- VOX
- Data Protection
- NetBackup
- HEEEELP!!! All jobs are hanging. Status code 811, ...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
HEEEELP!!! All jobs are hanging. Status code 811, 52, 10 etc. We have master server problem!!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-28-2017 05:53 AM
Hello guys,
We have a problem about our Netbackup platform. We've faced that problem for 1 year. But in the beginning of that problem we just changed the timeout value of clients from host properties and then we didndt receive any error just jobs hang on system for 15-30 min.
Our platform’s properties are like that:
We’re using Netbackup 8.0 and our Master server Windows, 2012 R2 (it was 2008 r2, we upgraded our master server with catalog backup but after that os upgrade we still face the issue), we have 25 media servers, 21 of them are communicating with WAN with master server, others are with LAN. 2 of them are Linux and the others windows.
We have more or less 45000 job count per day on activity monitor and we decreased the value via decreasing the frequency of tlog jobs. It was like 55000-60000.
Our platform is getting bigger day by day and now we have bigger data then before. For this reason, jobs started to hang more then before also and increasing timeout of clients didnt work after some time.
We got 811,10,52 and more timeout and hang errors on Netbackup. We made a lot of changes, i wrote some of our changes below.
-We opened a case about it. We worked with Veritas engineers like for 5 times but we couldnt find anyhting.
-We changed master server OS from 2008 R2 to 2012 R2 via catalog restore. After that restore we upgraded our Netbackup platform from 7.7.2 to 8.0. Now our master server and media servers are 8.0 but we still have 7.7.2 clients.
-We increased our master server sources. They’re now 48 GB memory and 24 processors.
-We thought that it’s about image cleanup jobs because we see when image cleanup jobs work, system hangs. But after that we realized that system is hanging also without image cleanup jobs.
-We have more or less 15 media servers that are on remote location. We re backing up servers on that remote location to that media servers and we have also duplication jobs to our central datacenter (where our master server resides) We realized that while that disk to disk duplication jobs are working, our system is hanging. If we stop the duplication jobs, we can see the system is working without any hang problem.
Now we’re thinking some solution about that duplication jobs but before that we want to learn if there is anyone live that problem before and solve it without any operational changes?
Thank you for your help.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-28-2017 07:06 AM
you didn't mention, are your master/media servers implemented on physical servers or VM?
you're using Windows, as per experience if everything else fails.. reboot! YMMV
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-28-2017 09:20 AM
I have always found that trying to do backups *and* duplications concurrently in busy environments will often throw a media server into the weeds. Are you making use of SLP Windows to manage when your duplications happen?
Without knowing more details, it really sounds like you may be asking the media servers to do too much concurrent work.
Is your disk->disk work MSDP/Puredisk dupes? Or are you duplicating from Advanced Disk pools?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-28-2017 09:45 AM
NBU master polls media servers on a regular basis. If any remote media server is not available, the master server will wait for duration of client connect timeout before going onto next media server. During this time everything will appear to hang.
Client Connect Timeout on the master should not be more than 300. Or 600 at the most.
