- VOX
- Technical Blogs
- Availability
- Scale compute and storage independently with InfoS...
Scale compute and storage independently with InfoScale Storage 7.1
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
InfoScale storage's flexible storage sharing feature (FSS) allows pooling and sharing of storage resources among various compute entities whether they are physical machines, virtual machine or a mix of both.
The new version 7.1 of InfoScale takes FSS to the next level by providing the ability to isolate and on demand plumb the required amount of storage of desired charactistics to the compute entities where the application has been chosen to run thus improving the scalability of the cluster. Some of the key benefits are:
- Improved view of the storage in a large cluster
- Simplified storage provisioning
- Easier device management
This blog would provide insight into the thought process that went into designing this.
Applications require a desired amount of compute, network and storage to run. Typically they are deployed on resource pools so as to not only improve utilization as well as provide high availability and resilience against component failures or scheduled maintenance activities.
In order to meet the storage needs of the applications in such an environment, the access to the storage needs to be dynamic and flexible. One way of doing this is to use a Storage Area Network (SAN) but this cumbersome as it requires the storage array and SAN switches be reconfigured for providing access on the fly. Network attached storage (NAS) provides the required flexiblity, we just need to connect to the same IP portal, but it cannot meet the performance demands of enterprise class applications. InfoScale flexible storage sharing fits the bill by allowing compute instances to dynamically share any type of block storage (local, directly attached - DAS or SAN) with one another.
Prior to InfoScale 7.1 this was achieved by mimicing locally available storage as a shared SAN storage by exporting them to all compute entities in the Infoscale cluster. For e.g as shown below, in a 16 node VMware virtual machine cluster (sal1 .. sal16) a VMDK on one VM can be shared with all other VMs. Notice how one VM even has SAN storage attached that can also be shared. Once created, the FSS diskgroup appears on all the cluster nodes (compute instances).
---------- Export the local disk sal1_vmdk0_4 on sal1 to all nodes in cluster ---------- [root@sal1 ~]# vxdisk export sal1_vmdk0_4 [root@sal1 ~]# vxdisk list DEVICE TYPE DISK GROUP STATUS emc0_019b auto:cdsdisk - - online thinrclm emc0_019c auto:cdsdisk - - online thinrclm emc0_019d auto:cdsdisk - - online thinrclm emc0_019e auto:cdsdisk - - online thinrclm sal1_vmdk0_0 auto:cdsdisk disk01 testdg online sal1_vmdk0_1 auto:cdsdisk - - online sal1_vmdk0_2 auto:cdsdisk - - online sal1_vmdk0_3 auto:LVM - - LVM sal1_vmdk0_4 auto:cdsdisk - - online exported [root@sal1 ~]# ---------- Remote node sal16 sees the disk sal1_vmdk0_4 ---------- [root@sal16 ~]# vxdisk list DEVICE TYPE DISK GROUP STATUS sal1_vmdk0_4 auto:cdsdisk - - online remote sal16_vmdk0_0 auto:cdsdisk - - online sal16_vmdk0_1 auto:cdsdisk - - online sal16_vmdk0_2 auto:cdsdisk - - online sal16_vmdk0_3 auto:LVM - - LVM sal16_vmdk0_4 auto:cdsdisk - - online [root@sal16 ~]# ---------- Create a FSS disk group fssdg on remote disk sal1_vmdk0_4 ---------- [root@sal16 ~]# vxdg -o fss -s init fssdg sal1_vmdk0_4 [root@sal16 ~]# vxdisk list DEVICE TYPE DISK GROUP STATUS sal1_vmdk0_4 auto:cdsdisk sal1_vmdk0_4 fssdg online shared remote sal16_vmdk0_0 auto:cdsdisk - - online sal16_vmdk0_1 auto:cdsdisk - - online sal16_vmdk0_2 auto:cdsdisk - - online sal16_vmdk0_3 auto:LVM - - LVM sal16_vmdk0_4 auto:cdsdisk - - online [root@sal16 ~]# ---------- All other nodes see the disk and fssdg ---------- [root@sal9 ~]# vxdisk list DEVICE TYPE DISK GROUP STATUS sal1_vmdk0_4 auto:cdsdisk sal1_vmdk0_4 fssdg online shared remote sal9_vmdk0_0 auto:cdsdisk - - online sal9_vmdk0_1 auto:cdsdisk - - online sal9_vmdk0_2 auto:cdsdisk - - online sal9_vmdk0_3 auto:cdsdisk - - online sal9_vmdk0_4 auto:LVM - - LVM [root@sal9 ~]#
With InfoScale 7.1 this flexiblity in sharing storage is taken to the next level. There is no need to create a shared SAN using locally connected storage prior to using the storage to provision for applications. Instead which ever compute instance(s) the application needs to be run the storage is automatically mapped behind the scenes. If the application moves for high availabilty reasons, the storage is replumbed to the new compute instance. If more instances of the application need to be created on different compute instances then the storage is mapped additionally to only those nodes.
