- VOX
- Technical Blogs
- Enterprise Vault Engineering Blog
- What information is used during classification?
What information is used during classification?
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
During the classification of an item a text file with the item’s metadata properties and content is generated. This file is generated under the classification cache folder and it is, by default, immediately disposed after a classification.
By keeping these files, it is possible to see exactly what kind of information is used for classification. This is very useful when it comes to create new classification rules as all of the information that the Veritas Information Classifier will use for classification can be easily seen and rules can be easily adjusted.
In order to set up Enterprise Vault to keep the classification text files in disk after a classification:
- Open the Properties of the server
- Under the ‘Advanced’ tab select ‘Storage’ and enable the option ‘Keep classification files’
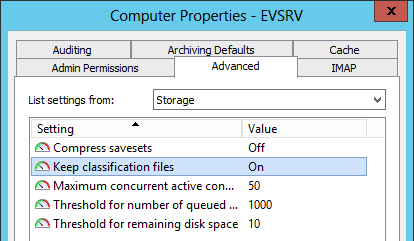
- Note: Classification text files will be kept in the cache location until they are manually deleted or the option is disabled
In order for one of these classification text files to be generated, ingest a new item and make sure it gets classified. When classification occurs it generates the text file which can be then inspected using any text editor like notepad.
Sample of what the content of the classification text files can look like
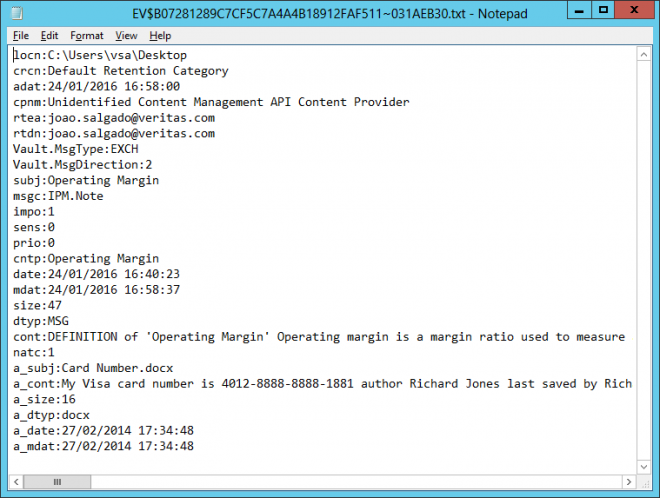
While a larger set of metadata can be provided for classification, only the properties relevant to the item are written to the text file. For example, the classification text file generated for an email will have a list of all the recipients, the classification text file generated of a Word document will not.
The complete list of properties that can be used for classification can be found in the Classification help document.
It is also worth noticing that attachment’s metadata can be differentiated since they all start their fieldname with “a_”. For example, if an email was archived with a Word document as an attachment the field “a_dtyp” will contain the value “docx” but the value of the field “dtyp” will be “msg” as it can be seen in the image above.
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
- Role-based Access Control (RBAC) in Backup Exec in Protection
- Anomaly Detection in Backup Exec in Backup Exec
- Ransomware Resilience in Backup Exec in Backup Exec
- Understand, Plan and Rehearse Ransomware Resilience series - Day 1 in Protection
- Understand, Plan and Rehearse Ransomware Resilience series - Access and Improve in Protection
