- VOX
- Data Protection
- NetBackup
- @jmontagu The backup server
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Duplicate entries for jobs one failed and one successful
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-10-2014 05:55 AM
Hi all,
I would be grateful if someone could help shed some light on this issue that i'm having. I have several policies to back up virtual machines. It seems that for some of the clients the backup times out and retries for second time. The problem that I have is that the first time the job errors with error 23 status 6 then ten minutes later tries again and this time succeeds. What can I do to fix this behaviour as I end up reviewing all the jobs and manually removing the entries for the "failed" ones. Is it possible to get it to only "fail" when it's actually completely failed to complete the backup rather than misleading me into thinking that the job has failed when it succeeded the second time.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-10-2014 06:36 AM
where you are seeing the failed job?
in activity moniter all retires represent as one job with one job id, ..... when you open the deatial status of the job, you can actaully see the number of retires it made...
only job will move to "Done" status when it compleated with all allowed reties.. which is conider as final status of the failure.
so need more details on , where and how you are seeing these failures..
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-10-2014 06:57 AM
I wonder if this is a similar situation to the following:
https://www-secure.symantec.com/connect/forums/retry-done-failedincomplete
In general, we would expect (or hope) that all failed jobs retry as the same id, but there seems to be some inconsistencies where failed jobs can restart as a different job_id which can lead to confusion as to whether there has or hasn't been a successful backup without carrying out further investigation. We have had this ourselves in the past - some jobs retry (same job_id) others restart (different job_id) & in the latter case you can have a failed and successful job for essentially the *same* backup. (There is an explanation in that post as to when a job will restart as opposed to retry)
As far as the quoted discussion is concerned, the solution in that case was to recreate the policy afresh which gave the desired results - this may or may not assist in this case.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-10-2014 08:04 AM
Andy has a good explanation as to the why and a suggestion on how to remedy it. There are also settings in the NetBackup master server properties that can be used to modify the behavior.
Under NetBackup Management --> Host Properties --> Master Servers, right-click on your master server and select the "Global Attributes" section.
The "Schedule backup attempts" and "Job retry delay" can be used to modify how NetBackup handles retries of failed backup jobs.
Check these settings and make sure they meet your requirements. You can get a description of them and their max/min settings by click on the "Help" button at the bottom of that dialog box.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-10-2014 11:01 AM
Modifying Netbackup retry behavior will resolve the issue of having to manually remove the failed job entries, however, rather than change Netbackup's behavior regarding retrys your best solution would be to detemine why the client backups are failing in the first place. If you are consistently seeing the same failures it would be worth your while to determine the cause of the failure, and if possible, correct it thereby improving overall backup performance
The following technote describes the various status codes for VM backups and recommends a soluton for status 23 and 6.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-11-2014 03:04 AM
Thank you all for your prompt help. I'm very grateful.
I'm sorry if I misunderstood you but the problem is that it's the first attempt that fails. How would changing the number of attempts and retries help?
I agree with resolving the root of the problem. Looking at the table in the link you kindly provided, I'm seeing a lot of "Error opening the snapshot disks using given transport mode" errors. I don't understand how the transport mode can be the cause if it succeeds the second time!!
i'm seeing it in the Activity Monitor
It's a new job ID everytime
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-11-2014 03:20 AM
I don't understand how the transport mode can be the cause if it succeeds the second time!!
Maybe too many simultaneous jobs?
Have a look at 'Resource Limit properties' in Master Server Host Properties.
I have seen recommendations varying between 1 and 4 simultaneous backups per Datastore.
The default is 'no limits'.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-11-2014 03:33 AM
So obviously there are two 'issues' here that potentially need attending to:
1. The behaviour of NetBackup with regards to job retry attempts (same job_id) as opposed to restarts (different job_ids) - may be worth seeing what your settings are per Rons post. The settings here *could* determine the behaviour - it maybe that the first job retries so many times - (#retry attempts for the same job_id can be seen in the GUI and Job Details) and then fails, then because the window is still open it restarts (different job_id) and suceeds (maybe following a few more retires). It could be that it is actually working as intended & it's just that the number of failures over a specific time at the start of the backup is resulting in the failure & then a restart later. There could be an issue on the client when the backup initially starts that isn't present when the job eventually succeeds.
