- VOX
- Data Protection
- NetBackup
- Re: <16> dtcp_read: TCP - failure: recv socket (53...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
<16> dtcp_read: TCP - failure: recv socket (532) (TCP 10053: Software caused connection abort)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-13-2020 11:40 PM - edited 12-13-2020 11:51 PM
We`ve recently had a problem with our NetBackup server. Server version is 2012 r2, NetBackup version is 8.1.1, build 0103, SQL server - windows 2008R2.
The backup is configured as follows: once a week - full backup and every day - differential. For some time now, the differential has dropped out with the following error:
03:20:51.501 [11548.9348] <16> dtcp_read: TCP - failure: recv socket (532) (TCP 10053: Software caused connection abort)
03:20:51.501 [11548.9348] <16> dtcp_read: TCP - failure: recv socket (528) (TCP 10058: Can't send after socket shutdown)
First, after a full backup was performed once a week, a differential backup was made for a couple of days, and then an error appeared and up to a full backup, the differential was not performed with just such an error.
And now, for a couple of weeks, even after a full backup, the differential has stopped performing altogether.
Since I am newbe to servicing this kind of servers, in 2 weeks I have read many publications on similar topics here and on other sites, but the proposed solutions did not help.
If you need bptm, bpkar or others logs, I'm ready to post them here, and it would be much appratiated if I am told what parts of logs are needed, because they are way too big.
Again, I'm a beginner, therefore, in order not to clutter up the forum with long posts, I ask you to help and tell what logs are needed for analysis. Log level was set to max - 5.
The bundle is standard - NetBackup + SQL. NetBackup version 8.1.1 and SQL - 2008R2.
The errors are the same in the logs on the SQL server and on the Netbackup server.
I no longer know what to do.
Please advise.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-15-2020 01:16 AM
not related, the client read timeout is a timer, that tells Netbackup, how long to wait for client to send new data, before connection is considered broken.
It is like a phone conversation, where peer stop talking in the middel of a sentence, and you go "hello ... hello.....Helllooooo" and then decide to hang-up.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-15-2020 01:18 AM
I have honestly NEVER seen increase in timeouts causing this. Unless the OS is running out of TCP ports.
Always a good idea to monitor jobs when a change is made. As I've said yesterday - I have spent many nights at customer sites to try and figure out what is causing the issue. Mostly OS, network, storage, etc... etc... causing NBU to fail.
NBU is mostly only reporting the problem, not causing the problem.
bpps command is in the netbackup\bin directory. Not admincmd.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-15-2020 02:09 AM - edited 12-15-2020 10:05 PM
Thank you for your efforts anyway ))) may be its my good chance to change job )))
meanwhile, i attached yesterday` logs. If you be so kind to have a look at them, i ll be the happiest persion on earth ))
thank you
oh, and I posted the output of the bpps command in my previous post in case you missed it ... Sorry, I just read your previous post wrong and missed the way to find the command.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-15-2020 02:18 AM
You did not post or include Job Details in the logs.
As per yesterday's post:
When you upload logs, be sure to include all text in Job Details of the failed job.
Job Details is important because it gives us PIDs and timestamps to trace in the relevant logs.
Please have a look at my post over here about reading logs:
https://vox.veritas.com/t5/NetBackup/How-to-use-logs/m-p/447331#M98462
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-15-2020 02:26 AM
Please, kindly advise where can i find Job Details?
I ve read your post yesterday but my stupidity wouldnt allow me to have a clue about where to find job details, sorry for that...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-15-2020 02:29 AM - edited 12-15-2020 02:37 AM
Looking at bpps output, all required NBU processes are running, but there seems to be way too many nbproxy and bpjava-susvc processes running. and 2 x dbsrv16.
I found a (badly written) article of 10 years ago that describes a similar issue : https://www.veritas.com/support/en_US/article.100021358
Please see if anything here is relevant - especially netstat output to see if there are many ports in TIME_WAIT (or CLOSE_WAIT) status.
If so, I recommend a reboot of the NBU server.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-15-2020 02:36 AM
@captain_harlock wrote:
Please, kindly advise where can i find Job Details?
I ve read your post yesterday but my stupidity wouldnt allow me to have a clue about where to find job details, sorry for that...
In Activity Monitor, click on a failed job that you want assistance with.
(We need to be sure that this failed job will be included in the logs that you collected.)
When you open the failed job, the 1st tab is Job Overview.
The 2nd tab is Job Details.
Please copy all the text.
https://www.veritas.com/content/support/en_US/doc/18716246-126559472-0/v40698062-126559472
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-15-2020 02:43 AM - edited 12-15-2020 10:03 PM
I run netstat -a and all i could see were a bunch of TIME_WAITs and a lot of ESTABLISHEDs... No proxy connections at all...
