- VOX
- Data Protection
- NetBackup
- SLP duplication of Granular recovery AD backup cau...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-08-2011 07:52 AM
Netbackup 7.1.0.1 Windows 2003 Server
We have a policy set up to backup up two of our Windows 2003 Active Directory DCs with the granular restore option enabled.
This policy is set to use an SLP. The SLP is configured to backup first to an Advanced disk storage unit then duplicate a second copy to tape (a robot attached to the same media server).
The strange problem occurs when the duplication stage begins. A process on the DC client called nblbc.exe utilises 100% of the CPU.
Why is the client even involved at this stage? Surely the duplication job should just read the image from the media servers’ disk pool and write\copy it to tape. There should be no client involvement at this point. And even so, why is the CPU being taxed so much?
Help!
Cheers
Al
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-11-2011 01:48 AM
Hi,
I suspect it might be due to this setting on the general tab of the master server "Enable message-level cataloging when duplicating Exchange images that use Granular Recovery Technology"
The documentation only refers to it impacting exchange but then AD GRT backups should work the same.
See if it removes the client processing component if you disable it.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-11-2011 01:48 AM
Hi,
I suspect it might be due to this setting on the general tab of the master server "Enable message-level cataloging when duplicating Exchange images that use Granular Recovery Technology"
The documentation only refers to it impacting exchange but then AD GRT backups should work the same.
See if it removes the client processing component if you disable it.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-11-2011 02:32 AM
Hi Riaan,
Interesting, I didn't think of that setting. I'll give it a go and report back.
Cheers
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-11-2011 02:42 AM
I found this in the guide. <<<<Exchange Guide
Configuring the granular restore proxy host
When you browse for or restore individual items using Granular Recovery Technology (GRT), NetBackup uses the destination client to stage a virtual copy of the database that you want to restore. However, NetBackup uses the source client of the backup to stage the database in the following situations: when you duplicate a GRT-enabled backup image or when you use the bplist command.
Alternatively, you can specify a different Windows system to act as a proxy for the client. Use a proxy if you do not want to affect the source client or if the source client is not available. To specify a proxy, configure the Exchange granular proxy host in the Exchange properties for the client.
When you use the bplist command and the bpduplicate command, you can override the Exchange granular proxy host setting with the -granular_proxy option.
NetBackup determines the granular restore proxy host in the following order:
■ The host that is specified with the -granular_proxy option on the command line
■ The granular restore proxy host that you specify in the host properties for the source client
■ The source client
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-11-2011 03:36 AM
Excellent, thanks Riaan. This did the trick and the process nblbc.exe didn’t start.
My understanding is that without this option selected it means that we can still do a granular restore from the disk copy, but once the image has gone to tape and if the disk copy had expired then we wouldn’t be able to do a granular restore, even if we restore the image to disk first.
Whereas previously once the image had gone to tape we would have been able to restore to disk first then do a granular restore.
Am I correct here?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-11-2011 03:40 AM
Hi,
Yes, that is correct. If you still want the catalog'd version you could use the proxy option so its catalog'd on another server.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-11-2011 04:08 AM
Great, thanks Riann, you have been very helpful.
Just one more thing, although I think I’ll need to start a new post for this one.
Shortly after this backup policy was setup we have been experiencing a really strange issue. Random restore jobs keep appearing in the activity monitor. These jobs refer to the Advanced disk pool (we only have one). They last about a second or two and complete successfully. They occur every minute or so and then periodically stop for about 40 minutes. This have been going on now for around two weeks. It’s been logged with Symantec and so far they haven’t found a solution.
This is all we get in the detailed status of the job (I’ve replaced the media server name with “MS00000”)
11/07/2011 11:50:30 - requesting resource @aaaak
11/07/2011 11:50:30 - granted resource MediaID=@aaaak;DiskVolume=E:\;DiskPool=RDR-Adv-MS00000-1;Path=E:\;StorageServer=MS00000;MediaServer=MS00000
Thanks again,
Al
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-11-2011 04:15 AM
Hi,
This usually happens when you browse a GRT backup, exchange, AD, etc. As you go deeper into the Storage Group, User Mailbox, Mailbox structure it kicks of a quick "restore". You can check this out by browsing the a backup in BAR, you'll see it hangs while the "restore" is busy, and as soon as its done you're able to browse the next level.
