- VOX
- Data Protection
- NetBackup
- Trouble with Tape drive library
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-25-2018 03:39 AM
I set Netbackup 8.1.1 recently and some time everything worked normally.
My tape library is HP MSL-2024 with LTO7 catridges.
. Now my job have status queued and say me:
25.05.2018 15:34:31 - Info nbjm (pid=5072) starting backup job (jobid=647) for client TMN-FS01.utair.dom, policy TEST-POLICY, schedule Full
25.05.2018 15:34:31 - Info nbjm (pid=5072) requesting STANDARD_RESOURCE resources from RB for backup job (jobid=647, request id:{F8CC856E-49A4-4DCD-B338-0E9E5799FB59})
25.05.2018 15:34:31 - requesting resource tmn-nbu-hcart-robot-tld-0
25.05.2018 15:34:31 - requesting resource tmn-nbu.utair.dom.NBU_CLIENT.MAXJOBS.TMN-FS01.utair.dom
25.05.2018 15:34:31 - requesting resource tmn-nbu.utair.dom.NBU_POLICY.MAXJOBS.TEST-POLICY
25.05.2018 15:34:31 - awaiting resource tmn-nbu-hcart-robot-tld-0. No drives are available.
----------------------------------------------------------------------------------------------------------------------
My library is visible and Inventory run succefully. I see 24 tapes. But drive diagnostics failed.
At first it try mount tape eg. ATA178L7 then wrote than cannot read barcode label.
On second try it wrote that "Drive Information Failed Unable to allocate resources for diagnostics"
Service "NetBackup Device Manager" ( ltid) have status - running
Some information from utilities
tpconfig -l
vmoprcmd -d
robotest amd other
--------------------------------------
vmoprcmd -d -h tmn-nbu
C:\Program Files\Veritas\Volmgr\bin>vmoprcmd -d -h tmn-nbu
PENDING REQUESTS
<NONE>
DRIVE STATUS
Drv Type Control User Label RecMID ExtMID Ready Wr.Enbl. ReqId
0 hcart TLD No Yes Yes 0
ADDITIONAL DRIVE STATUS
Drv DriveName Shared Assigned Comment
0 HP.ULTRIUM7-SCSI.000 No -
---------------------------------------------------
C:\Program Files\Veritas\Volmgr\bin>tpconfig -l
Device Robot Drive Robot Drive Device
Type Num Index Type DrNum Status Comment Name Path
robot 0 - TLD - - - - {4,0,3,1}
drive - 0 hcart 1 UP - HP.ULTRIUM7-SCSI.000 {4,0,3,0}
---------------------------------------------------------------
C:\Program Files\Veritas\Volmgr\bin>robtest.exe
Configured robots with local control supporting test utilities:
TLD(0) robotic path = {4,0,3,1}
Robot Selection
---------------
1) TLD 0
2) none/quit
Enter choice: 1
1
Robot selected: TLD(0) robotic path = {4,0,3,1}
Invoking robotic test utility:
C:\Program Files\Veritas\Volmgr\bin\tldtest.exe -rn 0 -r {4,0,3,1}
Opening {4,0,3,1}
MODE_SENSE complete
Enter tld commands (? returns help information)
s s 5
slot 5 (addr 1005) contains Cartridge = yes
Source address = 1005
Barcode = ATA164L7
----------------------------------------------------------------
C:\Program Files\Veritas\Volmgr\bin>vmoprcmd -h tmn-nbu -timeout 3600 -autoconfig -a
TPAC60 - - - -1~-1~-1~-1 2 - - - 0 - - - - - - - 0 0 - - tmn-nbu.utair.dom 4 - 0 - - - -
TPAC60 HP.ULTRIUM7-SCSI.000 HP~~~~~~Ultrium~7-SCSI~~G9Q1 - 4~0~3~0 1 0 0 1 8 3 - - - 9C1730E870 - 6 0 0 - - tmn-nbu.uta
ir.dom 0 - 0 - - - -
TPAC60 0 HP~~~~~~MSL~G3~Series~~~7.00 - 4~0~3~1 0 0 0 - 8 - 24 1 0 DEC73408KB - 5 0 - tmn-nbu.utair.dom tmn-nbu.utair.d
om tmn-nbu.utair.dom 0 - 0 - - - -
--------------------------------------------------------------------------------------------------------------------------
C:\Program Files\Veritas\NetBackup\bin\admincmd> bpstulist -label tmn-nbu-hcart-robot-tld-0 -U
Label: tmn-nbu-hcart-robot-tld-0
Storage Unit Type: Media Manager
Host Connection: tmn-nbu.utair.dom
Number of Drives: 24
On Demand Only: no
Max MPX/drive: 1
Density: hcart - 1/2 Inch Cartridge
Robot Type/Number: TLD / 0
Max Fragment Size: 1048576 MB
----------------------------------------------------------------------
I again start and configure thru master wizard storage successfully but library dont work.
