- VOX
- Availability
- Storage Foundation for Windows
- here are the screenshots. The
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-04-2012 08:31 AM
Hi all,
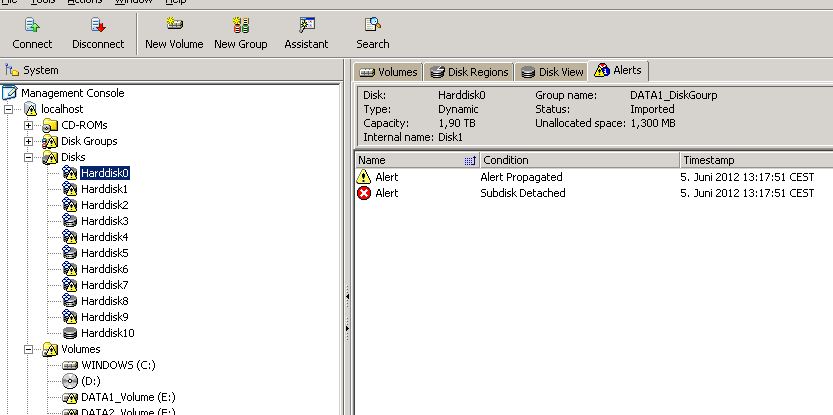
we have a veritas enterprise administrator runnning on windows 2003 server cluster running. Now i see an exclamation mark on some volumes and hd's. If opne a volume and see one of the disks i see this alerts:
Warning V-76-58645-1000
Aler Propagated
and
Error V-76-58645-1080
Subdisk Detached
If i take a look on my SAN it seems that all HD's are ok.
At the moment I'm not really know what it means and what i have to do. Can anyone help me here?
Or i have just to reactivate the harddisks? or just du cluster turn to the other cluster node?
Thank you very much!
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-05-2012 02:00 PM
No errors from HBA driver or vxio errors in System log?
You are not really giving us much to work with...
The Yellow exclamation is a warning - normaly seen as a result of connectivity or I/O issue. I would expect some sort of evidence in Event Viewer logs.
Extract from 5.1 admin guide:
Warning. The yellow caution symbol indicates there is a potential problem but the system can still function normally.
This is in line with what you are seeing - all data seem to be accessible.
What seems weird is the fact that FIVE different harddisks are all showing internal name as disk1.
If you can afford downtime on your cluster, please offline the cluster group, then try to manually deport and import diskgroup. See if that makes a difference.
I am a bit hesitant to suggest too many 'remedial' actions because you are out of support...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-05-2012 01:07 AM
Please check Windows System and Application logs for errors.
It sounds as if the server has lost connectivity from OS perspective.
What happens if you go to Actions - Rescan?
Hopefully you have mentioned VEA version and not SFW version?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-05-2012 04:21 AM
Hi Marianne,
thanks for your reply. In the windows event logs i see some error's for one day.
Failed to deport cluster dynamic disk roup Data1-Diskgroup and for some other goups.
Action Rescan - do nothing.
If I open help - info - it shows me the Veritas Enterprise Administrator V 3.2.542.0
What is about just reactiveate the disk? Go ti Mangment COnsole - Disks- and right click on the error disk - and just "Reactivate Disk" or you think it will bring me in some trouble to do this? Beacuase at the moment all the volumes are online for the endusers.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-05-2012 06:26 AM
To fix your current problem, we need to understand what caused the problem and what that disk status is.
Please check System Log as well for for errors. 'Failed to deport' is a symptom as a result of 'something else'.
Please also post a screenshot of Disk View that shows the Status for all disks?
PS:
If we look at this table: http://www.symantec.com/docs/TECH24718 VEA version 3.2.542 is SFW version 4.3 MP1.
All SFW 4.x versions reached EOSL about a year ago: http://www.symantec.com/docs/TECH50624
Any reason why you are running a Cluster (that assumes Critical application) on unsupported software?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-05-2012 06:43 AM
here are the screenshots.
The only thing i see in my smtp tool is the cluster node was changed at this time. Maybe the connection was down for a short time and the cluster service ahs changed the cluster node and something goes wrong with the SFW.
PS. We will replace the hardware so we have to wait at the moment.
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-05-2012 07:54 AM
Apologies for misunderstanding.
Please click on Disks in left pane so that we can see all harddisks in the right pane with status of each disk.
Similar to my attachment...