Thank you for pointing me out to Job Details.
1 error:
Dec 14, 2020 3:11:31 AM - Info nbjm (pid=3264) starting backup job (jobid=60800) for client SQL1, policy Vault_1_Backup, schedule Differential-Inc
Dec 14, 2020 3:11:31 AM - Info nbjm (pid=3264) requesting STANDARD_RESOURCE resources from RB for backup job (jobid=60800, request id:{9376A951-A07E-4069-B41F-A2BE4740FFFA})
Dec 14, 2020 3:11:31 AM - requesting resource __ANY__
Dec 14, 2020 3:11:31 AM - requesting resource roa1.hm.local.NBU_CLIENT.MAXJOBS.SQL1
Dec 14, 2020 3:11:31 AM - requesting resource roa1.hm.local.NBU_POLICY.MAXJOBS.Vault_1_Backup
Dec 14, 2020 3:11:31 AM - awaiting resource Any. No drives are available.
Dec 14, 2020 3:19:54 AM - granted resource roa1.hm.local.NBU_CLIENT.MAXJOBS.SQL1
Dec 14, 2020 3:19:54 AM - granted resource roa1.hm.local.NBU_POLICY.MAXJOBS.Vault_1_Backup
Dec 14, 2020 3:19:54 AM - granted resource 6135L6
Dec 14, 2020 3:19:54 AM - granted resource HP.Ultrium6-SCSI.001
Dec 14, 2020 3:19:54 AM - granted resource roa1-hcart3-robot-tld-0
Dec 14, 2020 3:19:54 AM - estimated 704439 kbytes needed
Dec 14, 2020 3:19:54 AM - Info nbjm (pid=3264) started backup (backupid=dfs2_1607905194) job for client SQL1, policy Vault_1_Backup, schedule Differential-Inc on storage unit roa1-hcart3-robot-tld-0
Dec 14, 2020 3:19:54 AM - started process bpbrm (pid=19380)
Dec 14, 2020 3:19:55 AM - Info bpbrm (pid=19380) SQL1 is the host to backup data from
Dec 14, 2020 3:19:55 AM - Info bpbrm (pid=19380) reading file list for client
Dec 14, 2020 3:19:56 AM - connecting
Dec 14, 2020 3:19:58 AM - Info bpbrm (pid=19380) starting bpbkar32 on client
Dec 14, 2020 3:19:59 AM - connected; connect time: 0:00:00
Dec 14, 2020 3:20:00 AM - Info bpbkar32 (pid=9532) Backup started
Dec 14, 2020 3:20:00 AM - Info bpbkar32 (pid=9532) change time comparison:<disabled>
Dec 14, 2020 3:20:00 AM - Info bpbkar32 (pid=9532) archive bit processing:<enabled>
Dec 14, 2020 3:20:00 AM - Info bptm (pid=14984) start
Dec 14, 2020 3:20:00 AM - Info bptm (pid=14984) using 65536 data buffer size
Dec 14, 2020 3:20:00 AM - Info bptm (pid=14984) setting receive network buffer to 263168 bytes
Dec 14, 2020 3:20:00 AM - Info bptm (pid=14984) using 30 data buffers
Dec 14, 2020 3:20:00 AM - Info bptm (pid=14984) start backup
Dec 14, 2020 3:20:00 AM - Info bptm (pid=20708) start
Dec 14, 2020 3:20:00 AM - Info bptm (pid=14984) backup child process is pid 20708.21276
Dec 14, 2020 3:20:01 AM - Error bpbrm (pid=19380) from client rs1dfs2: ERR - Can't open object. Aborting backup: Enterprise Vault Resources:\EV Site (HM (SQL1))\EV Vault Store Group (HMStore)\EV Vault Store (JRStorage)\Vault Store DB (SQL1/EVVSJRStorage_6)\EVVSJRStorage_6 (BEDS 0xE000FEA9: The Backup Exec data store encountered a problem during the operation. See the job log for details.).
