Disk space (MSDP) discrepencies between master and media server appliance
So I have a discrepency on one of my media server appliances (5220) which is causing me some headaches, since it is reporting "disk full" during my backup window and failing some backups and duplications. Strange thing is that the media server itself shows to only be 89% full (the Java console and OpsCenter show this pool is 96% full):
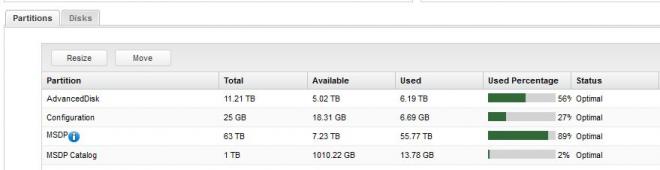
densyma02p.Storage> Show Partition - [Info] Performing sanity check on disks and partitions... (5 mins approx) ----------------------------------------------------------------------- Partition | Total | Available | Used | %Used | Status ----------------------------------------------------------------------- AdvancedDisk | 11.21 TB | 4.93 TB | 6.28 TB | 57 | Optimal Configuration | 25 GB | 18.31 GB | 6.69 GB | 27 | Optimal MSDP | 63 TB | 7.22 TB | 55.78 TB | 89 | Optimal MSDP Catalog | 1 TB | 1010.2 GB | 13.78 GB | 2 | Optimal Unallocated | 251.98 GB | - | - | - | -

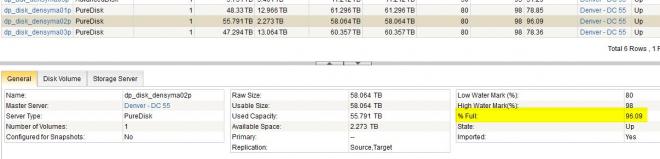
I'm half-inclined to restart the services on the master... but wanted to know if anyone has run into this issue?
Root-cause: Bug in 7.6.1 install that caused a VxFS storage checkpoint to be left behind after the upgrade. This checkpoint gradually grew until the MSDP filesystem was out of space. Discovered using the command:
fsckptadm list /msdp/data/dp1/pdvol
Removed with:
fsckptadm remove msdp_ckpt /msdp/data/dp1/pdvol
Restarted services and my MSDP pool was back in business.
This affected *2* of my 5220 appliances - both had to be repaired with the above procedure.
Support Case #08311159 just in case anyone needs to reference this issue with Support.