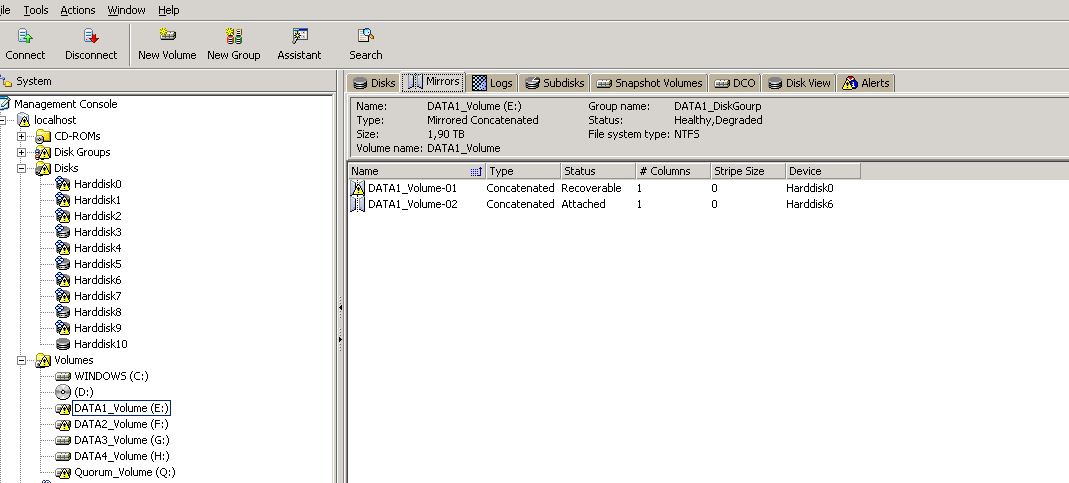
You seem to have FlashSnap mirrors for your volumes. as long as one copy of the data volume is fine, the data will be accessible to end-users.
I would also like to see the 'Mirrors' tab for one of these volumes.
PLEASE check System log for errors?
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-05-2012 08:35 AM
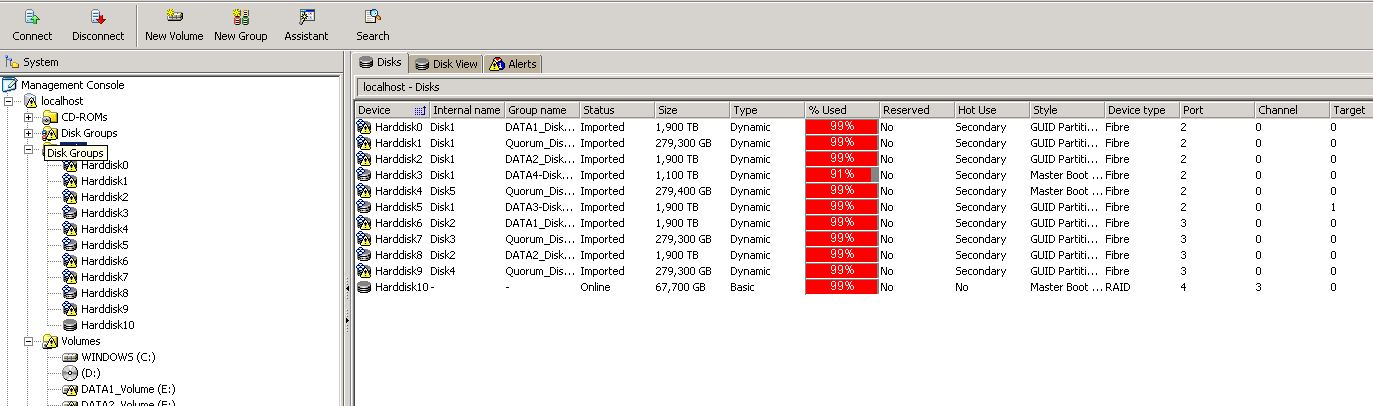
cool :)
here it is
The sytsem logs says me that: Cluster share "DATA1-Share" couldn't checked for status Error :1450
But it seems like a result of the error not the evnet why it happened
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-05-2012 02:00 PM
No errors from HBA driver or vxio errors in System log?
You are not really giving us much to work with...
The Yellow exclamation is a warning - normaly seen as a result of connectivity or I/O issue. I would expect some sort of evidence in Event Viewer logs.
Extract from 5.1 admin guide:
Warning. The yellow caution symbol indicates there is a potential problem but the system can still function normally.
This is in line with what you are seeing - all data seem to be accessible.
What seems weird is the fact that FIVE different harddisks are all showing internal name as disk1.
If you can afford downtime on your cluster, please offline the cluster group, then try to manually deport and import diskgroup. See if that makes a difference.
