- VOX
- Data Protection
- Backup Exec
- => Ensure that no shadow copy
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-22-2013 02:24 AM
Hi
I have a problem with Oracle job. The job used to run smoothly over the last couple months, however, after recovering from a long catastrophic power failure, we noticed that Backup Exec had a problem with the Oracle job. The rest of jobs are fine, and complete successfully with no errors.
I tried to edit the backup selection, and noticed that the Oracle instance was unavailable and displayed a message about wrong credentials, I retyped the username and password again (sys) but it didn't accept it, so I thought of restarting the remote agent service, and that worked, the Oracle instance status is now Open, and I was able to browse the tablespaces and archived logs. Now I wait until the next backup schedule, the job starts and runs for a about 90 minutes, then fails.
I went to the job log and I could find three different errors, the first two errors are under the Set Information \\oracle\D: an they are as follows:
The first one is
WARNING: "\\oracle\D:\folder1\file1.ext" is a corrupt file. This file cannot verify.
Unable to open the item \\oracle\D:\folder1\file2 - skipped
Unable to open the item \\oracle\D:\folder1\file3 - skipped
..
etc
Directory folder1\ was not found, or could not be accessed.
Nonve of the files or subdirectories contained within will be backed up.
V-79-57344-33967 - The directory or file was not found, or could not be accessed.
The second one is
V-79-57344-65033 - Directory not found. Cannot backup directory \folder2 and its subdirectories.
V-79-57344-65033 - Directory not found. Cannot backup directory \folder3 and its subdirectories.
V-79-57344-65033 - Directory not found. Cannot backup directory \folder4 and its subdirectories.
...
etc
The third error is located right after the Set Information - \\oracle\D: and before the Oracle-Win::\\oracle\instanceid in the job log, and it is as follows:
V-79-57344-34108 - An unexpected error occurred when cleaning up snapshot volumes. Confirm that all snapped volumes are correctly resynchronized with the original volumes.
The job log, however, doesn't show any error for the \\oracle\C:, Oracle-Win::\\oracle\instanceid, or \\oracle\System?State.
I noticed that the Event Viewer on the Oracle server shows the following errors/warning (please notice the timestamp):
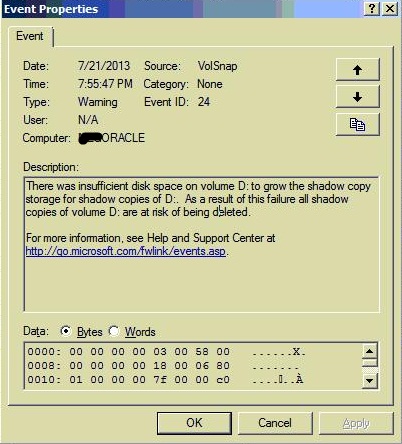
then
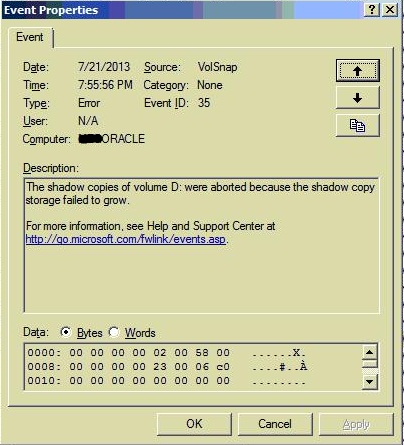
then in the event viewer application category:
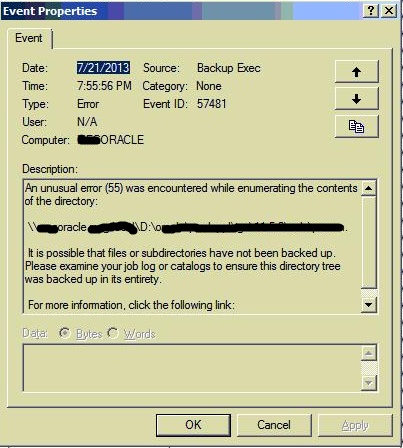
I tried to search all over the Symantec TechNotes and that didn't help.
so I tried to run the job manually to monitor it, and to my surprise, it ran successfully with no single error or warning.
I waited until the next job schedule and it fails again. I run the job manually once more, and again it is a success.
Why does the job fails with the previous errors when it runs automatically, and completes successfully when it is run manually?
Any help is much appreciated.
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-30-2013 01:49 AM
SOLVED!
At first, the database admin didn't agree to install that patch on the Oracle server (!!!) so I thought of schedule the job to run on a different hour.
I went to backup exec to review the job history one more time, and for my surprise I found that the job RAN SUCCESSFULLY. So I headed to the Oracle server to check the event viewer, no event 24 or 35. I went to the D: partitioni which houses the database files, it used to have about %8 of free disk space, which is about 32GB, but now the database admin deleted/moved some unused folders and the free disk space is over 150GB now.
So to sum it up:
- The issue was about free disk space, not high disk I/O.
- The job completes successfully if scheduled to run on a different hour, so there must be some kind of script that runs on the Oracle server -and consumes disk space (temporarily)- on a specific hour (around 8PM) and this is when the backup job is scheduled to run.
Thanks everyone for your support!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-22-2013 02:27 AM
Hi,
Could be that the job is corrupted. Recreate the selection list and the job and schedule it to run...report back with an update.
Thanks!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-22-2013 02:36 AM
Hi,
Of course recreating the job came to my mind, but do I really have to?
I thought there might be a better way to diagnose the issue, find its cause, and develop an appropriate solution, in order to know how to prevent it from happening in the future.
Please if you have any thought or ideas, I'm all ears.