Yesterday drive test run succesfully/ But test job not run.
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-25-2018 11:45 PM
If no disk jobs running, I'd just run:
nbrbutil -resetall
-why, because you can get 'ghost allocations' that you do not see in nbrbutil -dump output.
Then, stop media manager and delete any files in :
...\netbackup\db\media\drives
...\netbackup\db\media\tpreq
Restart media manager and see if things have improved.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-07-2018 11:37 PM - edited 06-07-2018 11:38 PM
I agree, it is a pain that it does not work, but as you will understand, with the limitation caused by Hyper-V / VMWare with 'physical' devices, we are somewhat limited in what we can do.
I would love to say - go ahead and do this, this, and this and it will kinda work - but then I would not be doing my job, as I would be allowing and encouraging an unsupported config.
Sadly, sometimes the correct answer is 'no, you cannot do this', although it s not what people want to hear.
We have seen in customer cases, and plenty of exaples here on the forum, that people have tried this and suffered constant ongoing issues.
Unsupported tends to mean one of two things:
1. We haven't tested it, so don't know if it will work.
2. It doesn't work, or has intermittant issues.
Your issue comes under number 2.
The worst situation is that a production system is set up and running insome 'unsupported ' config. Then sometime later because of this, it suffers some faiure. If the issue is caused, as in this case, by something external to NetBackup that we have absolutly no control over, then there really is nothing we can do - we can't 'fix' a Hyper-V issue. So you can understand why I may appear to be difficult and unhelpful, but if we had gone ahead and you suffered issues with production data, you can see we would be in a much much worse position.
I thank you for your understanding.
Kindest regards,
Martin
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-25-2018 04:17 AM
It seems you have only one single tape drive and 24 tapes (pieces of media), right?
So, your Storage Unit config is wrong. The 'number of drives' in the config should be 1.
Only one tape can be used in the single tape drive at any point in time.
You can increase the number of of simutaneous jobs by increasing the multiplexing parameter in the Storage Unit config to something like 4 (up to 32 is allowed, but not advisable).
Increase MPX in policy schedules to the same value.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-25-2018 04:41 AM
No. MSL-2024 - its robot tape library with three magazines with 8 catridges LTO-7 in each - (24 catridges in library all together)
https://h20195.www2.hpe.com/v2/GetDocument.aspx?docname=c04154359
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-25-2018 04:48 AM
A cartridge is a tape - one piece of media. Not the same as tape drive.
Your tape library can have only one or two tape drives. Look at the bottom of page 1 of the pdf that you shared:
Maximum Number of Drives 2
Maximum Capacity 720TB (LTO-8, 24 slots)
From the output that you showed, this library has only one tape drive.
So, this one drive can only use one tape/cartridge at any point in time.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-25-2018 05:06 AM
Yes, you are right. One drive can only use one tape/cartridge at any point in time. 24 slots and one drive can move up or down one catridge at one time. So in what I have a problem now?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-25-2018 05:11 AM
See the last part of my 1st reply:
You can increase the number of of simutaneous jobs by increasing the multiplexing parameter in the Storage Unit config to something like 4 (up to 32 is allowed, but not advisable).
Increase MPX in policy schedules to the same value.
Please change the 'Maximum Drives' to 1.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-25-2018 05:17 AM

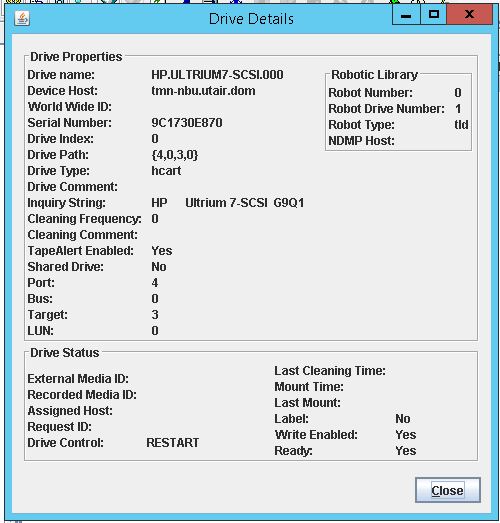{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-25-2018 05:24 AM
You will need to increase MPX in policy schedule(s) as well.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-25-2018 05:37 AM
I change but all the same -
25.05.2018 17:28:28 - awaiting resource tmn-nbu-hcart-robot-tld-0. No drives are available.