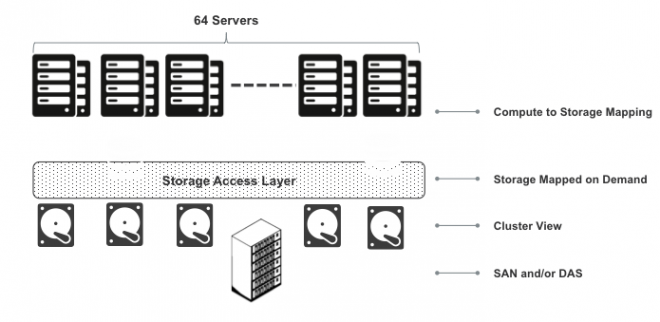
This is achieved by the 'storage access layer' that manages access to storage devices in InfoScale Storage cluster. It continously keeps track of all the storage devices along with their access state (cluster nodes or compute instances that currently can access it), device status (in-use, free, error) and makes sure this information is readily available with any node in the cluster, like a replicated state machine. This information can be viewed from any node in the cluster using the below CLI. Notice the node count information (last but one column) which provides the number of cluster nodes to which the storage is accessible.
---------- Clusterwide disk list that can be run on any node ----------
[root@sal9 ~]# vxdisk -o cluster list
DEVICE MEDIA SIZE(MB) GROUP NODES STATE
emc0_019b hdd 30720 docdg 8 online
emc0_019c hdd 30720 - 8 online
emc0_019d hdd 30720 - 8 online
emc0_019e hdd 30720 - 8 online
sal1_vmdk0_0 hdd 1024 testdg 1 online
sal1_vmdk0_1 hdd 1024 - 1 online
sal1_vmdk0_2 hdd 1024 - 1 online
sal1_vmdk0_4 hdd 1024 fssdg 1 online
sal2_vmdk0_0 hdd 1024 - 1 online
sal2_vmdk0_2 hdd 1024 - 1 online
sal2_vmdk0_3 hdd 1024 - 1 online
sal2_vmdk0_4 hdd 1024 - 1 online
sal3_vmdk0_0 hdd 1024 - 1 online
sal3_vmdk0_2 hdd 1024 - 1 online
. . .
---------- Details of a disk seen the cluster ----------
[root@sal9 ~]# vxdisk -o cluster list sal1_vmdk0_4
device : sal1_vmdk0_4
dg : fssdg
udid : VMware%5FVirtual%20disk%5Fvmdk%5F6000C29EC814CF8EF6A79BD81CF5D8E1
dgid : 1463041712.50.sal1
guid : {51f6c334-e061-11e5-8b7f-89362c795deb}
mediatype : hdd
site : -
status : online
size : 1024 MB
block size : 512
max iosize : 1024
connectivity:
node[14] : sal1
[root@sal9 ~]#This list can be pretty huge when we have a large number of cluster nodes and each with its own local storage. So the CLI supports filter options based on node name, media type, free etc which can come in handy.
vxdisk -o cluster [-o udid] [-o dg] [-o dgid] [-o node] [-o free] [ -o mediatype={ssd|hdd}] list With this information available, any compute instance that requires to provision storage needs to just pick free storage available in the cluster and start using it. the other cluster nodes immediately get to know that the storage is no longer free.
