- VOX
- Availability
- Storage Foundation for Windows
- global group takes a long time to go online
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
global group takes a long time to go online
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-26-2014 07:39 PM
Hi everyone,
I'm facing the following problem related with the time to go online for a service group that is configured as a Global Group, in two clusters (Cluster1 and Cluster2) on which the group can come accross (each cluster only has a single server), it is taking a longer time to the service group to come online under a failover event. I am simulating a failover event on the server that is running the service group turning off it, to simulate a power supply cut off on that station! Please is there a parameter that I could modify to reduce this time?
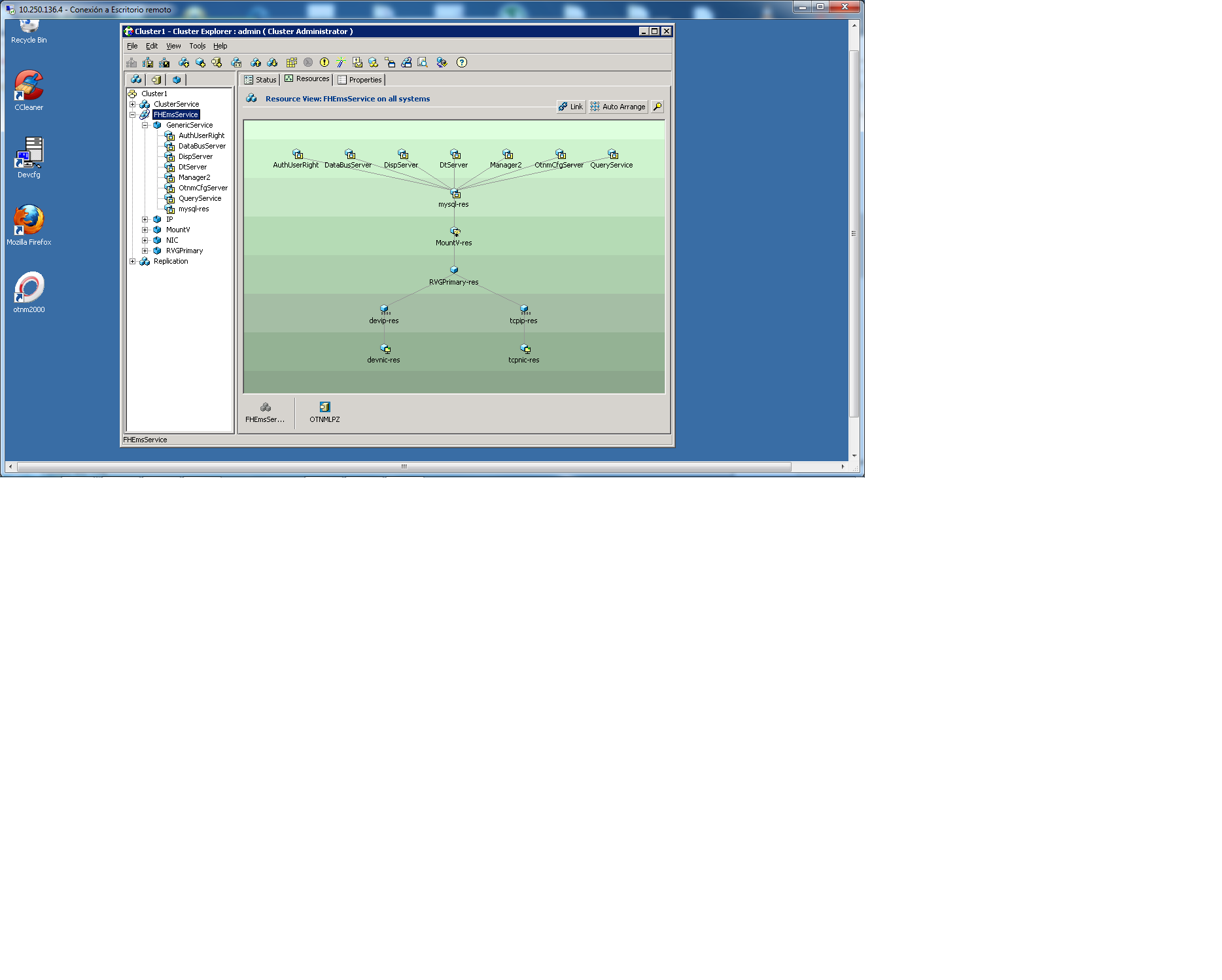
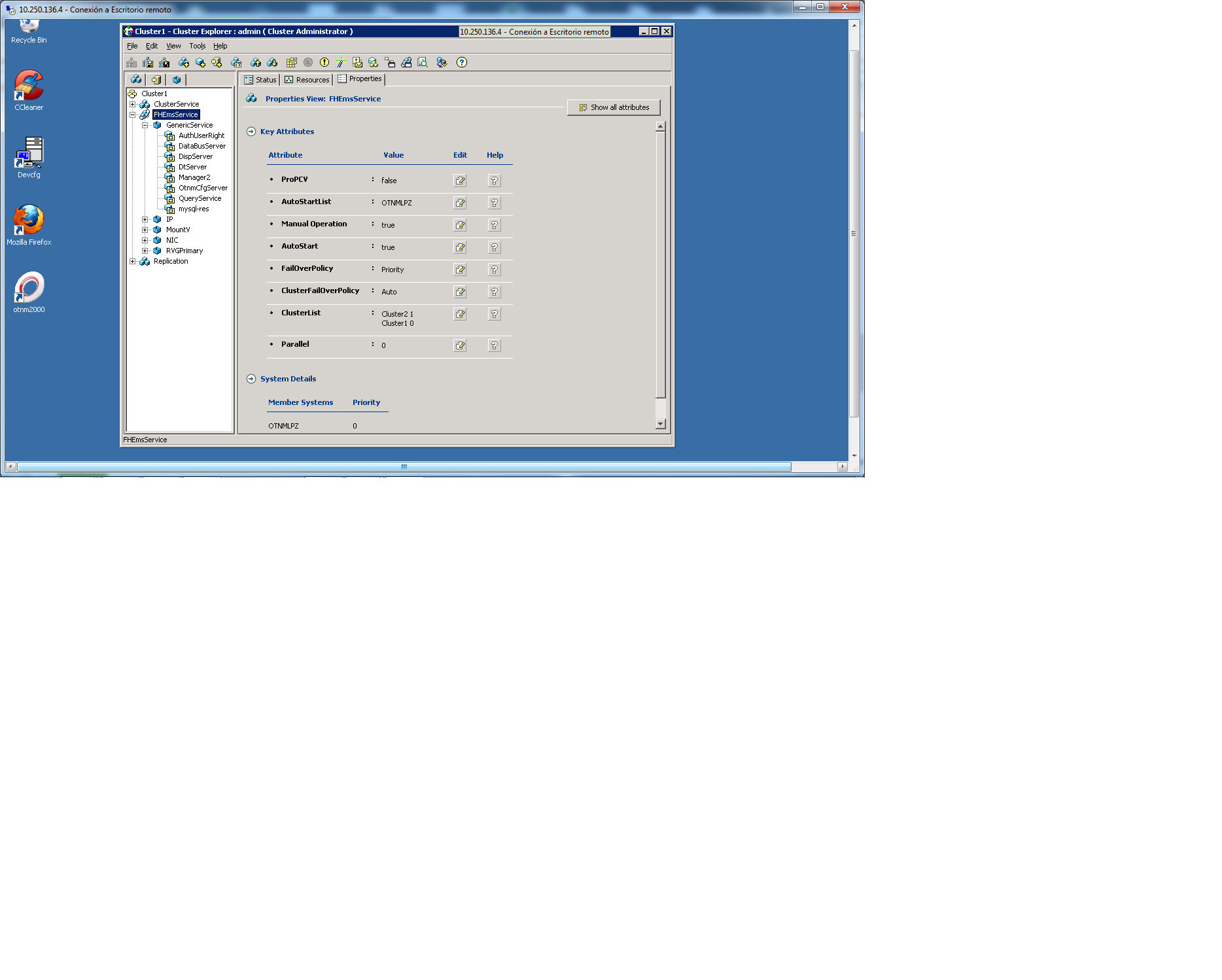
Attached you will find the service group relationship and its properties!
Thank you
Marlon
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-27-2014 02:13 AM
You need to change Global heartbeat attributes (see Heartbeat attributes in Appendix D (VCS Attributes) in VCS user guide:
AYAInterval
The interval in seconds between two heartbeats.
■ Type and dimension: integer-scalar
■ Default: 60 seconds
AYARetryLimit
The maximum number of lost heartbeats before the agent reports that
heartbeat to the cluster is down.
■ Type and dimension: integer-scalar
■ Default: 3
AYATimeout
The maximum time (in seconds) that the agent will wait for a heartbeat
AYA function to return ALIVE or DOWN before being canceled.
■ Type and dimension: integer-scalar
■ Default: 30
AYA stands for "Are You Alive" so you can change these in Java GUI by going to:
Edit- Configure Heartbeats - Select "Existing Heartbeat" radio button and then click on icon in configure column and change "Are You Alive" settings.
You can also change from the CLI using "hahb -modify"
It will still take a while to faiover after changing these, so if you want quicker then if your sites are close together (less than about 80km) then you should configure an RDC rather than GCO (search for "GCO RDC" in forum for more information on this).
Mike
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-28-2014 06:06 AM
