- VOX
- Data Protection
- NetBackup Appliance
- interrupt when backup large SQL databases
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-28-2014 06:39 AM
Hi,
Usually MSSQL backups are interrupted at the middle of backup, it success if try again second or third times.
We tried scenerios below,(First tried with version 7.5.0.5, then 7.6.0.1 and result is same) What is the root cause of the problem do you think?
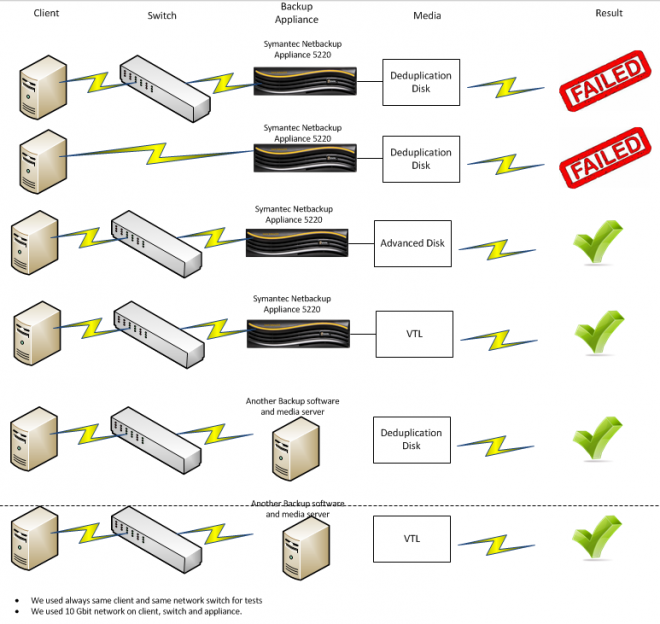
Regards.
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-02-2014 04:16 AM
There is no firewall between the sql server and the Master or Media Server.
Root cause and Solution of the problem:
|
Backline Root Cause Analysis |
||||
|
|
||||
|
|
RCA Author: |
John Peters |
|
|
|
|
||||
|
Error Code/Message |
Error 13 |
|||
|
Diagnostic Steps |
Verbose logging, TCP dumps, Media,Master,client I/O parameter adjustments |
|||
|
Related E-Tracks
|
3445293 |
|||
|
Problem Description |
MS SQL backups are failing randomly if MSDP is used. |
|||
|
Cause |
It is believed that several adjustments that have been done on Master and Media Servers have resolved the issues . Engineering believes that both Network and IO tuning ended the congestion, hence the bottleneck, resulting NBU to successfully complete backups. |
|||
|
Solution |
Master, Media Server and client side, I/O parameter adjustments. |
|||
|
Resolution Criteria |
---- |
|||
|
Description Resolution (if Criteria is not met) |
In our attempts to determine the root cause of the status 13 failures when backing up SQL databases to MSDP using media side deduplication,
From the initial logs we could see that after some time, the dbclient process attempted to send data to the appliance, ie : 16:07:53.335 [17300.26824] <4> VxBSASendData: INF - entering SendData. 16:07:53.335 [17300.26824] <4> dbc_put: INF - sending 65536 bytes 16:07:53.335 [17300.26824] <2> writeToServer: bytesToSend = 65536 bytes 16:07:53.335 [17300.26824] <2> writeToServer: start send -- try=1 16:08:12.224 [17300.26824] <16> writeToServer: ERR - send() to server on socket failed: This message occurs a as a consequence of the OS library call send() returning a non-zero status attempting to send data to a file descriptor ( socket ) that is associated with a network connection. When this failure occurs, dbclient sends a failure status to the media server and bpbrm terminates the job resulting in the status 13. The OS library call to recv() data on the media server does not receive any data or indication from other end of the network connection at the time of the failure which indicates that the TCP stacks on the two hosts are not in agreement on the state of the connection. What we needed to find out was if the problem was occurring in the TCP stack on the client or appliance side of that connection. In order to understand this, it was felt necessary to look at the problem from a TCP level, we hoped that this would show if data was flowing or if there was a plugin ingest issue. For this to happen, we would need to perform network packet capture between the hosts, as well as performing strace on bptm processes together with full debug logging enabled. This approach poses a difficult problem based on the intermittent nature of the failures and the indeterminate time taken for jobs to fail. The resulting logs would be large and the tcpdump / straces enormous. We attempted to work around this by rotating the tcp capture logs and terminating the traces as soon as the job failed in an attempt to capture the critical information. However, when we set this test up, the additional load imposed by the tracing and logging impacted the appliance to such a degree that the backup eventually failed with a 13, unfortunately we do not feel that this failure was the same issue seen for earlier failures. In this case when the job was repeated with tracing turned off it was successful.