---------- Initial disk list ---------- [root@sal9 ~]# vxdisk list DEVICE TYPE DISK GROUP STATUS sal1_vmdk0_4 auto:cdsdisk sal1_vmdk0_4 fssdg online shared remote sal9_vmdk0_0 auto:cdsdisk - - online sal9_vmdk0_1 auto:cdsdisk - - online sal9_vmdk0_2 auto:cdsdisk - - online sal9_vmdk0_3 auto:cdsdisk - - online sal9_vmdk0_4 auto:LVM - - LVM [root@sal9 ~]# ---------- Choose a free disk sal7_vmdk0_0 from cluster list ---------- [root@sal7 ~]# vxdisk -o cluster -o free list DEVICE MEDIA SIZE(MB) GROUP NODES STATE emc0_019c hdd 30720 - 8 online emc0_019d hdd 30720 - 8 online emc0_019e hdd 30720 - 8 online sal1_vmdk0_1 hdd 1024 - 1 online sal1_vmdk0_2 hdd 1024 - 1 online ... sal6_vmdk0_2 hdd 1024 - 1 online sal6_vmdk0_4 hdd 1024 - 1 online sal7_vmdk0_0 hdd 1024 - 1 online sal7_vmdk0_1 hdd 1024 - 1 online ... ---------- Directly use it to initialize a disk group saldg ---------- [root@sal9 ~]# vxdg init saldg sal7_vmdk0_0 [root@sal9 ~]# vxdisk list DEVICE TYPE DISK GROUP STATUS sal1_vmdk0_4 auto:cdsdisk sal1_vmdk0_4 fssdg online shared remote sal7_vmdk0_0 auto:cdsdisk sal7_vmdk0_0 saldg online remote sal9_vmdk0_0 auto:cdsdisk - - online sal9_vmdk0_1 auto:cdsdisk - - online sal9_vmdk0_2 auto:cdsdisk - - online sal9_vmdk0_3 auto:cdsdisk - - online sal9_vmdk0_4 auto:LVM - - LVM [root@sal9 ~]# ---------- The disk is shown to be in use from any node in cluster ---------- [root@sal16 ~]# vxdisk -o cluster list | grep sal7_vmdk0_0 DEVICE MEDIA SIZE(MB) GROUP NODES STATE sal7_vmdk0_0 hdd 1024 saldg 1 online [root@sal16 ~]#
In order to achieve migration of storage when the application consuming it migrates, all we need to do is deport the diskgroup from the source compute instance (cluster node) and reimport it on the destination. This just simplifies the operation and can be easily automated using high availabilty solutions like InfoScale Availability
---------- Deport the diskgroup saldg from sal 9 ---------- [root@sal9 ~]# vxdg deport saldg [root@sal9 ~]# vxdisk list DEVICE TYPE DISK GROUP STATUS sal1_vmdk0_4 auto:cdsdisk sal1_vmdk0_4 fssdg online shared remote sal9_vmdk0_0 auto:cdsdisk - - online sal9_vmdk0_1 auto:cdsdisk - - online sal9_vmdk0_2 auto:cdsdisk - - online sal9_vmdk0_3 auto:cdsdisk - - online sal9_vmdk0_4 auto:LVM - - LVM [root@sal9 ~]# ---------- Disk is automatically unmapped from sal9 ---------- [root@sal16 ~]# vxdisk list DEVICE TYPE DISK GROUP STATUS sal1_vmdk0_4 auto:cdsdisk sal1_vmdk0_4 fssdg online shared remote sal16_vmdk0_0 auto:cdsdisk - - online sal16_vmdk0_1 auto:cdsdisk - - online sal16_vmdk0_2 auto:cdsdisk - - online sal16_vmdk0_3 auto:LVM - - LVM sal16_vmdk0_4 auto:cdsdisk - - online ---------- Now import the disk group on another node sal16 ---------- [root@sal16 ~]# vxdg import saldg [root@sal16 ~]# vxdisk list DEVICE TYPE DISK GROUP STATUS sal1_vmdk0_4 auto:cdsdisk sal1_vmdk0_4 fssdg online shared remote sal7_vmdk0_0 auto:cdsdisk sal7_vmdk0_0 saldg online remote sal16_vmdk0_0 auto:cdsdisk - - online sal16_vmdk0_1 auto:cdsdisk - - online sal16_vmdk0_2 auto:cdsdisk - - online sal16_vmdk0_3 auto:LVM - - LVM sal16_vmdk0_4 auto:cdsdisk - - online [root@sal16 ~]#
As an extension if there is a requirement to have parallel/shared access to application instances running on more than one compute instances (cluster nodes) then there is the application isolation feature, released as a 'tech preview' in InfoScale 7.1 which can provide this. Look out for a blog on it...
