- VOX
- Data Protection
- NetBackup
- @backup-botw - in another
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-09-2015 09:37 AM
I am sure this has been answered 100 times over and I have read a bunch of different documents, forum posts, whitepapers and anything else I could find. In my environment we are having issues where we appear to not be getting very good throughput during the first weekend of each month when we are busiest. Based on another recommendation I have setup a duplication window to run during the day so they dont interfere with backups and the replication SLPs run 24x7. What I am seeing in bptm is less than 100MB/sec write speeds when duplicating images to tape. I have 4 dedicated LTO 6 drives which should be getting upwards of 160MB/sec so I am quite certain that my issue is that my environment is simply not tuned accordingly to accomdate our requirements.
I have found one website and a best practices document from Vision that show the below settings as a starting point.
- SIZE_DATA_BUFFERS = 262144
- SIZE_DATA_BUFFERS_DISK = 1048576
- NUMBER_DATA_BUFFERS = 256
- NUMBER_DATA_BUFFERS_DISK = 512
- NET_BUFFER_SZ = 1048576
- NET_BUFFER_SZ_REST = 1048576
Currently on my media servers that have the disk pools attached I have nothing tuned and I really am not sure where to begin to ensure this is done correctly.
Now I do see in /usr/openv/netbackup/db/config on these 3 media servers attached to disk pools the below two files with the following settings...
DPS_PROXYDEFAULTRECVTMO - 3600
DPS_PROXYDEFAULTSENDTMO - 3600
Now my master server which is not connected to a disk pool has some configurations set on it which are as follows...
/usr/openv/netbackup
NET_BUFFER_SZ - 262144
And...
/usr/openv/netbackup/db/config
NUMBER_DATA_BUFFERS - 64
NUMBER_DATA_BUFFERS_RESTORE - 64
SIZE_DATA_BUFFERS - 262144
Now all of these current settings pre-date me. I have not set or adjusted any of them and my predecessor was not here when I took this position so I have no information as to what was done to come up with these numbers. I do know that the site I am at used to be a DR location that didn't do much and is now the primary site and the workload has quadrupled.
I have 4 LTO 6 drives attached to the media servers that are attached to the disk pools and the drives are dedicated to doing duplication jobs so they dont interfere with backups. I plan to add a 5th in the near future once it has been zoned.
I have adjusted some of the SLP Parameters and mainly focused on the min and max size to try and match that of an LTO 6 tape.
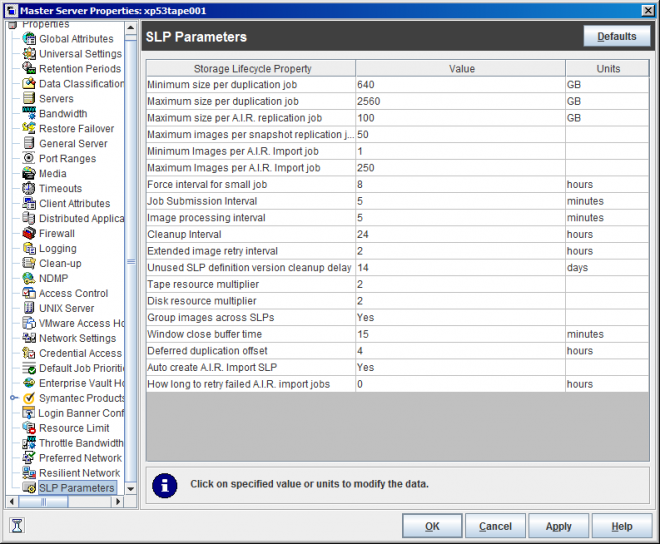
My max concurrent jobs setting is currently at 55 for the 3 storage units that are attached to disk...

But my current max i/o streams setting is not used so it is unlimited...

I do have an issue with memory usage on the master which we are fixing as soon as our new memory we ordered comes in and I can load it up. The media servers however have a ton of memory so I dont see any OS performance issues on them at all. This is also the only thing preventing me from upgrading the site to 7.7.1 so once that is done I will also get the upgrade done which should resolve some of our issues as well.