If you cannot ensure good connectivity with WAN media servers, you need to consider making them independent master/media servers and config AIR for replication to central site.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-28-2017 11:48 PM
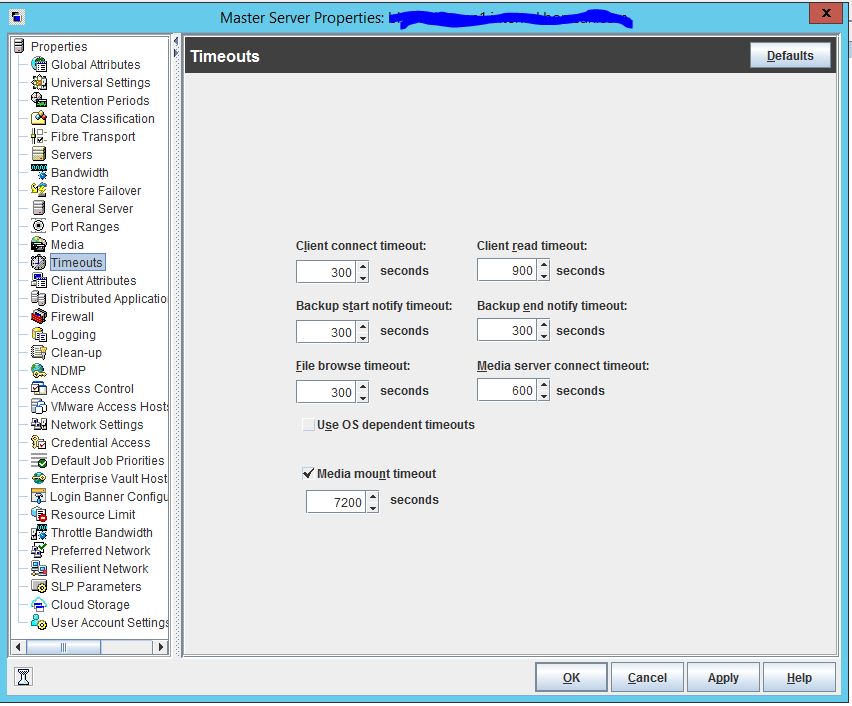
Hi Marianne, thanks for reply. On master server client connect timeout was set 300 by default. I attached timeout vaules of master server. But we changed client timeout vaules of all media servers to 3600. Because our Sql Transaction log jobs are hanging and got failed if we set timeout value to 300.
We have duplication jobs for 10 media servers from remote to our central datacenter and destination host is 5330 Veritas Appliance. Additionally they're working from 7 am to 7 pm . While that jobs are working, our system is hanging.
We thought what you suggested to us, moving data to independent master server but we want to solve this problem without change current environment, i mean with current master server. We want to take an action about disk to disk duplications and then if we see there is no another way to solve problem, we can consider taking backups via independent master server.
Thank you.
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-28-2017 11:51 PM
Master server is virtual but we have virtual and pyshical media servers. but all our remote media servers are virtual. And ofc we re rebooting master server or media servers when they re hang state but we cant do it all the time.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-29-2017 12:49 AM - edited 11-29-2017 12:50 AM
A good friend had this experience with their master server being a VM in a large organization:
Constant performance issues, despite throwing more and more resources at the VM. Eventually they had an entire ESX server dedicated to the NBU master. Still performance issues.
They eventually decided to migrate to a physical server - all well after that.
There are also specific recommendations for OS tuning on Windows servers in the NBU Performance Tuning Guide. My only problem that this guide has not been updated in recent years, so no idea if the recommendations are also valid for 2012, e.g.
Tuning the Windows file system cache
TCP KeepAliveTime parameter
TCPWindowSize and Window Scaling
MaxHashTableSize parameter
MaxUserPort parameter
etc.
There is also documentation about tuning emm.conf in a large environment, but also no idea how much is still valid in newer NBU versions. Status 52 could be a sign of overloaded resourse broker. I have also seen that network issues cause status 24, but reports eventual status code as 52 (nothing to do with media mount timeout).
Status 811 is a tell-tale that there are serious comms problems between the master and media servers.
If you run this command on a regular basis on the master, how long does it take for all media servers to respond?
nbemmcmd -getemmserver
About status 811 - this is normally a lookup problem on the master.
If you are using DNS and there are any kind of hiccup on either side, then you will see this error.
I have seen this where inconsistent hosts entries existed on the master or media server.
You want want to look at hosts entries on your master and media servers to ensure consistent name lookup.
Herewith my own experience with status 811:
https://vox.veritas.com/t5/NetBackup/Netbackup-6-5-5-Media-server-Problems/m-p/295287#M57261
Do you have some way of monitoring WAN connectivity?
The NBU Appliance has built-in Wan Optimization, but I guess nothing else in your environment, right?
For this reason, dedicated master servers at remote sites is highly recommended.
AIR is much more tolerant with WAN hiccups than duplications in same NBU domain where consistent network connectivity between master and media servers is crucial.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-29-2017 02:11 AM
We are duplicating data from puredisk to puredisk, our slp windows are working 7/24 and some of them is working between 7 am- 7 pm while trhe other jobs are working.