This way we can easily scale the number of application instances without worrying about the storage connectivity. At the same time we can scale up the storage requirements of the application by plugging in new nodes to the cluster (that can provide storage) or pluging-in new storage on any node in the cluster. An extension of the latter is to plug-in a SAN to only one node and use it from rest of the nodes in the cluster - something very unique with InfoScale Storage.
There is also a helper utility that provides a summary of the storage available in the cluster and on each node of the cluster. This can be run from any node in the cluster
---------- Obtain the total and free storage capacity of cluster from any node ---------- [root@sal7 ~]# vxsan list nodes: total=16 storage=16 diskgroups: total=5 imported=0 devices: hdd: total=68 capacity=188416 MB free=153600 MB ssd: total=0 capacity=0 MB free=0 MB [root@sal7 ~]# ---------- Obtain a node wise listing of HDD & SDD storage capacity ---------- [root@sal7 ~]# vxsan list nodes HDD SSD -------------------------------- --------------------------------- NODE COUNT TOTAL (MB) FREE (MB) COUNT TOTAL (MB) FREE (MB) sal1 8 126976 94208 0 0 0 sal2 8 126976 96256 0 0 0 sal3 8 126976 96256 0 0 0 sal4 8 126976 95232 0 0 0 sal5 8 126976 96256 0 0 0 sal6 8 126976 96256 0 0 0 sal7 8 126976 95232 0 0 0 sal8 8 126976 96256 0 0 0 sal9 4 4096 4096 0 0 0 sal10 4 4096 4096 0 0 0 sal11 4 4096 4096 0 0 0 sal12 4 4096 4096 0 0 0 sal13 4 4096 4096 0 0 0 sal14 4 4096 4096 0 0 0 sal15 4 4096 4096 0 0 0 sal16 4 4096 4096 0 0 0 [root@sal7 ~]#
When resources are pooled/shared to improve utilization a typical problem encountered is the noisy neighbour situation. The storage access layer in conjuction with application isolation feature provides the access isolation while the performance isolation can be achieved by restricting the maximum number of IOPS a particular application can issue to the storage system. Be on a look out for a blog about this InfoScale 7.1 feature as well..
InfoScale storage can be used as the storage backbone not only to host enterprise applications like Oracle RAC, but also
- Analytical workloads like SAS, Informatica
- Virtual machines running on RHEL-H/KVM hypervisor
- Docker container instances
- etc..
All these get the same flexibility for meeting the storage needs while ensuring enterprise class storage performance and availability.
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
- Resiliency and Data Mobility in AWS with Veritas Alta™ Application Resiliency in Availability
- Veritas at AWS re:Invent 2022 in Enterprise Data Services Community Blog
- Fortify your perimeter: Stop the spread of ransomware dead in its tracks in Protection
- Enterprise Storage and Data Protection for Red Hat OpenShift in Protection
- Cloud Application Security Made Easy with InfoScale in Availability
