- VOX
- Data Protection
- NetBackup
- Duplication performance poor
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-03-2014 06:47 AM
Our backup server is NBU Enterprise Server, 7.5.0.7 running on OEL 5.10 (x86), on a Dell R620 server and Dell PVTL 2000 (2 x LTO5 drives), each drive connected via 6Gps SAS interface to NBU server.
We backup several items to disk, among them two Exchange 2010 servers. We need the GRT option as we need to recover items at a message level. The disk is an iSCSI volume, presented rw to the OS as mount point /nfsbackup (/dev/mapper/idatap1 on /nfsbackup type ext4 (rw,_netdev)).
The issue I am running into is what I consider to be poor performance during duplication from disk to tape. We can't get the images off disk fast enough (it's a 1.5TB volume) to make room for the next images. The current situation is a great example. They are both Exchange 2010 GRT images, one from each server.
Job #1: Started 12/02/2014 20:30:44; 55% done (217823232KB of 395169442KB done), est throughput: 4731KB/sec
Job #2: Started 12/03/2014 01:08:54; 54% done (202821632KB of 374121233KB done), est throughput: 6889KB/sec
Interfaces
NBU server: eth1, eth2 on 1Gbps (not bonded) interfaces to storage network; jumbo frames enabled
iSCSI storage: multipathed, 2 interfaces @ 1Gbps each, jumbo frames enabled
I'm monitoring the NBU server interface with Solarwinds, and I'm getting maybe 80MB/s (combined), barely breaking 8% utilization. Now, utilization does peak from time to time (see image at end) but then it always settles down to this level.
Storage Unit: BasicDisk
Maximum concurrent jobs: 12
Fragment size: default (524288 MB is greyed out)
High water mark 70% / Low water mark 30%
Enable Temporary Staging Area checked: Staging Schedule at Frequency of 12 hours, no exclusions or Start Window specified
Other NBU touchfiles
NET_BUFFER_SZ: 262144
NET_BUFFER_SZ_REST: 262144
STAGING_JOB_KB_LIMIT: 157286400
SIZE_DATA_BUFFERS: 262144
SIZE_DATA_BUFFERS_DISK: 1048576
NUMBER_DATA_BUFFERS: 256
NUMBER_DATA_BUFFERS_DISK: 512
Performance graphic
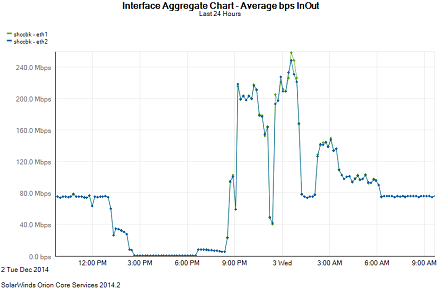
Thanks for any insight and help in advance,
Michelle
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-26-2015 09:46 AM
Marianne / Riaan -
Yes, there is great news to report! After a lot of googling, I found some information which related to iSCSI volume configuration at the disk enclosure (Dell PowerVault MD3000i) and how the OS (OEL 5.10) recognizes the mounted volume on a block level.
Resources used:
- http://en.community.dell.com/techcenter/storage/w/wiki/optimizing-powervault-md3000i-performance
- Performance of read-write throughput with iSCSI: http://www.monperrus.net/martin/performance+of+read-write+throughput+with+iscsi
- Understanding effect of read-ahead on open-iscsi block device: https://groups.google.com/forum/#!msg/open-iscsi/B50Qo9-hpFM/QtFF749WNEAJ
After hurting my brain with all of the above, I adjusted settings on both the PowerVault side AND Linux side to get some screaming performance. I will share the values which worked for me, but for anyone who wants to adjust their settings, please keep these points in mind:
- Your environment is different from mine
- You must understand what you're doing and why.
- And, of course, YMMV.
On the MD3000i side
- Made sure all hardware (disks, controller modules) were up to date with latest firmware
- Increased volume segment size to 256KB
On the NBU master/media server (Oracle Enterprise Linux 5.10)
- Used the blockdev command to understand current disks and their read-ahead/blocksize settings
- Changed all /dev/sdx disk devices(where "x" will be b,c,d...etc) associated with the /dev/dm-n disk device to have a RA (read-ahead) of 4096 (512-byte sectors) and blocksize to 4096 (512-byte sectors).
- Jumbo frames were already set to 9000 on the SAN network.
The goal here is to maximize your throughput without saturation.
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-03-2014 06:58 AM
Sorry - followup to above, bptm log entries for jobs above:
Job #1:
report_throughput: VBRT 1 29709 1 1 IBM.ULT3580-HH5.000 MKM268 0 1 0 10801152 10801152 (bptm.c.25633)
Job #2:
report_throughput: VBRT 1 15594 1 1 IBM.ULT3580-HH5.001 MKM269 0 1 0 10801152 10801152 (bptm.c.25633)
Thanks!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-04-2014 12:37 AM
Hi Michelle,
Tests to perform would be to place a test file (100/200GB) on the Media (or Master) Server connected to the iSCSI disk.