In order to try and prevent the issue occuring we made some tuning changes to components we felt were potentially the source of the problem, specifically : 1) Increased the TCP retransmission settings on the client to 15 ( http://support.microsoft.com/default.aspx?scid=kb;en-us;170359) 2) Implemented following settings on the appliance : echo 128 > /usr/openv/netbackup/db/config/CD_NUMBER_DATA_BUFFERS
echo 524288 > /usr/openv/netbackup/db/config/CD_SIZE_DATA_BUFFERS
echo 180 > /usr/openv/netbackup/db/config/CD_UPDATE_INTERVAL touch /usr/openv/netbackup/db/config/CD_WHOLE_IMAGE_COPY echo 0 > /usr/openv/netbackup/NET_BUFFER_SZ echo 0 > /usr/openv/netbackup/NET_BUFFER_REST echo 256 > /usr/openv/netbackup/db/config/NUMBER_DATA_BUFFERS echo 512 > /usr/openv/netbackup/db/config/NUMBER_DATA_BUFFERS_DISK echo 16 > /usr/openv/netbackup/db/config/NUMBER_DATA_BUFFERS_FT
echo 1500 > /usr/openv/netbackup/db/config/OS_CD_BUSY_RETRY_LIMIT
echo 262144 > /usr/openv/netbackup/db/config/SIZE_DATA_BUFFERS echo 1048576 > /usr/openv/netbackup/db/config/SIZE_DATA_BUFFERS_DISK
echo 262144 > /usr/openv/netbackup/db/config/SIZE_DATA_BUFFERS_FT
echo 3600 > /usr/openv/netbackup/db/config/DPS_PROXYDEFAULTRECVTMO echo 3600 > /usr/openv/netbackup/db/config/DPS_PROXYDEFAULTSENDTMO touch /usr/openv/netbackup/db/config/DPS_PROXYNOEXPIRE echo 5000 > /usr/openv/netbackup/db/config/MAX_FILES_PER_ADD 3) Set /usr/openv/pdde/pdcr/etc/contentrouter.cfg PrefetchThreadNum=16 MaxNumCaches=1024 ReadBufferSize=65536 WorkerThreads=128 4) Set /usr/openv/lib/ost-plugins/pd.conf
PREFETCH_SIZE = 67108864 CR_STATS_TIMER = 300
5) Modified the "Client Communication Buffer size"
Host properties --> Client Settings --> Communication Buffer size set to 256kb
6) MSSQL script was modified :
BUFFERCOUNT to 2 STRIPE to 4
7) Additionally we would always advise to check the "resolution" section of this technote http://www.symantec.com/docs/TECH37372.
|
|||
|
|
|
|
|
|
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-28-2014 07:25 AM
If the backup fails after exactly 2 hours (give or take a few seconds) then this is caused by the keepalive settings
From your diagrams i assume the appliance is also a master server but if not you will need to implement keep alive settings on your master server too.
You need to go into the O/S of the appliance:
Support - Maintenance - P@ssw0rd - elevate
Run the following to check the cirrent settings - typical responses shown below:
# cat /proc/sys/net/ipv4/tcp_keepalive_time
7200
# cat /proc/sys/net/ipv4/tcp_keepalive_intvl
75
# cat /proc/sys/net/ipv4/tcp_keepalive_probes
9
To set new values do the following:
# echo 510 > /proc/sys/net/ipv4/tcp_keepalive_time
# echo 3 > /proc/sys/net/ipv4/tcp_keepalive_intvl
# echo 3 > /proc/sys/net/ipv4/tcp_keepalive_probes
These settings take effect immediately so you can test it straight away.