Dec 14, 2020 3:20:01 AM - Error bptm (pid=20708) socket operation failed - 10054 (at ../child.c.1287)
Dec 14, 2020 3:20:01 AM - Error bptm (pid=20708) unable to perform read from client socket, connection may have been broken
Dec 14, 2020 3:20:01 AM - Info bptm (pid=14984) media id 6135L6 mounted on drive index 1, drivepath {2,0,1,0}, drivename HP.Ultrium6-SCSI.001, copy 1
Dec 14, 2020 3:20:01 AM - mounted 6135L6
Dec 14, 2020 3:20:01 AM - positioning 6135L6 to file 20
Dec 14, 2020 3:20:03 AM - positioned 6135L6; position time: 0:00:02
Dec 14, 2020 3:20:03 AM - begin writing
Dec 14, 2020 3:20:16 AM - Error bpbrm (pid=19380) could not send server status message to client
Dec 14, 2020 3:20:18 AM - Info bpbkar32 (pid=9532) done. status: 13: file read failed
Dec 14, 2020 3:20:18 AM - end writing; write time: 0:00:15
file read failed (13)
2 error
Dec 14, 2020 3:11:32 AM - Info nbjm (pid=3264) starting backup job (jobid=60801) for client SQL1, policy Vault_1_Backup, schedule Differential-Inc
Dec 14, 2020 3:11:32 AM - Info nbjm (pid=3264) requesting STANDARD_RESOURCE resources from RB for backup job (jobid=60801, request id:{9CB83C3E-96B7-455D-B359-CD9F92A9AC6F})
Dec 14, 2020 3:11:32 AM - requesting resource __ANY__
Dec 14, 2020 3:11:32 AM - requesting resource roa1.hm.local.NBU_CLIENT.MAXJOBS.SQL1
Dec 14, 2020 3:11:32 AM - requesting resource roa1.hm.local.NBU_POLICY.MAXJOBS.Vault_1_Backup
Dec 14, 2020 3:11:32 AM - awaiting resource Any. No drives are available.
Dec 14, 2020 3:20:18 AM - granted resource roa1.hm.local.NBU_CLIENT.MAXJOBS.SQL1
Dec 14, 2020 3:20:18 AM - granted resource roa1.hm.local.NBU_POLICY.MAXJOBS.Vault_1_Backup
Dec 14, 2020 3:20:18 AM - granted resource 6135L6
Dec 14, 2020 3:20:18 AM - granted resource HP.Ultrium6-SCSI.001
Dec 14, 2020 3:20:18 AM - granted resource roa1-hcart3-robot-tld-0
Dec 14, 2020 3:20:18 AM - estimated 929712 kbytes needed
Dec 14, 2020 3:20:18 AM - Info nbjm (pid=3264) started backup (backupid=dfs2_1607905218) job for client SQL1, policy Vault_1_Backup, schedule Differential-Inc on storage unit roa1-hcart3-robot-tld-0
Dec 14, 2020 3:20:18 AM - started process bpbrm (pid=19608)
Dec 14, 2020 3:20:20 AM - Info bpbrm (pid=19608) SQL1 is the host to backup data from
Dec 14, 2020 3:20:20 AM - Info bpbrm (pid=19608) reading file list for client
Dec 14, 2020 3:20:21 AM - connecting
Dec 14, 2020 3:20:23 AM - Info bpbrm (pid=19608) starting bpbkar32 on client
Dec 14, 2020 3:20:24 AM - Info bpbkar32 (pid=8556) Backup started
Dec 14, 2020 3:20:24 AM - Info bpbkar32 (pid=8556) change time comparison:<disabled>
Dec 14, 2020 3:20:24 AM - Info bpbkar32 (pid=8556) archive bit processing:<enabled>
Dec 14, 2020 3:20:24 AM - connected; connect time: 0:00:00
Dec 14, 2020 3:20:25 AM - Info bptm (pid=18244) start
Dec 14, 2020 3:20:25 AM - Info bptm (pid=18244) using 65536 data buffer size
Dec 14, 2020 3:20:25 AM - Info bptm (pid=18244) setting receive network buffer to 263168 bytes
Dec 14, 2020 3:20:25 AM - Info bptm (pid=18244) using 30 data buffers
Dec 14, 2020 3:20:25 AM - Info bptm (pid=18244) start backup
Dec 14, 2020 3:20:25 AM - Info bptm (pid=18736) start
Dec 14, 2020 3:20:25 AM - Info bptm (pid=18244) backup child process is pid 18736.18496
Dec 14, 2020 3:20:25 AM - Error bpbrm (pid=19608) from client dfs2: ERR - Can't open object. Aborting backup: Enterprise Vault Resources:\EV Site (HM (SQL1))\EV Vault Store Group (HMStore)\EV Vault Store (MXStore)\Vault Store DB (SQL1/EVVSMXStore_2)\EVVSMXStore_2 (BEDS 0xE000FEA9: The Backup Exec data store encountered a problem during the operation. See the job log for details.).