I am a bit hesitant to suggest too many 'remedial' actions because you are out of support...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-06-2012 04:02 AM
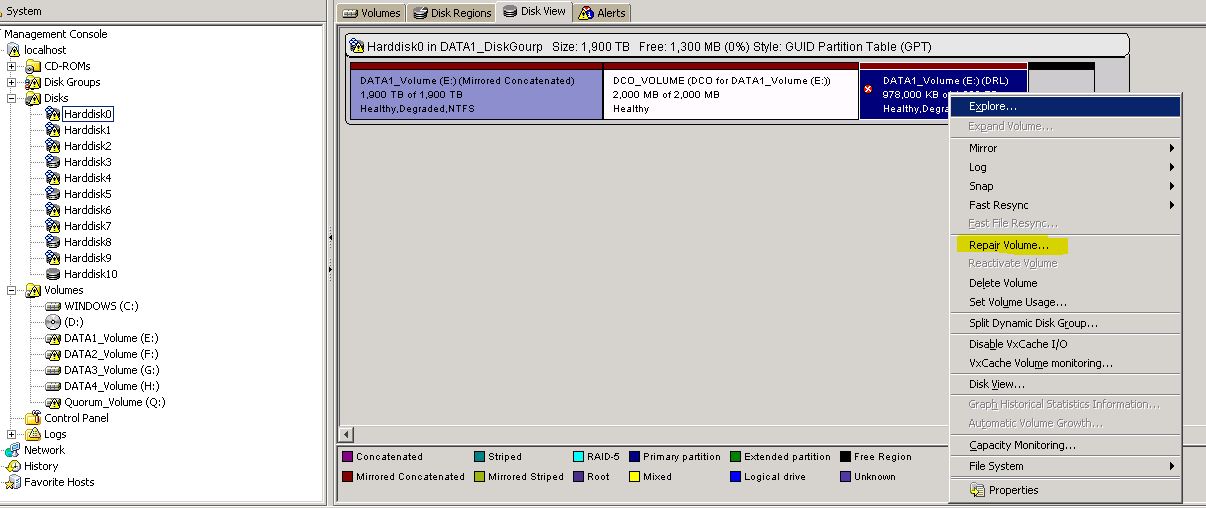
sorry they are no errors in the even logs expect this I gave you allready.
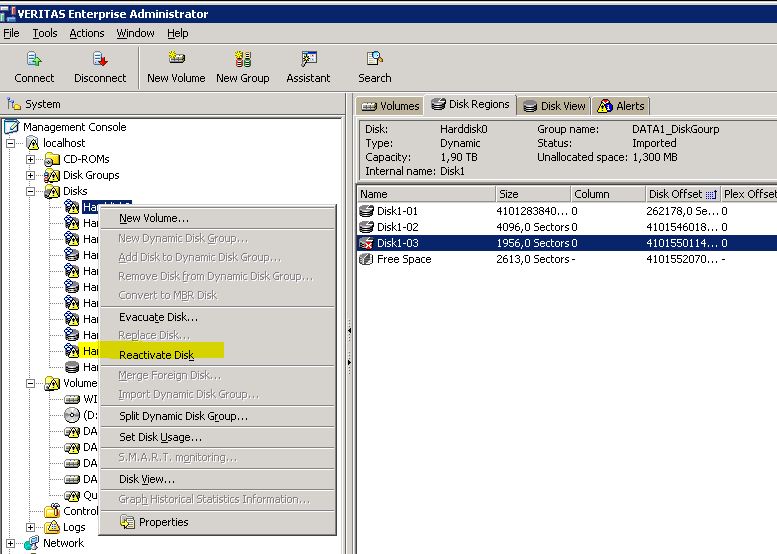
What is about the options repair disk and reactivate disk. See screenshots
This option are only availble on the disks with warnings. On the disks without warnigs this options are grayed out.
Im not sure can i do this without downtime and data lose?
PS. Is that whyt you mean with deport and import ?
The only thing i have found in the help file. is to reactivate the disk, see the screenshot. But i don't really know what gonna happen with the data on the volume, is it still accessble for teh users and do the data still there after i reactivate the disk. :(
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-06-2012 04:39 AM
no one here who can help me?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-06-2012 06:28 AM
Hi,
after reading the thread, I would say Marianne already tried to help you.
As you seem not to be interested in the root cause, I'd say we focus on the next steps you can take. Your volumes are no longer mirrored because one mirror side, called plex, got detached (probably because of a short connection loss).
This is why you see a yellow marker on the volumes. These markers are inherited, so you see them on the corresponding harddisks as well.
Easiest way to get your mirrors back in sync is to "Reactivate Disk" on all disks with a yellow marker. This will start a resync task on your mirrors. Depending on the SAN speed, this can take quite a while and users may have degraded performance because of the high I/O load that a full resync causes.
Therefore I would recommend to do it outside business hours and resync the mirrors one by one.
Hope this helps
Matthias
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-06-2012 07:29 AM
thanks will do that now.
one more thing, is it possible to see which of the disks which are mirrored are at the moment active.
I mean if i open one of the volumes i see two disks, so they are mirrored one of them should be active which is used by the user at the moment. But i can't find the active passive option.
Because i would like to reactivate first the passive disk.
or Im totaly wrong with my supposition?
Thanks all
{kind=link}
- How Do I Find Out A Solution To Tackle Fake Cash App Payment Screenshot Generator? in ApplicationHA
- Dell laptop screenshot in Storage Foundation for Windows
- Replication status for one RLINK is showing as "Activating" in Storage Foundation for Windows
- V-16-20062-55 SVCCopyServices:online:Failed to get the cluster id in Cluster Server
- Oracle Enterprise Manager 12c monitoring of VCS in Cluster Server