I assume this is normal behaviour as I've seen it do that at a lot of customers. Unless I've lost the plot :p
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-11-2011 05:12 AM
Ok, I see.
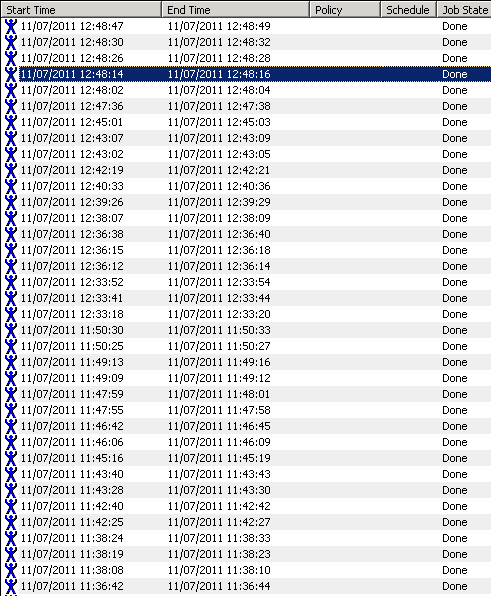
The problem is that no one is using BAR to do a restore. They just keep appearing on their own accord. I've rebooted both media and master server but the jobs continue to appear. I've attached a screenshot.
I appreciate your help on this as it's driving us crazy.
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-11-2011 05:16 AM
Have a look at bprd logs to see where they're being initiated from.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-11-2011 06:52 AM
Nothing is logged in the master server’s BPRD log to tell me what’s going on (logging level is set at maximum). Here’s a section from it at the time when one of the restore jobs started and completed.
Any more ideas?
Job overview Client = MasterServerName
Master Server= MasterServerName
Detailed status
1/07/2011 13:50:32 - requesting resource @aaaak
11/07/2011 13:50:32 - granted resource MediaID=@aaaak;DiskVolume=E:\;DiskPool=RDR-Adv-MS0000-1;Path=E:\;StorageServer=MS0000;MediaServer=MS0000
BPRD LOG
13:50:08.088 [3868.4032] <4> msgbackup: waiting for response from nbpem
13:50:08.447 [6000.3480] <2> vnet_cached_getaddrinfo_and_update: ../../libvlibs/vnet_addrinfo.c.1370: 0: found in cache name: MasterServerIPAddress
13:50:08.447 [6000.3480] <2> vnet_cached_getaddrinfo_and_update: ../../libvlibs/vnet_addrinfo.c.1371: 0: found in cache service: NULL
13:50:08.447 [6000.3480] <2> vnet_cached_getaddrinfo_and_update: ../../libvlibs/vnet_addrinfo.c.1370: 0: found in cache name: 127.0.0.1
13:50:08.447 [6000.3480] <2> vnet_cached_getaddrinfo_and_update: ../../libvlibs/vnet_addrinfo.c.1371: 0: found in cache service: NULL
13:50:21.088 [3868.4032] <4> pingpem: pinging nbpem
13:50:21.088 [3868.4032] <4> pingpem: waiting for pem to reply to ping
13:50:23.088 [3868.4032] <4> pingpem: ping of nbpem succeeded
13:50:40.088 [3868.4032] <4> msgbackup: waiting for response from nbpem
13:50:51.089 [3868.4032] <4> pingpem: pinging nbpem
13:50:51.089 [3868.4032] <4> pingpem: waiting for pem to reply to ping
13:50:53.089 [3868.4032] <4> pingpem: ping of nbpem succeeded
13:51:09.448 [6000.3480] <2> vnet_cached_getaddrinfo_and_update: ../../libvlibs/vnet_addrinfo.c.1370: 0: found in cache name: MasterServerIPAddress
13:51:09.448 [6000.3480] <2> vnet_cached_getaddrinfo_and_update: ../../libvlibs/vnet_addrinfo.c.1371: 0: found in cache service: NULL
13:51:09.448 [6000.3480] <2> vnet_cached_getaddrinfo_and_update: ../../libvlibs/vnet_addrinfo.c.1370: 0: found in cache name: 127.0.0.1
13:51:09.448 [6000.3480] <2> vnet_cached_getaddrinfo_and_update: ../../libvlibs/vnet_addrinfo.c.1371: 0: found in cache service: NULL
13:51:12.089 [3868.4032] <4> msgbackup: waiting for response from nbpem
13:51:21.089 [3868.4032] <4> pingpem: pinging nbpem