Dec 14, 2020 3:20:25 AM - Error bptm (pid=18736) socket operation failed - 10054 (at ../child.c.1287)
Dec 14, 2020 3:20:25 AM - Error bptm (pid=18736) unable to perform read from client socket, connection may have been broken
Dec 14, 2020 3:20:25 AM - Info bptm (pid=18244) media id 6135L6 mounted on drive index 1, drivepath {2,0,1,0}, drivename HP.Ultrium6-SCSI.001, copy 1
Dec 14, 2020 3:20:25 AM - mounted 6135L6
Dec 14, 2020 3:20:25 AM - positioning 6135L6 to file 20
Dec 14, 2020 3:20:27 AM - positioned 6135L6; position time: 0:00:02
Dec 14, 2020 3:20:27 AM - begin writing
Dec 14, 2020 3:20:40 AM - Error bpbrm (pid=19608) could not send server status message to client
Dec 14, 2020 3:20:42 AM - Info bpbkar32 (pid=8556) done. status: 13: file read failed
Dec 14, 2020 3:20:42 AM - end writing; write time: 0:00:15
file read failed (13)
3 error
Dec 14, 2020 3:15:00 AM - Info nbjm (pid=3264) starting backup job (jobid=60802) for client SQL1, policy Vault_1_Backup, schedule Differential-Inc
Dec 14, 2020 3:15:00 AM - Info nbjm (pid=3264) requesting STANDARD_RESOURCE resources from RB for backup job (jobid=60802, request id:{CF8622FC-4FA3-4E50-BFA7-85DF3F2B29F9})
Dec 14, 2020 3:15:00 AM - requesting resource __ANY__
Dec 14, 2020 3:15:00 AM - requesting resource roa1.hm.local.NBU_CLIENT.MAXJOBS.SQL1
Dec 14, 2020 3:15:00 AM - requesting resource roa1.hm.local.NBU_POLICY.MAXJOBS.Vault_1_Backup
Dec 14, 2020 3:15:00 AM - awaiting resource Any. No drives are available.
Dec 14, 2020 3:20:25 AM - granted resource roa1.hm.local.NBU_CLIENT.MAXJOBS.RS1SQL1
Dec 14, 2020 3:20:25 AM - granted resource roa1.hm.local.NBU_POLICY.MAXJOBS.Vault_1_Backup
Dec 14, 2020 3:20:25 AM - granted resource 6158L6
Dec 14, 2020 3:20:25 AM - granted resource HP.Ultrium6-SCSI.000
Dec 14, 2020 3:20:25 AM - granted resource roa1-hcart3-robot-tld-0
Dec 14, 2020 3:20:25 AM - estimated 277056 kbytes needed
Dec 14, 2020 3:20:25 AM - Info nbjm (pid=3264) started backup (backupid=dfs2_1607905225) job for client SQL1, policy Vault_1_Backup, schedule Differential-Inc on storage unit roa1-hcart3-robot-tld-0
Dec 14, 2020 3:20:26 AM - started process bpbrm (pid=18532)
Dec 14, 2020 3:20:27 AM - Info bpbrm (pid=18532) SQL1 is the host to backup data from
Dec 14, 2020 3:20:27 AM - Info bpbrm (pid=18532) reading file list for client
Dec 14, 2020 3:20:28 AM - connecting
Dec 14, 2020 3:20:30 AM - Info bpbrm (pid=18532) starting bpbkar32 on client
Dec 14, 2020 3:20:31 AM - connected; connect time: 0:00:00
Dec 14, 2020 3:20:32 AM - Info bpbkar32 (pid=11548) Backup started
Dec 14, 2020 3:20:32 AM - Info bpbkar32 (pid=11548) change time comparison:<disabled>
Dec 14, 2020 3:20:32 AM - Info bpbkar32 (pid=11548) archive bit processing:<enabled>
Dec 14, 2020 3:20:32 AM - Info bptm (pid=15316) start
Dec 14, 2020 3:20:32 AM - Info bptm (pid=15316) using 65536 data buffer size
Dec 14, 2020 3:20:32 AM - Info bptm (pid=15316) setting receive network buffer to 263168 bytes
Dec 14, 2020 3:20:32 AM - Info bptm (pid=15316) using 30 data buffers
Dec 14, 2020 3:20:32 AM - Info bptm (pid=15316) start backup
Dec 14, 2020 3:20:32 AM - Info bptm (pid=21432) start
Dec 14, 2020 3:20:32 AM - Info bptm (pid=15316) backup child process is pid 21432.18472
Dec 14, 2020 3:20:32 AM - Error bpbrm (pid=18532) from client dfs2: ERR - Can't open object. Aborting backup: Enterprise Vault Resources:\EV Site (HM (SQL1))\EV Vault Store Group (HMStore)\FingerPrint Databases\FingerPrint DB (SQL1/EVVSGEVStore_1_1)\EVVSGEVStore_1_1 (BEDS 0xE000FEA9: The Backup Exec data store encountered a problem during the operation. See the job log for details.).