2. The actual job failure(s) - may be worth seeing the Job Details for each of the different failure types (you mention 23 *and* 6). Unfortunately I have no VM experience & couldn't shed any more light other than point you to the T/N already quoted by jmontagu or maybe Google(search for site:symantec.com your search string (the Symantec KB search is very poor, sorry)
I do agree with jmontagu though - get to the bottom of the backup failures first, hopefully you can get some further assistance from the guys here.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-11-2014 08:51 AM
If you would like to provide us with the detail status and matching the log from the failing process at verbosity 5 , i.e. in the detail status will say something like; error bprbm (pid xxxx) this means it was the bpbrm process that failed. We would be happy to assist you in resolving the failure.
Additional Note:
My brain has not been fully engaged since returning from vacation. It just occurred to me that it would make perfect sense that the transport mode could be the cause of the failure and why it would suceed on the next attempt. NBU has four transport modes, if one mode fails, it will try the next, and the next until one of the transport modes succeeed! If these VMware backups are consistently failing I would try a different transport mode.
Here is a great previous connect blog:
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-11-2014 11:10 AM
Only one transport mode is active and that's SAN
I've had a look and the global setting is try after 10 minutes and the number of retries is 2
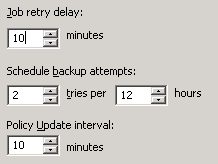
It's currently set to 4 per datastore.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-11-2014 12:04 PM
Here are some best practices for SAN transport type. A copy of your detail status would be very helpful.
Best practices around SAN:
- For using SAN, make sure that datastore LUNs are accessible to the VMware Backup Host.
- SAN transport is usually the best choice for backups when running on a physical VMware Backup Host. However, it is disabled inside virtual machines, so use HotAdd instead on a virtual VMware Backup Host.
- SAN transport is not always the best choice for restores. It offers the best performance on thick disks, but the worst performance on thin disks, because of the way vStorage APIs work. For thin disk restore, LAN(NBD) is faster.
- For SAN restores, disk size should be a multiple of the underlying VMFS block size, otherwise the write to the last fraction of a disk will fail. For example, if virtual disk has a 1MB block size and the datastore is 16.3MB large, the last 0.3MB will not get written. The workaround in this case would be to use NBD for restores of such Virtual Machines.
- When using SAN transport or hot-add mode on a Windows Server 2008/2008 R2 VMware Backup Host, make sure to set:
- SAN policy to onlineAll
- SAN disk as read-only, except during restores
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-11-2014 12:39 PM
- The backup server is indeed a physical box
- the vast majority of our disks are thick provisioned
- All LUNs are accessible to the backup server
- SAN policy is set to OnlineAll
I've changed the number of retries to 5 from 2 and the delay to 20 minutes. I hope this helps. Can't make any changes now that the backup has kicked off.
Thanks ![]()
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-11-2014 02:48 PM
Hopefully you have verbosity set to 5 on the Media server so we can grab some logs if it fails. ![]()
I would love to see the detail status if it fails. A couple of other questions.
1. Is it always the same clients that fail
2. Do the clients fail and then succeed on retry everytime the backup runs or only occasionally.
3. Do you have more than one policy that is backing up the clients that are failing. (on VM's only one backup can run at a time)
Best Regards
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-12-2014 12:30 AM
@jmontagu1. It's quite random. Not the same clients everytime.
2. Most of the time they succeed on the second retry. Sometimes they fail both times.
3. I have several policies and it's happening with clients from all of them quite randomly.
Below is a screenshot from the snapshot and backup logs
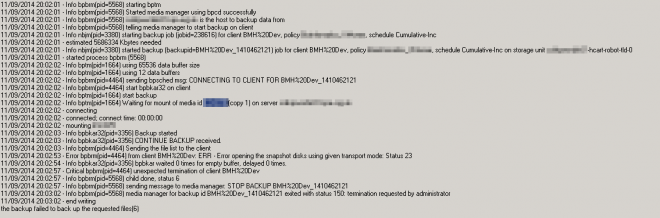

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-13-2014 07:01 AM
I know this probably sounds like a simplistic solution but about 90% of the failures we see are hostname lookup issues.
Please add the following entries to the etc/hosts file of the backup host:
- ESX server in wich the VM run
- Virtual center server
- Virtual machine as well.,
- Client Error (25) in NetBackup
- NetBackup 10.4 Gives AWS Users MORE Security Options with STS Support! in NetBackup
- NBU 10x tape 2 tape copy (inline copy) clarification. in NetBackup
- Final error: 0xe00095a7 - The operation failed because the vCenter or ESX server reported that the in Backup Exec
- Duplication to tape via BYO media server opinion. in NetBackup Appliance