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-25-2018 05:46 AM
Changing parameters will not change jobs that have already been submitted.
If there are running or queued job(s), they were submitted with previous parameters.
With NO jobs running and nothing queued, run this command from admincmd:
bprdreq -rereadconfig
Then submit new jobs.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-25-2018 05:58 AM
All jobs were canceled.
bprdreq -rereadconfig
was run without any messages
I start job again and again
25.05.2018 17:56:00 - awaiting resource tmn-nbu-hcart-robot-tld-0. No drives are available.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-25-2018 06:00 AM
Marianne. Thanks for your help but my working day finished. At monday we continue.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-25-2018 06:19 AM
I will be out of town on Monday. Hopefully someone else will respond.
Please post the following on Monday:
Output of policies for which jobs are queued:
bppllist <policy-name> -U
And the same for the job that was running (using the single tape drive).
Please note that multiplexing will only work if all the jobs are going to the same Volume pool and have same retention in the schedules.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-25-2018 08:19 AM
Please check if the drive is allocated and has not be released yet by previous job/allocation/request.
nbrbutil -listActiveDriveJobs HP.ULTRIUM7-SCSI.000
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-25-2018 11:45 PM
If no disk jobs running, I'd just run:
nbrbutil -resetall
-why, because you can get 'ghost allocations' that you do not see in nbrbutil -dump output.
Then, stop media manager and delete any files in :
...\netbackup\db\media\drives
...\netbackup\db\media\tpreq
Restart media manager and see if things have improved.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-27-2018 09:45 PM
I executed your commands and again saw the message - waiting resource tmn-nbu-hcart-robot-tld-0. No drives are available.. But in 1 minute the job started successfully. Also then started old jobs with SLP. I am very glad to it.
Could you explain what occurred at me? And how to avoid such problems in the future? For me it is critical, I have 1 backup which is executed 3 days and then it shall be written on a tape.
Now I have next problem, jobs with SLP were failed:
28.05.2018 9:32:56 - granted resource A163L7
28.05.2018 9:32:56 - granted resource HP.ULTRIUM7-SCSI.000
28.05.2018 9:32:56 - granted resource tmn-nbu-hcart-robot-tld-0
28.05.2018 9:33:59 - Info bptm (pid=6560) media id A163L7 mounted on drive index 0, drivepath {4,0,3,0}, drivename HP.ULTRIUM7-SCSI.000, copy 2
28.05.2018 9:33:59 - Info bptm (pid=6560) INF - Waiting for positioning of media id A163L7 on server tmn-nbu.utair.dom for writing.
28.05.2018 9:34:31 - Warning bptm (pid=6560) cannot locate on drive index 0, The request was not executed because of an input-output error on the device.
28.05.2018 9:35:03 - Error bptm (pid=6560) ioctl (MTFSF) failed on media id A163L7, drive index 0, The request was not executed because of an input-output error on the device.. (1117) (../bptm.c.7046)
28.05.2018 9:35:03 - Info bptm (pid=6560) EXITING with status 86 <----------
28.05.2018 9:35:03 - Error bpduplicate (pid=7576) host tmn-nbu.utair.dom backupid TMN-FS01.utair.dom_1527464151 write failed, media position error (86).
28.05.2018 9:35:03 - Error bpduplicate (pid=7576) Duplicate of backupid TMN-FS01.utair.dom_1527464151 failed, media position error (86).
28.05.2018 9:35:03 - Error bpduplicate (pid=7576) Status = no images were successfully processed.
28.05.2018 9:35:03 - end Duplicate; elapsed time 0:19:18 no images were successfully processed (191)
In messages of other jobs:
28.05.2018 9:24:06 - requesting resource LCM_tmn-nbu-hcart-robot-tld-0
28.05.2018 9:24:06 - granted resource LCM_tmn-nbu-hcart-robot-tld-0
28.05.2018 9:24:07 - started process RUNCMD (pid=7708)
28.05.2018 9:24:07 - ended process 0 (pid=7708)
28.05.2018 9:24:07 - requesting resource tmn-nbu-hcart-robot-tld-0
28.05.2018 9:24:07 - requesting resource @aaaad
28.05.2018 9:24:07 - reserving resource @aaaad
28.05.2018 9:24:07 - awaiting resource tmn-nbu-hcart-robot-tld-0. No drives are available.