I am pretty confident that this is a lack of performance tuning issue as we can restart Netbackup throughout the environment and everything starts working much better. Also we have zero issues throughout the month at all until we get to this full monthly weekend. When we checked on write speeds to the LTO 6 drives yesterday we saw them as low as 15MB/sec, but after restarting everything this morning we are seeing them in the 90 to 99MB/sec range. Still believe we should be faster since they are LTO 6 drives though.
I have also attached some bptm logs from 10-3...when the full monthly backups started...and from 10-9 which is today. I can grab other logs from days in between if needed as well.
Solved! Go to Solution.
- Labels:
-
7.6
-
Backup and Recovery
-
NetBackup
-
Performance
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-09-2015 04:57 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-12-2015 12:39 PM
These guys really know their stuff, and can be a great help in tuning. It is a challenge due to the tremendous amount of variables.
I know that even something as simple as master server logging can have an impact - I got my logs on faster disk and all my backup speeds increased my a bit. Makes sense, because NetBackup logs every block it writes.
IMHO you will find that the speed of the source is almost always the weakest link, unless you have TAN issues or horribly messed up media servers, and your parameters look fine.
duplicating via SLP to LTO5 & LTO8 in SL8500 via ACSLS
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-12-2015 12:41 PM
Also - when is cleaning run on these disks? I know I see a definite impact when my Data Domains are cleaning.
duplicating via SLP to LTO5 & LTO8 in SL8500 via ACSLS
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-14-2015 10:54 AM
The VNX storage carving looks quite odd and lumpy. I would expect all sorts of minor performance issues with a non-symmetrical allocation pattern/distribution... and thus some days it will perform fine, some days not so fine... and because it's so uneven it will be really hard to work out what's going on under the hood. Those 10+TB LUNs... why on earth are they so big? Most unusual. Do you really have 31 RAID-6 PGs sitting underneath 27 LUNs? And you haven't described whether there is a volume abstracttion layer between the PGs and the LUNs, is there? And, there must be an awful lot of spindles wasted on parity. Again, most unusual.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-14-2015 11:21 AM
It performs without issue all the time up until duplications run. We have worked with EMC to checkout the disk while backups are running and they are seeing no performance issues on the disk at all. According to our vendor this is not a disk related issue at all, but rather application related. At this time I fully agree with them.
If you have any kind of documentation reference where Veritas tells you how to layout disk I would love to read it.
Yes what I posted above is really how its layed out. I was not here when this was setup...I inherited this configuration.
I have no idea why they are so big. They are all added to one big pool in the end.
I dont know what a "volume abstraction layer" is. I dont know what PGs are either. I am not the storage guy...I do the backup and recovery stuff.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-14-2015 11:24 AM
Daily during the day. We see no issue when image cleanup runs.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-14-2015 11:26 AM
I have yet to see any recommendations on buffer configurations which is what I was originally requesting. Just references to my disk and its setup even though our disk vendor has already verified there are no performance issues to speak of. While it may not be the best or most ideal to some it does work. The only thing causing issues is Netbackup Duplication jobs.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-14-2015 11:28 AM
At this time I do not wish to troubleshoot the disk setup or SAN zoning. We have this setup in our entire environment and we have no issues. That is a rabbit hole that is not worth traveling at this time. I have a case open with Veritas and they are indeed seeing issues with the lack of optimization and buffer configurations.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-14-2015 12:55 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-15-2015 01:22 AM
Was your vendor able to demonstrate (prove?) why it is an application issue? And... Why it is not a disk issue? Seems a lot of investigation has already been performed, and some truths are already known - if you could share those findings with us?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-15-2015 10:41 AM
One problem you will find is there are a lot of variables that impact your tape write speed, and you are focusing on buffers.
If you want to just tune your buffers, stop all duplications and write a specific backup - like a 1TB file, using different buffer settings, and duplicate it to tape using bpduplicate. Record the timings.
Be aware, some of the buffer settings are defined at backup time and the duplication to tape will use those same buffer settings. And your optimal speed for backups to disk may not be the same for speed to tape.
Which is more important?