Dec 14, 2020 3:20:32 AM - Error bptm (pid=21432) socket operation failed - 10054 (at ../child.c.1287)
Dec 14, 2020 3:20:32 AM - Error bptm (pid=21432) unable to perform read from client socket, connection may have been broken
Dec 14, 2020 3:20:32 AM - Info bptm (pid=15316) media id 6158L6 mounted on drive index 0, drivepath {2,0,0,0}, drivename HP.Ultrium6-SCSI.000, copy 1
Dec 14, 2020 3:20:32 AM - mounted 6158L6
Dec 14, 2020 3:20:32 AM - positioning 6158L6 to file 120
Dec 14, 2020 3:20:34 AM - positioned 6158L6; position time: 0:00:02
Dec 14, 2020 3:20:34 AM - begin writing
Dec 14, 2020 3:20:48 AM - Error bpbrm (pid=18532) could not send server status message to client
Dec 14, 2020 3:20:50 AM - Info bpbkar32 (pid=11548) done. status: 13: file read failed
Dec 14, 2020 3:20:50 AM - end writing; write time: 0:00:16
file read failed (13)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-15-2020 02:51 AM - edited 12-15-2020 09:58 PM
Here is another one (marked as "from EV server"):
Dec 14, 2020 3:00:08 AM - Info nbjm (pid=3264) starting backup job (jobid=60797) for client dfs2, policy Vault_1_Backup, schedule Differential-Inc
Dec 14, 2020 3:00:08 AM - Info nbjm (pid=3264) requesting MEDIA_SERVER_ONLY resources from RB for backup job (jobid=60797, request id:{B16B389F-66F6-45EF-B9CC-FEB5A63ADE24})
Dec 14, 2020 3:00:08 AM - requesting resource __ANY__
Dec 14, 2020 3:00:08 AM - requesting resource roa1.hm.local.NBU_CLIENT.MAXJOBS.dfs2
Dec 14, 2020 3:00:08 AM - requesting resource roa1.hm.local.NBU_POLICY.MAXJOBS.Vault_1_Backup
Dec 14, 2020 3:00:08 AM - granted resource roa1.hm.local.NBU_CLIENT.MAXJOBS.rs1dfs2
Dec 14, 2020 3:00:08 AM - granted resource roa1.hm.local.NBU_POLICY.MAXJOBS.Vault_1_Backup
Dec 14, 2020 3:00:09 AM - estimated 14004123 kbytes needed
Dec 14, 2020 3:00:09 AM - begin Parent Job
Dec 14, 2020 3:00:09 AM - begin Enterprise Vault Quiesce: Step By Condition
Operation Status: 0