28.05.2018 9:24:07 - begin Duplicate
28.05.2018 9:37:06 - Error nbjm (pid=3752) NBU status: 830, EMM status: All compatible drive paths are down, but media is available
28.05.2018 9:37:06 - Error nbjm (pid=3752) NBU status: 830, EMM status: All compatible drive paths are down, but media is available
28.05.2018 9:37:06 - Error nbjm (pid=3752) NBU status: 830, EMM status: All compatible drive paths are down, but media is available
28.05.2018 9:37:07 - end Duplicate; elapsed time 0:13:00
All compatible drive paths are down but media is available (2009)
---------------------------------------------------------------------------------------
I really now dont see drive paths of my robots library in console manager. Why TEST job was run succesfulllly ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-27-2018 10:19 PM
I saw in Device Monitor that library status DOWN. I set it to UP and start TEST job again it run successfully. But SLP jobs failed:
28.05.2018 9:54:07 - begin Duplicate
28.05.2018 9:54:07 - requesting resource LCM_tmn-nbu-hcart-robot-tld-0
28.05.2018 9:54:07 - granted resource LCM_tmn-nbu-hcart-robot-tld-0
28.05.2018 9:54:07 - started process RUNCMD (pid=4496)
28.05.2018 9:54:07 - ended process 0 (pid=4496)
28.05.2018 9:54:07 - requesting resource tmn-nbu-hcart-robot-tld-0
28.05.2018 9:54:07 - requesting resource @aaaad
28.05.2018 9:54:07 - reserving resource @aaaad
28.05.2018 9:54:09 - awaiting resource tmn-nbu-hcart-robot-tld-0. Waiting for resources.
Reason: Drives are in use, Media server: tmn-nbu.utair.dom,
Robot Type(Number): TLD(0), Media ID: N/A, Drive Name: N/A,
Volume Pool: NetBackup, Storage Unit: tmn-nbu-hcart-robot-tld-0, Drive Scan Host: N/A,
Disk Pool: N/A, Disk Volume: N/A
28.05.2018 9:55:12 - resource @aaaad reserved
28.05.2018 9:55:12 - granted resource A163L7
28.05.2018 9:55:12 - granted resource HP.ULTRIUM7-SCSI.000
28.05.2018 9:55:12 - granted resource tmn-nbu-hcart-robot-tld-0
28.05.2018 9:55:12 - granted resource MediaID=@aaaad;DiskVolume=E:\;DiskPool=DISKPOOL-MSA2050;Path=E:\;StorageServer=tmn-nbu.utair.dom;MediaServer=tmn-nbu.utair.dom
28.05.2018 9:55:13 - Info bpduplicate (pid=4496) window close behavior: Suspend
28.05.2018 9:55:14 - Info bptm (pid=4316) start
28.05.2018 9:55:14 - started process bptm (pid=4316)
28.05.2018 9:55:14 - Info bptm (pid=4316) start backup
28.05.2018 9:55:14 - Info bptm (pid=4316) Waiting for mount of media id A163L7 (copy 2) on server tmn-nbu.utair.dom.
28.05.2018 9:55:14 - Info bpdm (pid=7840) started
28.05.2018 9:55:14 - started process bptm (pid=4316)
28.05.2018 9:55:14 - started process bpdm (pid=7840)
28.05.2018 9:55:14 - mounting A163L7
28.05.2018 9:55:14 - Info bpdm (pid=7840) reading backup image
28.05.2018 9:55:14 - Info bptm (pid=4316) INF - Waiting for mount of media id A163L7 on server tmn-nbu.utair.dom for writing.
28.05.2018 9:55:14 - Info bpdm (pid=7840) using 30 data buffers
28.05.2018 9:55:14 - Info bpdm (pid=7840) requesting nbjm for media
28.05.2018 9:55:14 - begin reading
28.05.2018 9:56:21 - Info bptm (pid=4316) media id A163L7 mounted on drive index 0, drivepath {4,0,3,0}, drivename HP.ULTRIUM7-SCSI.000, copy 2
28.05.2018 9:56:21 - Info bptm (pid=4316) INF - Waiting for positioning of media id A163L7 on server tmn-nbu.utair.dom for writing.