Thank you!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-22-2013 02:44 AM
Is there any antivirus running the scan of the server at the same time during the backup.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-22-2013 03:07 AM
Hello Armit Alok,
The antivirus is scheduled to run on a different time than the backup job. This has always been the case for the last couple months, so no, I don't think it's the antivirus that causes this issue.
thanks for your input though.
I'm still waiting for your other ideas, I'm ready to troubleshoot that thing until it is fixed.
Thank you!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-22-2013 03:14 AM
...if the job is corrupt then the only way to test this is to recreate it. So that would be a valid troubleshooting step to consider.
Thanks!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-22-2013 03:29 AM
Thank you for your reply.
As I mentioned, the job completes successfully if I right-click on it, and choose "Run now". So why do you suggest that the job is corrupt?
I am capable of running the job manually, and the Oracle data is protected, so, I do not want to rush in and delete/recreate the job, unless I'm out of ideas
Thank you!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-22-2013 03:41 AM
Use, don't use...it's been suggested on plenty of forum queries around similar issues and this was part of troubleshooting the issue. In some cases, it worked, and in others it didn't.
Up to you really. I've had Symantec tell me to recreate jobs as something corrupts in the job (read: BEDB) and this has fixed 1 or 2 problems I've had.
Thanks!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-22-2013 11:55 AM
Hello Ahmad the event id which you are getting on the oracle server while running the job, it is possible that there could be another shadow copy running on the server it self which is causing the issue, check the shadow copy status on the server ypu can simply right click on D drive go to prorperties and select shadow copies see if it says disabled or enabled and the size its using, you can even go ahead and specify limit in there, that could be an issue,

another thing you can check is backup exec Advance open file option if you have it enabled disable it and than check, if this does not work than as craig mentioned there could be a corruption in job so you can eighter reschedule or edit the job and in schedule select the option run now and submit job on hold save that job. Edit the job again and schedule it again, if there is corruption with scheduling hopefully this should get it fixed.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-22-2013 12:10 PM
check the drive that houses the databases and delete any shadow copies currently on there or set the limit to "no limit"
Also yes, Re-creating the backup should work. If you can't remember what selections you have just check the old job for the selection list name and create a new job from that 9if it is prior to Backup Exec 2012)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-24-2013 02:01 AM
Hello,
As CraigV, MusSeth, and Michael_McNally suggested, I recreated a new job using the settings from the old presumably corrupt job, and scheduled it to run in a different time slot, and it ran flawlessly.
Now It's either the job itself that is corrupt (!!!) , or the time that the old job run in. To eliminate the second possibility, I'm going to put the old job on hold, and re-schedule the new job to run at the same time as the old one and tell you what happens.
Still, if anyone has an explanation to why that all happened, or how to avoid the errors mentioned in my first post when the original backup job is run, I'd be thankful if you could share your thoughts with me.
Thank you!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-24-2013 02:04 AM
...the reason why I suggested this was because I've had it personally, and also seen it repetitively on the forums. A job and selection list are essentially entries into the BEDB. Either repairing the BEDB using BEutility.exe, or simply creating a new backup job/policy and selection list should fix this 99% of the time.
Corruption does happen, but no 2 situations would be the same.
Thanks!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-26-2013 07:56 PM
Hello,
The new job failed when it was re-scheduled to run at the same time as the old job, so maybe Armit Alok's suggestion is correct. To confirm, I scheduled the new job to run at a different time, and it completed successfully as expected. Now to reproduce that faulty scenario, I rescheduled it to run at the same time as the old job, again. I'll wait to see the results and will post the results.
If it failed, then there must be something wrong happening on that hour when the job runs. Either on the backup server or on the backed up server.
If you've seen this issue before, any tip is much appreciated.
Thank you!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-27-2013 03:04 AM
=> Ensure that no shadow copy jobs are running on all the volumes of the Exchange server while the backup kicks in
=> Install or install/reinstall Microsoft patch 940349 on the remote server
http://support.microsoft.com/kb/940349 - Availability of a Volume Shadow Copy Service (VSS) update rollup package for Windows Server 2003 to resolve some VSS snapshot issues .
This patch is only for windows 2003 server.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-29-2013 01:39 AM
After scheduling the new job to run on the same time as the old one, it failed, again.
I checked the event viewer on the Oracle server, and it generated event ID 24 and 35 each time the job fails.
So there must be something happening on the Oracle server that prevents the job from completing.
I know I can simply change the job parameter to run at a different time, but I'm going to give Kunal.Mudliyar's suggestion a try. I'm going to install KB940349 and see the results.
Thank you all for your posts so far!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-30-2013 01:49 AM
SOLVED!
At first, the database admin didn't agree to install that patch on the Oracle server (!!!) so I thought of schedule the job to run on a different hour.
I went to backup exec to review the job history one more time, and for my surprise I found that the job RAN SUCCESSFULLY. So I headed to the Oracle server to check the event viewer, no event 24 or 35. I went to the D: partitioni which houses the database files, it used to have about %8 of free disk space, which is about 32GB, but now the database admin deleted/moved some unused folders and the free disk space is over 150GB now.
So to sum it up:
- The issue was about free disk space, not high disk I/O.
- The job completes successfully if scheduled to run on a different hour, so there must be some kind of script that runs on the Oracle server -and consumes disk space (temporarily)- on a specific hour (around 8PM) and this is when the backup job is scheduled to run.
Thanks everyone for your support!
- MS SQL VADP Application State Capture (ASC) Backups are Fully Recoverable in NetBackup 10.4 in NetBackup
- DFSR backup takes a long time to start data transfer in NetBackup
- After in-place upgrade (2012->2019) Netbackup will not run any backups or restores in NetBackup
- File Server with DFSR and dedupe/compressed partitions in NetBackup
- Offline Primary server recovery in NetBackup