Here is the type of spreadsheet I set up:(these are to disk, not tape)
| number | size | Elapsed Time Seconds | KB per Second | waited for full buffer | delayed |
| 16 | 65536 | 842 | 66,327 | 32,357 | 34,072 |
| 32 | 65536 | 852 | 65,297 | 33,132 | 34,953 |
| 64 | 65536 | 695 | 80,878 | 22,549 | 24,032 |
| 96 | 65536 | 755 | 73,885 | 26,493 | 28,219 |
| 128 | 65536 | 692 | 81,390 | 22,462 | 23,909 |
| 8 | 131072 | 1,179 | 46,742 | 59,217 | 61,851 |
| 16 | 131072 | 1,454 | 37,846 | 75,965 | 79,276 |
| 32 | 131072 | 1,295 | 42,462 | 65,915 | 68,778 |
| 64 | 131072 | 818 | 67,957 | 35,792 | 37,720 |
| 96 | 131072 | 973 | 57,020 | 45,683 | 47,979 |
| 128 | 131072 | 1,154 | 48,385 | 56,395 | 59,079 |
| 8 | 262144 | 551 | 101,920 | 20,881 | 22,337 |
| 16 | 262144 | 569 | 98,781 | 17,911 | 19,319 |
| 32 | 262144 | 569 | 98,767 | 21,737 | 23,107 |
| 64 | 262144 | 571 | 97,896 | 21,950 | 23,477 |
| 96 | 262144 | 565 | 100,170 | 21,241 | 22,724 |
| 128 | 262144 | 581 | 97,489 | 18,091 | 19,629 |
duplicating via SLP to LTO5 & LTO8 in SL8500 via ACSLS
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-15-2015 11:35 AM
Ok - my angle is usually to start right at the bottom, and fully understand each layer as we work our way up towards the software layer - so that we know what is built on what... and to also fully understand the capabilities and limitations and constraints of the hardware. Here's an example, HDS VSP storage arrays have a non-blocking PCIe grid within themselves - whereas (and please do correct me if I'm wrong) EMC VMAX, Symmetrix, VNX, Clarrion do not - don't get me wrong, there's not much inherently wrong with the products of any major storage vendor (but it could be argued that some arrays are better suited to different workloads - but that's another story) - all I'm trying to do is highlight that, for example, one has to probably be a bit more careful when carving and provisioning EMC storage, i.e. there are strict internal hardware architecture pathway structures that one has to take in to consideration - if one is to get the very best out of ones hardware - and usually when we spend £1M+ on storage we like to get the very best out of it. If the limitations (and they do have limitations) are not taken into consideration, then how will an engineer ever know whether he/she has hit a hardware wall, as opposed to software wall.
But there doesn't seem much willingness to take that road. In which case, Genericus' advice can help you. At least you should find an optimum with what you've got right now.
It would take a long time to explain - but maybe a quick win would be to investigate the read/write cache within the very front of your VNX - i.e. are the massive amounts of reads for duplications causing the write cache to be squeezed - i.e. is the VNX cache in some kind of adaptive mode where it tries to adapt and respond to work levels - as opposed to being of a fixed percentage for write cache and a fixed percentage for read cache.
Most of the major storage arrays have a committed write cache - otherwise they'd just be an altogether horribly slow bunch of cheap disks... and, believe me on this one... if the write-pending-cache starts to run out of room to do it's thing... then the whole array goes to pot. I've seen big storage arrays doing huge amounts of work... which then just appear to crumble due to lack of write cache... because... when *all* writes have to move through cache, then when the cache gets squeezed then the cache *must* be emptied first... *must*... and at who's expense? Well, the writes are already suffering, but it's the reads that suffer more. In general a storage array does 20% to 30% writes, and 70% to 80% reads - so... if your writes are already suffering, then do you see how a poorly sized write cache can cause horrible side effects to read performance - i.e. 70% to 80% of the workload (the reads) is being told... hold off, hold off. But in backup land, then D2D2T backups are typically (but not always) head towards workloads of 50% write and 50% read - so there's even more pressure on the write cache.
Well, I'm sure that none of this is helping very much still... and I can only apologise for that... but I can't help but think... that as an enterprise backup admin/engineer... that we just have to have a deeper understanding of SAN and storage... because we use SAN and storage so tightly and with such heavy workloads - slamming 10's to 100's to 1000's of TB around every day, day in, day out... that if you want to understand your performance... then you have to understand your storage... and not just a few settings in software. Backup software is nothing without the hardware it sits on top of.