To keep there persistent after a reboot use vi editor to make the additions such as the following to /etc/sysctl.conf file:
## Keepalive at 8.5 minutes
# start probing for heartbeat after 8.5 idle minutes (default 7200 sec)
net.ipv4.tcp_keepalive_time=510
# close connection after 4 unanswered probes (default 9)
net.ipv4.tcp_keepalive_probes=3
# wait 45 seconds for reponse to each probe (default 75
net.ipv4.tcp_keepalive_intvl=3
Then run:
chkconfig boot.sysctl on
If you also have a Master Server do the same on that - if it is Windows it will need regsitry keys adding and a reboot for them to work:
HKLM\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\
New DWORD - KeepAliveTime – Decimal value of 510000
New DWORD – KeepAliveInterval – Decimal Value of 3
See if this helps - applies if they fail after 2 hours (if they fail after 1 hour check for any firewalls between the Master / Media / Client
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-03-2014 12:16 AM
Lovely picture but no details about the backup failure?
What is the status code?
All text in Details tab of failed jobs?
Any useful info in bptm and bpbrm logs on the Appliances?
Have you enabled dbclient log on SQL clients?
Error in these logs?
What is Client Read and Client Connect timeouts set to on the Appliance media servers?
PS:
Please copy log files to .txt (e.g. bptm.txt) and upload as File attachments.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-05-2014 06:11 AM
Hi Mark,
It fails randomly, sometimes at the begining, sometimes in the middle or when the %90.
Hi Marianne,
it gives status code 13 and 6.
actually Symantec support are analysing the logs and I mean which part has problem do you think?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-05-2014 10:25 AM
It could be a timeout, but we will need to see dbclient on SQL client and bptm and bpbrm to know for sure.
Actually - timeout is already VERY high: Client read timeout = 14400
So, this should not be the cause.
Also seems like there is a problem on the client:
3/2/2014 7:20:50 AM - Info dbclient(pid=10124) ERR - Internal error. See the dbclient log for more information.
All of the above logs are needed to troubleshoot.
You have probably already submitted level 5 logs to Symantec.
Let them get on with it. Those logs are W-A-Y too big and time consuming for us 'mere mortals' to try and sift through...
Any errors in Event Viewer Application log?
Or SQL ERROLOG and VDI log?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-05-2014 10:49 AM
An hour and 20 minutes every time - definately sounds like a timeout - that is 4800 seconds so not your client read timeout
Is there a firewall between the sql server and the Master or Media Server?
Did you try the keepalive settings that I suggested?
Having said that they also all fail at 7.20 am - is this a regular time for them to fail? If so have you checked that your SQL admins are not running any database maintenace (SQL dumps etc) on the servers at that time?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-02-2014 04:16 AM
There is no firewall between the sql server and the Master or Media Server.
Root cause and Solution of the problem:
|
Backline Root Cause Analysis |
||||
|
|
||||
|
|
RCA Author: |
John Peters |
|
|
|
|
||||
|
Error Code/Message |
Error 13 |
|||
|
Diagnostic Steps |
Verbose logging, TCP dumps, Media,Master,client I/O parameter adjustments |
|||
|
Related E-Tracks
|
3445293 |
|||
|
Problem Description |
MS SQL backups are failing randomly if MSDP is used. |
|||
|
Cause |
It is believed that several adjustments that have been done on Master and Media Servers have resolved the issues . Engineering believes that both Network and IO tuning ended the congestion, hence the bottleneck, resulting NBU to successfully complete backups. |
|||
|
Solution |
Master, Media Server and client side, I/O parameter adjustments. |
|||
|
Resolution Criteria |
---- |
|||
|
Description Resolution (if Criteria is not met) |
In our attempts to determine the root cause of the status 13 failures when backing up SQL databases to MSDP using media side deduplication,
From the initial logs we could see that after some time, the dbclient process attempted to send data to the appliance, ie : 16:07:53.335 [17300.26824] <4> VxBSASendData: INF - entering SendData. 16:07:53.335 [17300.26824] <4> dbc_put: INF - sending 65536 bytes 16:07:53.335 [17300.26824] <2> writeToServer: bytesToSend = 65536 bytes 16:07:53.335 [17300.26824] <2> writeToServer: start send -- try=1 16:08:12.224 [17300.26824] <16> writeToServer: ERR - send() to server on socket failed: This message occurs a as a consequence of the OS library call send() returning a non-zero status attempting to send data to a file descriptor ( socket ) that is associated with a network connection. When this failure occurs, dbclient sends a failure status to the media server and bpbrm terminates the job resulting in the status 13. The OS library call to recv() data on the media server does not receive any data or indication from other end of the network connection at the time of the failure which indicates that the TCP stacks on the two hosts are not in agreement on the state of the connection. What we needed to find out was if the problem was occurring in the TCP stack on the client or appliance side of that connection. In order to understand this, it was felt necessary to look at the problem from a TCP level, we hoped that this would show if data was flowing or if there was a plugin ingest issue. For this to happen, we would need to perform network packet capture between the hosts, as well as performing strace on bptm processes together with full debug logging enabled. This approach poses a difficult problem based on the intermittent nature of the failures and the indeterminate time taken for jobs to fail. The resulting logs would be large and the tcpdump / straces enormous. We attempted to work around this by rotating the tcp capture logs and terminating the traces as soon as the job failed in an attempt to capture the critical information. However, when we set this test up, the additional load imposed by the tracing and logging impacted the appliance to such a degree that the backup eventually failed with a 13, unfortunately we do not feel that this failure was the same issue seen for earlier failures. In this case when the job was repeated with tracing turned off it was successful.