- Back it up to the iSCSI disk storage unit.
- Back it up to the Tape disk storage unit.
- Restore the file from iSCSI disk storage unit.
- Duplicate the file from iSCSI disk storage unit to Tape
Simple tests but it shoulh highlight the problem area. Make sure nothing else is backing up to have clean figures.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-04-2014 06:19 AM
Thanks Riaan. I will try that probably this weekend. One thing I finally noticed - so obvious I feel like a doofus for not seeing it earlier - is that during the initial GRT backup from Exchange 2010 client to iSCSI NFS share (/nfsbackup), the throughput (overall) is great, around 175-200Mbps.

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-04-2014 08:19 AM
Maybe this is due to the message-level cataloging during the duplication. This process is performed on the original client (Exchange) and can really stress the machine and slowdown the duplication. Do you have any powerfull Windows machine (with at least 12 GB RAM) available somewhere that could act as a GRT proxy ?
More info : http://www.symantec.com/business/support/index?page=content&id=HOWTO85754
To give you a rough idea, on my environment, my GRT proxy is 7 times faster than my (very busy) Exchange machines...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-04-2014 09:10 AM
Hi Michelle
That is a valid point, the message cataloging process would take a while so it run fast, then drop.
Are you running multiple streams?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-04-2014 09:11 AM
Fabrice - I wondered about that. I thought (and correct me if I'm wrong lol) that once the metadata was generated sent back to the master/media server (via BPDBM), the .F file was created on the master/media server and no further communication(in my case) with the Exchange Server was necessary, Which means that the only communication should be between the iSCSI mounted NFS share and the master/media NBU server. (Reference: http://www.symantec.com/business/support/index?page=content&id=TECH208798)
A very thoughtful answer and right now I am looking through my VMware environment to see where I can put this beastie. I'm sure this is going to lead down a very detailed and techy rabbit hole...
Thank you, though - besides the 12GB RAM that you suggest, what disk space requirements do I have? I looked at the directory where the .F files are (/usr/openv/netbackup/db/images/<clientnames>) and will go from there (unless I find something else within 5 minutes of posting this).
Michelle
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-04-2014 09:24 AM
Yes. on DSSU I've got Maximum concurrent jobs set to 12, and on tape I've got Max Streams Per Drive set to 10, with 2 max concurrent write drives.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-04-2014 10:14 AM
And the policy, are you kicking of databases individually? That might help.
Also, the setting on the tape is fairly high, i would suggest 2 or 4 max, otherwise you're scattering the data too much.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-04-2014 11:05 AM
Riaan,
Yes, each server has its own GRT policy.
As for the tape settings, I do VMware backups as well but - I can always create another storage unit with different settings, right? And send duplications to that one?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-05-2014 11:22 AM
OK I've done a little tweaking with my settings. Riaan, I found a similar post to mine where you had good input (https://www-secure.symantec.com/connect/forums/duplication-speed-staging-parallel-process), and I've changed my *BUFFER values accordingly.
I've changed my HWM/LWM to 60% / 20% as about 40% of my storage is used up in one backup. Yes, I know it's a small disk, but I'll have more not so far in the future. I figure that as long as I have "headroom" for a full day's worth, that's good.
I set up a VM GRT proxy server with Win 2008R2 using a vmxnet+ adapter manually set to 1G/full duplex. I did a manual bpduplicate -bc_only command on one of the exchange server images and went from 3h 17m to 2h 14m cataloging time. Still have not duplicated it off to tape yet, will be monitoring it over the weekend.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-06-2014 10:19 PM
Hi Michelle
Sounds like you made good progress.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-12-2014 01:00 PM
Update: no real improvement in speed at all. Right now I'm still getting the original speed of transfer, which is about 9000 KB/s which makes for a 12 hour duplication job (from disk to tape) of one 380GB Exchange database (we have 2 Exch DBs but luckily 2 tape drives). The GRT proxy helped with the cataloging speed so that's a tiny bright spot.
I guess I'm perplexed as to why I've got all this bandwidth available and it's not being taken advantage of.
Riaan - because of the slow duplications, it's hard to find a time to do the simple test you suggested but I'll try to find an open window ... to jump out of hahaha! ;)
*sigh*
Thanks!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-13-2014 01:16 AM
you disable the cataloging of granular backups when duplicating to tape. Should improve the speed, but then its just a regular information store image.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-16-2014 10:26 AM
Thanks Riaan, but unfortunately that's not an option for us as we need the granularity of the message-level.