Dec 14, 2020 3:00:09 AM - end Enterprise Vault Quiesce: Step By Condition; elapsed time 0:00:00
Dec 14, 2020 3:00:09 AM - begin Enterprise Vault Quiesce: Read File List
Operation Status: 0
Dec 14, 2020 3:00:09 AM - end Enterprise Vault Quiesce: Read File List; elapsed time 0:00:00
Dec 14, 2020 3:00:09 AM - begin Enterprise Vault Quiesce: Quiesce
Dec 14, 2020 3:00:09 AM - started process bpbrm (pid=14952)
Dec 14, 2020 3:01:19 AM - end writing
Operation Status: 0
Dec 14, 2020 3:01:19 AM - end Enterprise Vault Quiesce: Quiesce; elapsed time 0:01:10
Dec 14, 2020 3:01:19 AM - begin Enterprise Vault Quiesce: Policy Execution Manager Preprocessed
Dec 14, 2020 3:20:50 AM - begin Enterprise Vault Quiesce: UnQuiesce
Operation Status: 13
Dec 14, 2020 3:20:50 AM - end Enterprise Vault Quiesce: UnQuiesce; elapsed time 0:00:00
Dec 14, 2020 3:20:50 AM - started process bpbrm (pid=17240)
Dec 14, 2020 3:21:03 AM - end writing
Operation Status: 0
Dec 14, 2020 3:21:03 AM - end Enterprise Vault Quiesce: Policy Execution Manager Preprocessed; elapsed time 0:19:44
Operation Status: 13
Dec 14, 2020 3:21:03 AM - end Parent Job; elapsed time 0:20:54
file read failed (13)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-15-2020 03:17 AM - edited 12-15-2020 03:18 AM
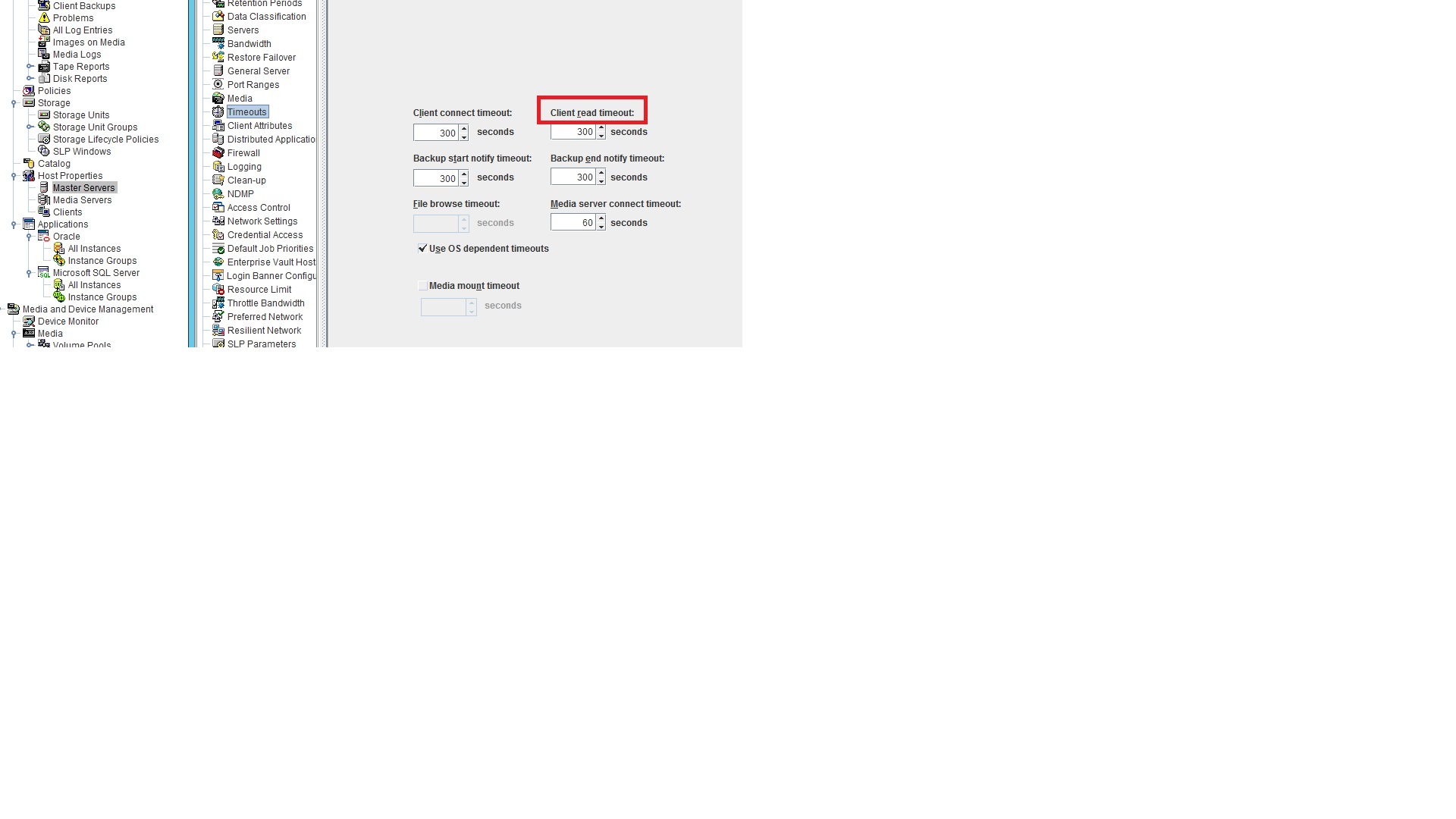{kind=link}
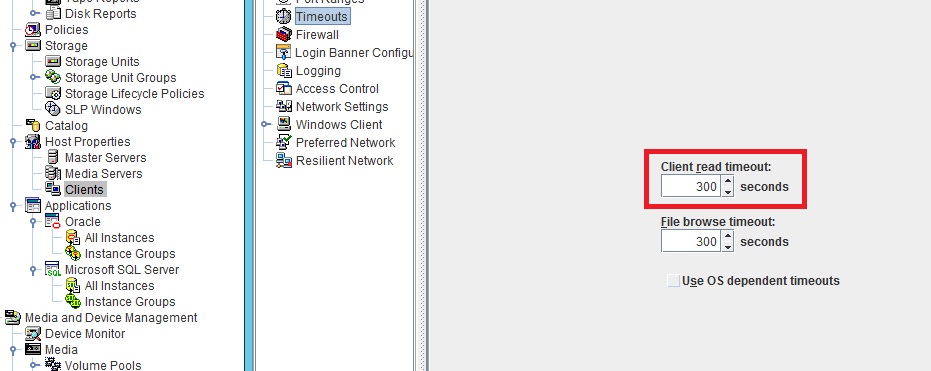{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-15-2020 04:05 AM
No, the Client Read timeout should not be changed on NBU Clients.
Only the master/media server setting.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-15-2020 04:49 AM
so, if i understand correctly, i should change only the value on the master server (its the medea server also) as it is on screenshot 1?
Any chance to find info in those error texts i ve posted?
Millions thanks for help!))
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-15-2020 05:39 AM
Thank you for the job details.
