Comparing apples to apples: All that glisters is not gold
Last week we made a shocking revelation. The storage snapshot integration from Competitor ‘C’ barely meets the RPOs that are already achievable in NetBackup Accelerator where operationally expensive storage integration is not required. In terms of solution implementation, we were comparing apples and oranges. Now it is time to compare apples to apples.
Well, it is time to break more news. While Competitor ‘C’ is trying to position itself as the spokesperson of snapshot management, the engineering details are nowhere close to what marketing tends to spit out. The glistering messages are just a cover for poorly designed integration that defeats the very purpose of why someone should use snapshots in the first place. NetBackup Replication Director beats Competitor ‘C’, securing an impressive score of 16:1 for a workload constituting 1000 virtual machines proving its leadership in scalability and efficient performance.
The irony here is the storage array is the one creating the recovery point. The backup software is simply orchestrating the operation. You wouldn’t expect significant differences in performance across backup vendors, would you? What can we say?

Gory details
In order to compare storage snapshots integration across multiple vendors, we compared NetBackup Replication Director with similar capability from Competitor ‘C’. The goal is to test this integration for scale, performance and efficiency. Let us look at a high level workflow for a backup application using storage snapshots to create recovery points in VMware vSphere environments.
- Quiesce applications and file systems in virtual machines
- Perform hypervisor level snapshot of virtual machines
- Create storage level snapshot of data stores encompassing virtual machines
- (Optional) Enumerate and index virtual machine content
- (Optional) Perform backups from storage snapshots
Of course, this is an oversimplified picture. A lot more thought goes into discovering application profiles, connecting various pieces of a distributed application, accounting for virtual machines spanning data stores, understanding storage profiles and so on.
The recovery points are ready at the end of step 3. It is possible to browse and restore a virtual machine and its content from the storage snapshot. Hence 4 and 5 are value-added tasks to solve for other business needs.
If you perform 1,2 and 3 the resultant recovery point is known as an application consistent recovery point. Recovery is guaranteed from this type of recovery point because file system and applications were in a consistent, recoverable state when the snapshots were created. In most cases, step 1 may be the bottleneck as it may take longer to quiesce all file systems and applications of a distributed application to a get a logically consistent application state.
If you skip step 1 and 2, the resultant recovery point is known as a crash consistent recovery point. Modern applications and file systems have some level of built-in capabilities to recover from an abruptly aborted state (e.g. power failure, panic and other type of crashes). What happens if you skip step 1? From an application’s point of view, the recovery points are functionally equivalent to virtual machines that were abruptly shutdown. This type of recovery point is used when you need to solve for super aggressive RPOs. Of course, you also need to understand the potential risks. What I recommend is a combination of application consistent recovery points (e.g. generate these every day) and crashes consistent recovery points (e.g. generate these every 15 minutes) so that you can solve for super aggressive RPOs with some calculated risk tolerance.
Principled Technologies put both NetBackup Replication Director and storage snapshot integration solution from Competitor ‘C’ to the test. Both products were configured such that the value-added optional steps were skipped (Step 4 & 5). Great care was taken to make sure that the attributes and other parameters were made equivalent for an apples to apples comparison.
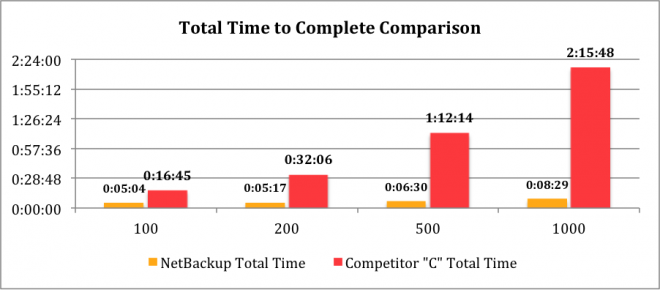
Crash Consistent Recovery Points from Storage Snapshots
The results are depicted in the graph above.
- Even at relatively low workloads (100 virtual machines), Competitor ‘C’ takes more than 3x longer to create recovery points
- As expected, NetBackup Replication Director performance is not only superior, but it scales well due to the architectural superiority in making use of multi-threaded processes and parallel processing. For at 10x increase in workloads, NetBackup Replication Director needed a few additional minutes to finish the task!
- Design shock: Competitor ‘C’ was unable to meet the scalability requirement. Its performance degrades significantly as the workload increases. For a 10x increase in workload, it needed more than 2 hours to finish the task (compare this with just a few additional minutes needed for NetBackup Replication Director). The architectural limitations seem to force Competitor ‘C’ to perform virtual machine snapshots even in the case of creating crash consistent recovery points.
Principled Technologies is the industry benchmark expert. While we in Symantec respect their due diligence in ensuring an accurate and fair comparison of competing solutions, we couldn’t believe this result at all. We requested that we needed to be 100% sure about the configuration. We wanted to make sure that optional steps 4 & 5 were not being performed. We flew many experts who were intimately familiar with that product to the benchmark lab to examine each and every aspect of the configuration. We wanted to make sure that we were treating Competitor ‘C’ with utmost fairness. In fact, the benchmark project was delayed by a month just because it was difficult to believe what was uncovered from the design tomb! Once the subject matter experts signed off, Principled Technologies officially declared the results as final.
Application Consistent Recovery Points from Storage Snapshots
Now that we have grown the test environment to 1000 virtual machines, our goal was to start the application consistent backup at 1000 virtual machines and work our way backward if needed. Soon we realized that there wasn’t any need to run tests at lower VM counts. Let me show you the result and explain.
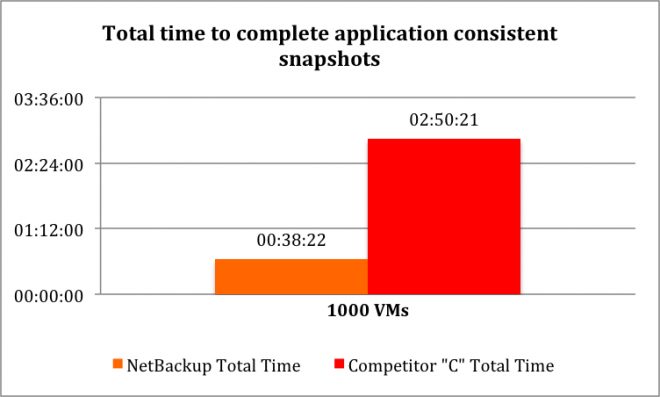
- At 1000 virtual machines, the addition of file system and application quiescence operations (the step 1 mentioned earlier) added nearly 30 minutes to Replication Director and 35 minutes to Competitor ‘C’
- Now we know that the step 1 for Competitor ‘C’ is not as efficient as that of NetBackup Replication Director, but not as horrible as how steps 2 & 3 performed!
- The most of the inefficiency in Competitor ‘C’ is really coming from steps 2 and 3 thereby exposing the design limitations of Competitor ‘C’
Thus, it is not necessary to repeat the application consistency snapshot tests at lower VM counts as we did for crash consistent snapshots. We can predict that the pattern is going to be the same with added offset from step 1.
In short, when we perform an apples-to-apples comparison of storage snapshot integration in NetBackup and Competitor ‘C’, it became shockingly obvious that the latter is inefficient and not scalable. Why do they promote storage snapshots to protect virtual environments? We found out yet another ugly truth. Prepare to be even more amazed! Stay tuned for the next blog in this series.
Other blogs in this series
NetBackup Accelerator questions the value of storage-based snapshot integration from Competitor 'C'