It's definitely an issue with the duplicating back to tape, as the initial backup to disk has a KB/sec of 22K or more. Right now I have 2 duplication jobs running, one Exchange w/GRT and the other a mix of Active Directory and SQL, and they both have a similar throughput (between 8400-9400 KB/s). This makes me a little less inclined to blame the lack of speed on the GRT part of the duplication and more somewhere else...
Might be time to open (another) support case... :)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-16-2014 11:40 AM
Might be time to run those tests. I was at a customer today (build your own dedupe pool) and the dedupe disk performance is about a quarter of the disk where they database resides. The tests i suggested would highlight this.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-16-2014 11:48 AM
Yup, I'm thinking... there might be time this weekend. Cross your fingers!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-26-2015 09:46 AM
Marianne / Riaan -
Yes, there is great news to report! After a lot of googling, I found some information which related to iSCSI volume configuration at the disk enclosure (Dell PowerVault MD3000i) and how the OS (OEL 5.10) recognizes the mounted volume on a block level.
Resources used:
- http://en.community.dell.com/techcenter/storage/w/wiki/optimizing-powervault-md3000i-performance
- Performance of read-write throughput with iSCSI: http://www.monperrus.net/martin/performance+of+read-write+throughput+with+iscsi
- Understanding effect of read-ahead on open-iscsi block device: https://groups.google.com/forum/#!msg/open-iscsi/B50Qo9-hpFM/QtFF749WNEAJ
After hurting my brain with all of the above, I adjusted settings on both the PowerVault side AND Linux side to get some screaming performance. I will share the values which worked for me, but for anyone who wants to adjust their settings, please keep these points in mind:
- Your environment is different from mine
- You must understand what you're doing and why.
- And, of course, YMMV.
On the MD3000i side
- Made sure all hardware (disks, controller modules) were up to date with latest firmware
- Increased volume segment size to 256KB
On the NBU master/media server (Oracle Enterprise Linux 5.10)
- Used the blockdev command to understand current disks and their read-ahead/blocksize settings
- Changed all /dev/sdx disk devices(where "x" will be b,c,d...etc) associated with the /dev/dm-n disk device to have a RA (read-ahead) of 4096 (512-byte sectors) and blocksize to 4096 (512-byte sectors).
- Jumbo frames were already set to 9000 on the SAN network.
The goal here is to maximize your throughput without saturation.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-26-2015 10:06 AM
A previous post I have needs to be approved by the moderators. That contains the nitty-gritty of what I did to get things to where they are now.
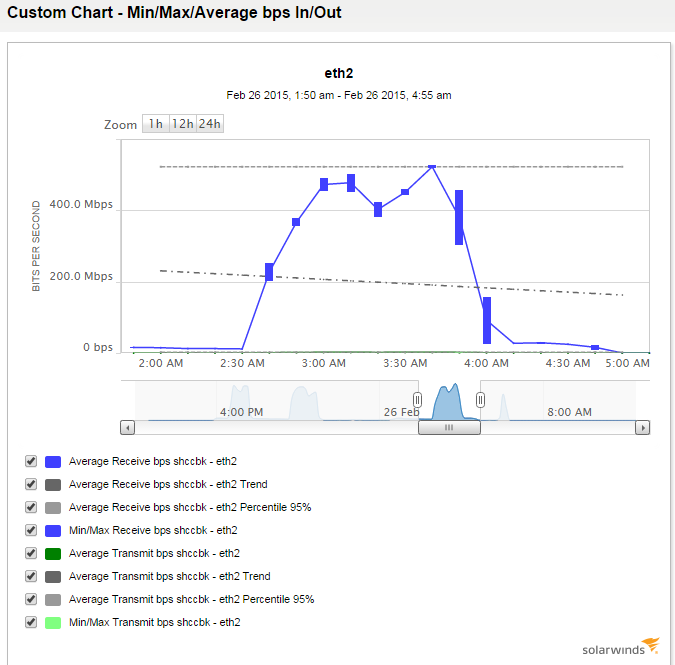
As things stand, from the bptm log of this morning (2015-02-26):
04:02:04.601 [21690] <4> write_backup: successfully wrote backup id S2_1424743377, copy 2, fragment 1, 488105464 Kbytes at 100258.534 Kbytes/sec
That was roughly 488GB in about 83 minutes. Love it!!
This is one of the 2 iSCSI connections (eth1 looks a lot like this).

Thank you all for your help, and I hope this can help out someone else by way of good karma return!
Michelle
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-27-2015 02:10 AM
- Duplication to tape via BYO media server opinion. in NetBackup Appliance
- NetBackup 10.4 Lets K8s Backups Fly Even Higher in NetBackup
- LTO9 tape performance poor - bottlenecks? in NetBackup
- Deduplication - impacts of data the is already compressed, encrypted or large numbers of tiny files. in NetBackup
- Backup of Sybase with Universal Shares gets even better with NetBackup 10.1 in NetBackup