28.05.2018 9:56:53 - Warning bptm (pid=4316) cannot locate on drive index 0, The request was not executed because of an input-output error on the device
28.05.2018 9:57:25 - Error bptm (pid=4316) ioctl (MTFSF) failed on media id A163L7, drive index 0, The request was not executed because of an input-output error on the device. (1117) (../bptm.c.7046)
28.05.2018 9:57:25 - Info bptm (pid=4316) EXITING with status 86 <----------
28.05.2018 9:57:30 - Error bpduplicate (pid=4496) host tmn-nbu.utair.dom backup id TMN-FS01.utair.dom_1527289253 read failed, termination requested by administrator (150).
28.05.2018 9:57:30 - Error bpduplicate (pid=4496) host tmn-nbu.utair.dom backupid TMN-FS01.utair.dom_1527289253 write failed, media position error (86).
28.05.2018 9:57:30 - Error bpduplicate (pid=4496) Duplicate of backupid TMN-FS01.utair.dom_1527289253 failed, media position error (86).
28.05.2018 9:57:30 - requesting resource @aaaad
28.05.2018 9:57:30 - granted resource MediaID=@aaaad;DiskVolume=E:\;DiskPool=DISKPOOL-MSA2050;Path=E:\;StorageServer=tmn-nbu.utair.dom;MediaServer=tmn-nbu.utair.dom
28.05.2018 9:57:31 - requesting resource tmn-nbu-hcart-robot-tld-0
28.05.2018 9:57:31 - awaiting resource tmn-nbu-hcart-robot-tld-0. No drives are available.
28.05.2018 9:57:31 - Info bptm (pid=7744) start
28.05.2018 9:57:31 - started process bptm (pid=7744)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-27-2018 11:11 PM
Looks like there may have been old allocations that didn' clear, if the nbrbutil -resetall is the command that got things going.
As to the new issue:
28.05.2018 9:56:21 - Info bptm (pid=4316) INF - Waiting for positioning of media id A163L7 on server tmn-nbu.utair.dom for writing.
28.05.2018 9:56:53 - Warning bptm (pid=4316) cannot locate on drive index 0, The request was not executed because of an input-output error on the device
28.05.2018 9:57:25 - Error bptm (pid=4316) ioctl (MTFSF) failed on media id A163L7, drive index 0, The request was not executed because of an input-output error on the device. (1117) (../bptm.c.7046)
28.05.2018 9:57:25 - Info bptm (pid=4316) EXITING with status 86 <----------
28.05.2018 9:57:30 - Error bpduplicate (pid=4496) host tmn-nbu.utair.dom backup id TMN-FS01.utair.dom_1527289253 read failed, termination requested by administrator (150).
28.05.2018 9:57:30 - Error bpduplicate (pid=4496) host tmn-nbu.utair.dom backupid TMN-FS01.utair.dom_1527289253 write failed, media position error (86).
Seems it is using theis drive / tape
28.05.2018 9:55:12 - granted resource A163L7
28.05.2018 9:55:12 - granted resource HP.ULTRIUM7-SCSI.000
MTFSF fails, that is an issue either between the OS and the tape drive, or the tape drive and media.
I'd freeze that tape and see if it works with other tapes, if not, down that one drive and see if it works with others.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-27-2018 11:41 PM
I freezed A163L7. Frome some minute started old slp job with id= TMN-FS01.utair.dom_1527105580
Now running to the other tape A162L7 go normally
How does the robot tape library select tapes?
And how I start manually other incompleted SLP jobs with other ID ?
I try command but not success :
nbstlutil redo -backupid TMN-FS01.utair.dom_1527202854 -slpindex 1
The redo operation is not currently supported for image copy type 1
( with -slpindex 2 does not work too)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-28-2018 05:02 AM
The robot doesn;t select the tape NBU does.
Generally, it will pick a tape in the correct volume pool that is not full, and has space availble. If none, it will pick a tape in the correct volume pool that is empty, failing thatscratch. There are exceptions, if a backup fills a tape and needs another, it will try and pick from scratch first.
You cannot manually start SLP jobs, just leave it, it will try again on it's own.
- Quantum Superloader 3 w/ LTO7 HH and BackupExec 20.6 in Backup Exec
- Tape library and drives firmware upgrade in NetBackup
- NBU 10x tape 2 tape copy (inline copy) clarification. in NetBackup
- Unable to select target disk in VSR23 bootable usb in System Recovery
- Restore from a standalone drive fail in NetBackup