And here we've just spoken about one facet. We haven't even looked at the internal architecture of the VNX - or the SAN topology, front end ports, load balancing, multi-pathing policy, SAN switching, ISLs, raid groups (i.e. PG's i.e. Parity Groups), or volumes, or LUNs or striping vs concat, queue depth, or max IOPs vs max throughput.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-15-2015 12:18 PM
Genericus and WVT... (and anyone else listenning)... I have a question... does the NetBackup Client side buffer play any part in re-hyration/duplication ?
i.e. this:
https://www.veritas.com/support/en_US/article.TECH28339
...I ask for two reasons - firstly because backup-botw is quite sure that software is at fault here (i.e. the VNX disk array has been found to not be at fault)... and secondly because... whilst I am aware that shared memory is used in classic bptm parent/child hand-off of buckets of SIZE_DATA_BUFFERS... what is not clear to me is whether shared memory is used in the hand-off of re-hydrated data coming up from de-dupe before being passed over to bptm... or whether the daemons/services use TCP/IP (internally - e.g. 127.0.0.1 - or even shared short stacks) to move data, and so could the problem in this case be something in software related to moving data via network packets?
I guess my question could be better asked as... Does the NetBackup Client buffer size setting play any part in the selection of buffer size for inter-process communications during MSDP to tape duplication?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-15-2015 01:03 PM
@backup-botw - in another recent post, user deeps posted a link to this:
NetBackup Media Server Deduplication (MSDP) in the Cloud
https://www.veritas.com/support/en_US/article.000004584
...which contains a bit of useful info about the requirements of MSDP media servers, which clearly is still relevant whether the MSDP media server is situated in a cloud estate (or not).
How do the CPUs in your MSDP media servers match up to the minimum requirements? (i.e. 8 cores of 2 GHz are better for MSDP than 2 cores of 8 GHz)
Is your VNX array capable of delivering sustained minimum of 3000 IOPS for MSDP? The linked doc doesn't delineate whether this 3000 IOPs is purely for MSDP backup ingest - or whether 3000 IOPs is enough to sustain bulk MSDP ingest and bulk MSDP re-hydration - to me it would seem unlikely that anyone would be using tape in the cloud - and so, to me, it would seem that 3000 IOPs is a minimum requirement for MSDP ingest only, and thus the addition of an MSDP re-hyration workload would therefore demand a higer level of sustained IOPs. Then again Symantec/Veritas could be playing a very conservative game by quoting quite a high minimum.
.
As a separate point, here's something that I've noticed when monitoring the disk underneath MSDP... that the disk IO queue depth never gets very high... it's as if the IO layer right at the bottom of MSDP is sensitive to the response time and latency and queue depth and actively avoids swamping the disk driver/interface/HBA layer with lots of outstanding pending incomplete queued disk IO... which says to me that you could have a situation where the disks don't look overly strained, and respond at what appears fairly nice levels, but because the VNX IO is actually not that responsive (from your graphs), i.e. not sub 3ms and more around 10ms, then the CPU isn't going to get swamped - because in all honesty it's spending most of it's time waiting for the few disk IO (which have been queued/requested) to complete - and so... the issue would appear to not be a disk issue... because you can't see oodles of disk IO that are being delivered late or queueing up. It's as if MSDP is actively trying to avoid tripping itself up. I see MSDP make disks 100% busy, but the queue depth never gets very high - to me the software is avoiding requesting too many in-flight disk IOs. - with the visible net effect of not looking overstained, and not looking like a problem... but at the same time not doing very much... and yet so very capable of doing so much more if only the disk sub-system were more responsive (<3ms).
.
Anotther thing to look for... Are the media servers re-hydrating and duplicating/sending between themselves - a quick way to check is to look for "media-server-A -> media-server-B' in the 'Media Server' column in the Activity Monitor - for the duplication jobs. If you see '->' then the re-hydrated data is being sent, full fat, across the LAN from one media server (MSDP source) to another media server (tape writer) - and this could slow things down horribly and could potentially swamp your LAN NICs and or LAN switches - which are at the same time trying to move oodles of incoming backup data from clients.
- « Previous
-
- 1
- 2
- Next »