In order to try and prevent the issue occuring we made some tuning changes to components we felt were potentially the source of the problem, specifically : 1) Increased the TCP retransmission settings on the client to 15 ( http://support.microsoft.com/default.aspx?scid=kb;en-us;170359) 2) Implemented following settings on the appliance : echo 128 > /usr/openv/netbackup/db/config/CD_NUMBER_DATA_BUFFERS
echo 524288 > /usr/openv/netbackup/db/config/CD_SIZE_DATA_BUFFERS
echo 180 > /usr/openv/netbackup/db/config/CD_UPDATE_INTERVAL touch /usr/openv/netbackup/db/config/CD_WHOLE_IMAGE_COPY echo 0 > /usr/openv/netbackup/NET_BUFFER_SZ echo 0 > /usr/openv/netbackup/NET_BUFFER_REST echo 256 > /usr/openv/netbackup/db/config/NUMBER_DATA_BUFFERS echo 512 > /usr/openv/netbackup/db/config/NUMBER_DATA_BUFFERS_DISK echo 16 > /usr/openv/netbackup/db/config/NUMBER_DATA_BUFFERS_FT
echo 1500 > /usr/openv/netbackup/db/config/OS_CD_BUSY_RETRY_LIMIT
echo 262144 > /usr/openv/netbackup/db/config/SIZE_DATA_BUFFERS echo 1048576 > /usr/openv/netbackup/db/config/SIZE_DATA_BUFFERS_DISK
echo 262144 > /usr/openv/netbackup/db/config/SIZE_DATA_BUFFERS_FT
echo 3600 > /usr/openv/netbackup/db/config/DPS_PROXYDEFAULTRECVTMO echo 3600 > /usr/openv/netbackup/db/config/DPS_PROXYDEFAULTSENDTMO touch /usr/openv/netbackup/db/config/DPS_PROXYNOEXPIRE echo 5000 > /usr/openv/netbackup/db/config/MAX_FILES_PER_ADD 3) Set /usr/openv/pdde/pdcr/etc/contentrouter.cfg PrefetchThreadNum=16 MaxNumCaches=1024 ReadBufferSize=65536 WorkerThreads=128 4) Set /usr/openv/lib/ost-plugins/pd.conf
PREFETCH_SIZE = 67108864 CR_STATS_TIMER = 300
5) Modified the "Client Communication Buffer size"
Host properties --> Client Settings --> Communication Buffer size set to 256kb
6) MSSQL script was modified :
BUFFERCOUNT to 2 STRIPE to 4
7) Additionally we would always advise to check the "resolution" section of this technote http://www.symantec.com/docs/TECH37372.
|
|||
|
|
|
|
|
|
- Veritas Backup Exec 23 - Slow Backup after Windows server 2019 upgrade in Backup Exec
- How Do I Backup and Restore My AI Database? A Look Into ChromaDB and AI/LLM Databases in NetBackup
- MS SQL VADP Application State Capture (ASC) Backups are Fully Recoverable in NetBackup 10.4 in NetBackup
- Sooooo…How Are You Getting Your AI Back After a Disaster? in NetBackup
- Oracle database restore from vmware type backup in NetBackup