I am looking at the logs for the 1st failed job.
bpbrm PID 19380 on the master/media server : started process bpbrm (pid=19380)
bpbkar PID 9532 on the SQL client: Info bpbkar32 (pid=9532) Backup started
The 1st problem that I have with the logs is that the client logging level is too high - level 5.
BPBKAR_VERBOSE Debug log level: Actual=5, Effective=5
So, bpbkar logs way too much - as a 'regular' NBU user with a litlle bit of experience, there is LOT of information in bpbkar log. Some of the entries look like errors, but I have no idea if they are relevant to the issue or simply 'red herrings' that means nothing and not an issue.
If you look at all lines containing [9532. in bpbkar log, you will see what I mean.
(This is one of the reasons why I say that level 5 logs should only be sent to trained Veritas Support engineers. )
We see in bpbkar log that the backup process is started at 03:20:00.
Lots of entries later, at 3:20:01.402, we see that the setup completed and CONTINUE BACKUP message received.
03:20:01.683 [9532.9680] <2> tar_backup_tfi::setupFileDirectives: TAR - backup filename = Enterprise Vault Resources:\EV Site (HMMR (RS1SQL1))\EV Vault Store Group (HMMRStore)\EV Vault Store (JRStorage)\Vault Store DB (RS1SQL1/EVVSJRStorage_6)\
Then we see that KeepAlive is set to 60 seconds (this could be a problem):
03:20:01.683 [9532.9680] <4> tar_base::startKeepaliveThread: INF - set keepalive thread interval to 60 seconds
@captain_harlock Do you know the this OS setting was changed manually to 60 seconds at some point in time?
I found an article that says the following:
The default TCP keepalive time interval in Windows is 2 hours (but recommended are 5 minutes). It can be set in the HKLM\System\CurrentControlSet\Services\Tcpip\Parameters\KeepAliveTime registry key.
Anyhow, bpbkar log carries on and on and on through timestamp 03:20:01.###
Here we see something that might be an issue:
03:20:01.977 [9532.9680] <2> ov_log::V_GlobalLogEx: ERR - enterprise_vault_sql_access::V_OpenForRead() FS_EXTENDED_ERROR on FS_OpenObj() Result:0xE0000363 Action:0x2 Error_id:0x2D4A
03:20:01.977 [9532.9680] <4> tar_base::V_vTarMsgW: INF - tar message received from dos_backup::tfs_readopen
03:20:01.977 [9532.9680] <2> tar_base::V_vTarMsgW: ERR - Can't open object. Aborting backup: Enterprise Vault Resources:\EV Site (HMMR (RS1SQL1))\EV Vault Store Group (HMMRStore)\EV Vault Store (JRStorage)\Vault Store DB (RS1SQL1/EVVSJRStorage_6)\EVVSJRStorage_6 (BEDS 0xE000FEA9: The Backup Exec data store encountered a problem during the operation. See the job log for details. ).
(Please ignore the Backup Exec reference - NBU and BE use common code for certain processes)
After this we see backup failure and socket errors:
03:20:01.998 [9532.9680] <2> ov_log::V_GlobalLogEx: KeepAliveThread::isKeepAliveRunning keep alive not running: 2
03:20:01.998 [9532.9680] <16> dtcp_read: TCP - failure: recv socket (524) (TCP 10053: Software caused connection abort)
Master/media server logging level is too low - level 0.
bpbrm main: INITIATING (VERBOSE = 0): version NetBackup 8.1.1 2018020320
There is very little info in bpbrm log - just what we see in Job Details.
ERR - Can't open object. Aborting backup: Enterprise Vault Resources:\EV Site (HMMR (RS1SQL1))\EV Vault Store Group (HMMRStore)\EV Vault Store (JRStorage)\Vault Store DB (RS1SQL1/EVVSJRStorage_6)\EVVSJRStorage_6
Long story short - I cannot say what is causing the problem.
We know that it is not a timeout - the backup fails in less than 1 minute.
Please start by checking EV logs and SQL logs, including Event Viewer logs. The only errors we see is that the database cannot be opened, and then the socket errors.
Your other option is to log a call with Veritas Support.
Not sure what the reaction will be if they hear what the EV version is...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-15-2020 09:55 PM - edited 12-21-2020 02:13 AM
Dear Marianne
Thank you very much indeed for your help. )
Yesterday I brought all the verbose levels to 3, so now I attached fresh log files.
As for KeepAlive sensor I didnt risk to change anything for now, before its absolutely clear if it can solve the problem.
To say about Event Viewer logs on all the servers - still there are no errors connected to the problem...
The option to call Veritas Support is not suitable for now, because this version of sw that we use is no longer supported. There were plans to upgrade the stack but not now...
I attached fresh logs to this post.