Hi Marlon,
In addition to what Mike mentioned, you should try to adjust the ShutDownTimeout value for each node. This value is used to in the overall calculation on how long it takes to determine if a remote site has faulted or is just being rebooted. This is also one of the largest values used in this calculation. This value may need to be decreased or increased to affect fault detection time. I would suggest adjusting this value one way then test. Then adjust it the other way and test again. Set the value that
Another item that look at would be your dependencies, right now you have your RVGPrimary resource coming online after your two IP resources. This is not the typical configuration as the IP resources and the RVGPrimary resource can come online in parallel. This will reduce the online time slightly during a failover/takeover operation. In other words, I would suggest to changing the mysql-res depend on the RVGPrimary-res, devip-res and the tcpip-res resources. Then remove the dependencies from the RVGPrimary-res to the devip-res and the tcpip-res resources.
Thank you,
Wally
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-28-2014 06:09 AM
Hi Marlon,
Sorry, I hit send before I finished rewriting my last sentence in the first paragraph. It should read as follows:
Set the value that inproves failover time. But use caution as this can cause unexpected failover behavior during reboot if set too low.
Thank you,
Wally
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-04-2014 07:33 PM
Thanks a lot dear Wally! I will put on test what you adviced me and consequently I will post the results
Bye
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-04-2014 07:40 PM
Thanks a lot dear Wally! I will test your advice and I will comment you about the results! one question before continuing, where can I find the ShutDown field you mentioned that I could adjust to reduce the time to bring online the service group?
- Unable to see Remote Switch Option for Global Cluster service group in Parallel Service Group config in Cluster Server
- the resource group start after boot but it was freezed in Cluster Server
- Sybase online script exits with 10 in ApplicationHA
- VERITAS Java Console reflect late status in Cluster Server
- global cluster in Cluster Server
