gco fencing
 10 years ago
10 years agoHi,
Scope of VxFen is limited to nodes within same cluster and cannot be used across sites/clusters in GCO. In this case, Node1 and Node2 belongs to 2 different sites/clusters. In case of communication failure between the node1 and node2, VxFen cannot be used. For addressing split-brain between clusters in GCO, VCS uses Steward process.
Steward process to minimize chances of a wide-area split-brain
Failure of all heartbeats between any two clusters in a global cluster indicates one of the following:
- The remote cluster is faulted.
- All communication links between the two clusters are broken.
In a two-cluster setup, VCS uses the Steward process to minimize chances of a wide-area split-brain. The process runs as a standalone binary on a system outside of the global cluster configuration. Figure depicts the Steward process to minimize chances of a split brain within a two-cluster setup.
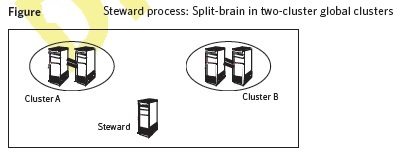
When all communication links between any two clusters are lost, each cluster contacts the Steward with an inquiry message. The Steward sends an ICMP ping to the cluster in question and responds with a negative inquiry if the cluster is running or with positive inquiry if the cluster is down. The Steward can also be used in configurations with more than two clusters.
More details about GCO configuration and Steward process’s configuration is available at: https://sort.symantec.com/public/documents/sf/5.1/aix/html/vcs_admin/ch_vcs_globalcluster22.html
Thanks & Regards,
Sunil Y
 10 years ago
10 years agoGCO is usually configured as manually initiated, but it is still quicker as VCS does all the work, you just confirm for VCS to go ahead. You can configure as automatic if you use a Steward, but I wouldn't recommend unless you really have an independent link to your steward as generally if you loose connection between Prod and DR site you will often loose connection to your Steward as well.
Configuring ClusterFailOverPolicy as "Connected" is another option so that if a service groups fails on all systems in its system list then if one node is up in the cluster, then failover is atuomatic and as one node is up, you know splt-brain is not an issue.
So for example if you configure clusters as in your other post where failoversg runs on nodea in cluster1 and fails over to nodec in cluster2, then if nodea fails and nodeb in cluster1 is up, then nodeb knows nodea is actually down (as should have at least 2 independent LLT links between nodea and nodeb and you could configured local fencing also) and so with ClusterFailOverPolicy as "Connected", then failoversg will automatically fails to nodec in cluster2.
Mike