Thank you for your efforts ) You are really helping me!
ps: I found some errors on EV server, that could be related to this case:
Volume Shadow Copy Service information: The COM Server with CLSID {122e0bab-dae0-4285-b708-eb4974409279} and name HWPRV cannot be started. [0x80070422, The service cannot be started, either because it is disabled or because it has no enabled devices associated with it.
]
Operation:
Creating instance of hardware provider
Obtain a callable interface for this provider
List interfaces for all providers supporting this context
Check If Volume Is Supported by Provider
error 13
Volume Shadow Copy Service error: Error creating the Shadow Copy Provider COM class with CLSID {122e0bab-dae0-4285-b708-eb4974409279} [0x80070422, The service cannot be started, either because it is disabled or because it has no enabled devices associated with it.
].
Operation:
Creating instance of hardware provider
Obtain a callable interface for this provider
List interfaces for all providers supporting this context
Check If Volume Is Supported by Provider
Context:
Provider ID: {bd04cbf9-212c-4553-9ea5-c5bfb05ccc8f}
Provider ID: {bd04cbf9-212c-4553-9ea5-c5bfb05ccc8f}
Class ID: {122e0bab-dae0-4285-b708-eb4974409279}
Snapshot Context: 9
Snapshot Context: 9
Execution Context: Coordinator
Provider ID: {00000000-0000-0000-0000-000000000000}
error 12292
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-16-2020 10:42 PM
I still humbly hope to get some help with this wierd product.
Any help would be appreciated ...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-16-2020 11:04 PM
There is nothing weird about this product. Take some time and start reading manuals (for me it meant night-time reading when I was new to NetBackup).
Ask your management for training - if classroom training is not an option, there is virtual classroom training.
One thing you need to understand about NBU (and any other backup product) is that it there are a lot of environment factors involved that can cause issues.
You have seen VSS errors. Not sure if you know this, but VSS is part of Microsoft OS.
VSS failures can cause backups to fail.
You need to work with Microsoft to fix that.
Normally a reboot is a quick fix.
If this becomes a regular issue, look for MS hotfixes.
You can also reboot the NBU master server to clear out stale TCP port connections.
I will look at the logs when/if time permits.
Reading logs takes up a lot of my time - best if you also take the time to read logs. I have shared a link previously where I explain how I read logs.
Please also understand that I have a good deal of experience with NBU, but NOT with EV.
You ideally need someone with experience of both.
You have every right to go to your management and say to them that you need help.
They should know what the situation is with your Veritas maintenance contracts for NBU and EV.
If your NBU maintenance is up to date, you can still log a call for NBU support.
Another option would be to look around for a Veritas Partner near you with both NBU and EV skills.
They might be willing to assist at a fee.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-16-2020 11:09 PM - edited 12-16-2020 11:10 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-17-2020 03:47 AM
Hey
I see that @Marianne found out this error TCP 10053: Software caused connection abort) - from my exprience when I see such I am asking wintel team to upgrade drivers for NIC on the client as well am forcing them to check also NIC's firmware if there is no newer one... Maybe this here it is not needed - but if there are any newer I would opted for these to be upgraded.
Also you should checked the same on your master and media - just in case...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-17-2020 11:35 PM - edited 12-17-2020 11:41 PM
thank you for your reply )
All the servers are virtual, and before 3 weeks ago everything run like a charm. Nobody touched nothing and I mean it ) because no one has the apropriate knowledge to do anything.
I met this backup software here for the first time in my life 3 months ago for the whole 20 years of my it admin career. ) And I also have no proper knowledge in administering this software. I used Bacula and its forks in my backups, Veam also, and I could imagine that I could administer these SW )) I also have no time and training environment to properly study NetBackup to quikly eleminate this error. Sorry for that 'cry of soul'.
So I am absolutely sure nobody touched nothing )
Its strictly forbidden to reboot or/and to update computers in a productive environment at any time, unless there are serious errors interfering with work, by the company law . So there were no updates, upgrades etc. Why would any of the network cards go wrong? I cheked and re-cheked everything.
I have only a clue that the VSS error I posted above could give me hard times... Because it could somehow be connected to the netbackup. The error is about vss providers, and one of them - faulty one, is the HP StorageWorks P2000/MSA2000 VSS Provider.
But i am not sure if it is connected to the netbackup problems...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-21-2020 02:16 AM - edited 12-21-2020 02:16 AM
I eliminated VSS errors. but still, no changes in backup through NetBackup...
- Custom NDMP Port - Backup Exec 20.4 in Backup Exec
- Something Cool with NBU - Part Two! - Status 59 and your BP.Conf File in NetBackup
- SLP fail on a specific mdsp in NetBackup
- NetBackup and Pure Storage Faster//Better in NetBackup
- Moved to Software Defined Networking and seeing dropped connections from Master to VM clients in NetBackup
