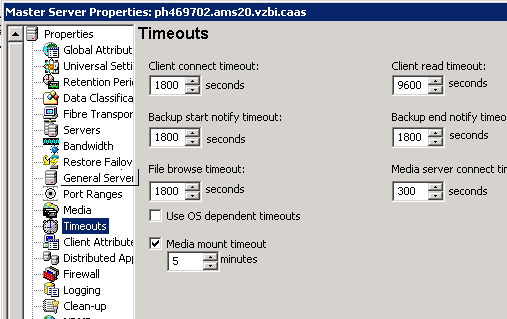
Master CLIENT_READ_TIMEOUT is 9600
Media CLIENT_READ_TIMEOUT is 9600
Client CLIENT_READ_TIMEOUT is 9600
At OS level i have, for both master/media:
net.ipv4..tcp_keepalive_intvl = 75
net.ipv4..tcp_keepalive_probes = 9
net.ipv4..tcp_keepalive_time = 7200
On the client OS is :
KeepAliveTime 90000
Only parameter available.
Attached backint log for the last day (20th May).
Thank you.
Regards,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-21-2014 01:18 AM
I would lower the net.ipv4..tcp_keepalive_time to 840 (14 minutes) on master and media server.
On client I would also lower to 14 minutes.
can you also post the output from SAP brtools and backint when error occur ? I need both for time stamp matching. But indeed it look like a network related issues.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-21-2014 01:26 AM
A read timeout of 9600 is close to 3 hours. Way too long!
I am wondering about Connect timeout. The default is 300 (5 minutes).
There is more than 5 minutes between these 2 entries:
5/20/2014 3:52:37 AM - Info bphdb(pid=1992) Backup started
5/20/2014 4:00:00 AM - Info nbjm(pid=7131) starting backup job (jobid=439982) for client
So, from the time that client received instruction to run the script, is seems that it took more than 7 minutes to actually start.
Although we see Connecting and Connected further down, I think that the Parent job is timing out.
Do you see the same kind of delays on the successful jobs?
Please ensure that Client Connect Timeout is set to at least 900 on Master and Media server.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-21-2014 02:38 AM
Hi all,
for master and media i have all the same timeout settings (attached).
I would also say that MASTER and MEDIA1 is on the trust zone, with the majority of servers, then i have MEDIA2 with 10 servers on the DMZ.
Everything is working fine, all single servers and policies, but this one sporadically is messing up.
Just becasue the backup on the SAP side complete correctly, but the console shows error 636.
Then a succesfull job was today, for instance:
5/21/2014 3:02:29 AM - Info bpbrm(pid=14806) vm767502.ams20.vzbi.caas is the host to backup data from
5/21/2014 3:02:29 AM - Info bpbrm(pid=14806) reading file list from client
5/21/2014 3:02:31 AM - Info bpbrm(pid=14806) starting bphdb on client
5/21/2014 3:02:33 AM - Info bphdb(pid=7716) Backup started
5/21/2014 3:10:00 AM - Info nbjm(pid=7131) starting backup job (jobid=440609) for client
^^^^^^^^^^ higher than 5 minutes too...
vm767502.ams20.vzbi.caas, policy MNG_AMS20_SAP_DW2_DMZ, schedule DAILY_FULL_SAP_DB
5/21/2014 3:10:00 AM - Info nbjm(pid=7131) requesting MEDIA_SERVER_WITH_ATTRIBUTES resources from RB for backup job (jobid=440609, request id:{A18C13B0-E084-11E3-92A9-B6AB3464D66A})
5/21/2014 3:10:00 AM - requesting resource ME-A2_PDSTU
5/21/2014 3:10:00 AM - requesting resource ph469702.ams20.vzbi.caas.NBU_CLIENT.MAXJOBS.vm767502.ams20.vzbi.caas
5/21/2014 3:10:00 AM - requesting resource ph469702.ams20.vzbi.caas.NBU_POLICY.MAXJOBS.MNG_AMS20_SAP_DW2_DMZ
5/21/2014 3:10:00 AM - granted resource ph469702.ams20.vzbi.caas.NBU_CLIENT.MAXJOBS.vm767502.ams20.vzbi.caas
5/21/2014 3:10:00 AM - granted resource ph469702.ams20.vzbi.caas.NBU_POLICY.MAXJOBS.MNG_AMS20_SAP_DW2_DMZ
5/21/2014 3:10:00 AM - granted resource ME-A2_PDSTU
5/21/2014 3:10:00 AM - estimated 0 Kbytes needed
5/21/2014 3:10:00 AM - Info nbjm(pid=7131) started backup (backupid=vm767502.ams20.vzbi.caas_1400634600) job for client vm767502.ams20.vzbi.caas, policy MNG_AMS20_SAP_DW2_DMZ, schedule DAILY_FULL_SAP_DB on storage unit ME-A2_PDSTU
5/21/2014 3:10:02 AM - started process bpbrm (14806)
5/21/2014 3:10:04 AM - connecting
5/21/2014 3:10:06 AM - connected; connect time: 00:00:02
5/21/2014 3:41:55 AM - Info bpbrm(pid=14806) validating image for client vm767502.ams20.vzbi.caas
5/21/2014 3:41:55 AM - Info bphdb(pid=7716) done. status: 0: the requested operation was successfully completed
5/21/2014 3:49:30 AM - end writing
the requested operation was successfully completed(0)
Attached logs from SAP brtools on the server impacted.