13:51:21.089 [3868.4032] <4> pingpem: waiting for pem to reply to ping
13:51:23.089 [3868.4032] <4> pingpem: ping of nbpem succeeded
13:51:44.090 [3868.4032] <4> msgbackup: waiting for response from nbpem
13:51:51.090 [3868.4032] <4> pingpem: pinging nbpem
13:51:51.090 [3868.4032] <4> pingpem: waiting for pem to reply to ping
13:51:53.090 [3868.4032] <4> pingpem: ping of nbpem succeeded
13:52:10.449 [6000.3480] <2> vnet_cached_getaddrinfo_and_update: ../../libvlibs/vnet_addrinfo.c.1370: 0: found in cache name: MasterServerIPAddress
13:52:10.449 [6000.3480] <2> vnet_cached_getaddrinfo_and_update: ../../libvlibs/vnet_addrinfo.c.1371: 0: found in cache service: NULL
13:52:10.449 [6000.3480] <2> vnet_cached_getaddrinfo_and_update: ../../libvlibs/vnet_addrinfo.c.1370: 0: found in cache name: 127.0.0.1
13:52:10.449 [6000.3480] <2> vnet_cached_getaddrinfo_and_update: ../../libvlibs/vnet_addrinfo.c.1371: 0: found in cache service: NULL
13:52:16.090 [3868.4032] <4> msgbackup: waiting for response from nbpem
13:52:21.090 [3868.4032] <4> pingpem: pinging nbpem
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-11-2011 07:10 AM
Ok, bpbrm on the master then.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-11-2011 09:05 AM
I created the bpbrm directory on the master server. A number of these restore jobs have run and no bpbrm log is even created. The master server services have been restarted just in case L.
I had a look at the bpcd log on the media server that hosts the advanced disk pool. It seems whenever one of the restore jobs begins the below output appears in the log.
The process nbfsd.exe is started on the media server. When I stop the process it’s automatically started again as soon as one of the restore jobs kicks off.
Replaced media server name with – MediaServer
Replaced NBU AD DC with - DomainControllerClient
15:51:57.474 [6620.5796] <2> process_requests: Duplicated vnetd socket on stderr
15:51:57.474 [6620.5796] <2> process_requests: <---- NetBackup 7.1 0 ------------initiated
15:51:57.474 [6620.5796] <2> process_requests: VERBOSE = 5
15:51:57.474 [6620.5796] <2> process_requests: Not using VxSS authentication with rxhis001.sussex.nhs.uk
15:51:57.599 [6620.5796] <2> process_requests:
15:51:57.599 [6620.5796] <2> process_requests: BPCD_START_NBFSD_RQST
15:51:57.677 [6620.5796] <2> start_nbfsd: nbfsdCmd: '"C:\Program Files\Veritas\NetBackup\bin\nbfsd.exe" -k -v 5 -p -j 587768 -B DomainControllerClient_1309401013 -U DBM -c DomainControllerClient -f MediaServer -i @aaaak'
15:51:59.318 [6620.5796] <2> process_requests: BPCD_DISCONNECT_RQST
15:51:59.318 [6620.5796] <2> bpcd exit_bpcd: exit status 0 ----------->exiting
- Duplications randomly appear to hang in NetBackup
- Understand which Storage devices fits into your Data-Protection strategy in Backup Exec
- Same kilobyte and backup time when backup "Full Backup" or "Diff Incr Backup" in NetBackup
- NetBackup GRT duplications to Tape in NetBackup
- SLP - Error in duplicate for Tape Library in NetBackup