Thank you.
Regards,
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-21-2014 03:13 AM
It is difficult to troubleshoot when the problem is intermittent.
The bpbrm log on the media server may help, because the problem seems to be between bpbrm and nbjm.
This TN explains the bpbrm -> nbjm comms: http://www.symantec.com/docs/TECH197144
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-21-2014 04:15 AM
Is any Intrusion prevention system (IPS) active on the firwall ?
It caused issues in this thread : https://www-secure.symantec.com/connect/forums/status-code-40-after-backup-running-15-minutes-everytime
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-22-2014 02:07 AM
No IPS active.
It is not a wide problem for some or all servers, it is only for one, and only for SAP DB, so i believe it is somethign more on the client side, maybe.
Today no errors for instance.
Thank you.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-22-2014 02:20 AM
Really difficult to troubleshoot when the error is intermittent.
Any possibility you can ask Firewall admins to log/monitor connections between master and client as well as media server and client for a couple of days?
bpbrm on the media server should still help as it will log updates received from the client.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-23-2014 12:40 AM
net.ipv4..tcp_keepalive_time = 7200 is to high for preventing firewall to close the TCP session. Lower it and monitor if the problem has gone.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-26-2014 11:53 PM
Hi all,
i'm continuing the investigation, and i've found a recurrencies here: it's happening every Tuesday morning.
So, it is someway clear, for me, that it is "conflicting" or similar overload of connection during the time under investigation.
So, my question now is: how i can isolate allt he policies running on the same timeframe, Tue from 3 AM to 7 AM, for instance?
Thanks.
5/27/2014 3:52:27 AM - Info bpbrm(pid=18612) vm767502.ams20.vzbi.caas is the host to backup data from
5/27/2014 3:52:27 AM - Info bpbrm(pid=18612) reading file list from client
5/27/2014 3:52:28 AM - Info bpbrm(pid=18612) starting bphdb on client
5/27/2014 3:52:31 AM - Info bphdb(pid=8092) Backup started
5/27/2014 4:00:00 AM - Info nbjm(pid=21786) starting backup job (jobid=444986) for client vm767502.ams20.vzbi.caas, policy MNG_AMS20_SAP_DW2_DMZ, schedule DAILY_FULL_SAP_DB
5/27/2014 4:00:00 AM - Info nbjm(pid=21786) requesting MEDIA_SERVER_WITH_ATTRIBUTES resources from RB for backup job (jobid=444986, request id:{9C5B3FC0-E542-11E3-91D3-ED8467429DB0})
5/27/2014 4:00:00 AM - requesting resource ME-A2_PDSTU
5/27/2014 4:00:00 AM - requesting resource ph469702.ams20.vzbi.caas.NBU_CLIENT.MAXJOBS.vm767502.ams20.vzbi.caas
5/27/2014 4:00:00 AM - requesting resource ph469702.ams20.vzbi.caas.NBU_POLICY.MAXJOBS.MNG_AMS20_SAP_DW2_DMZ
5/27/2014 4:00:00 AM - granted resource ph469702.ams20.vzbi.caas.NBU_CLIENT.MAXJOBS.vm767502.ams20.vzbi.caas
5/27/2014 4:00:00 AM - granted resource ph469702.ams20.vzbi.caas.NBU_POLICY.MAXJOBS.MNG_AMS20_SAP_DW2_DMZ
5/27/2014 4:00:00 AM - granted resource ME-A2_PDSTU
5/27/2014 4:00:01 AM - estimated 0 Kbytes needed
5/27/2014 4:00:01 AM - Info nbjm(pid=21786) started backup (backupid=vm767502.ams20.vzbi.caas_1401156000) job for client vm767502.ams20.vzbi.caas, policy MNG_AMS20_SAP_DW2_DMZ, schedule DAILY_FULL_SAP_DB on storage unit ME-A2_PDSTU
5/27/2014 4:00:02 AM - started process bpbrm (18612)
5/27/2014 4:00:10 AM - connecting
5/27/2014 4:00:11 AM - connected; connect time: 00:00:01
read from input socket failed(636)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-27-2014 12:21 AM
I think you better off talking to the network guys explaining this happen every Tuesday instead for creating workarounds. This *could* be a planned boot of some sort.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-27-2014 02:27 AM
Sounds like some kind of maintenance job is running on a Tuesday morning...
Seeing that only one client is affected, I would start with Task scheduler on the client.
Check Windows Event logs as well.
- Veritas Backup Exec 23 - Slow Backup after Windows server 2019 upgrade in Backup Exec
- Attention DBAs! Now with NetBackup 10.4! Protect MSSQL Availability Group Secondary Replicas in NetBackup
- How to disable Windows Open File Backups globally in NetBackup
- Netbackup IT analytics install - I know Im late to the game to just get started with this in NetBackup
- netbackup appliance 5250 Universal Share Config in NetBackup Appliance
