- VOX
- Data Protection
- NetBackup
- FYI... I updated to 7.6.0.3
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Status Code 156 on VM-policy backup, after seeing Status Code 40 on the VM's previous job.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-25-2014 01:56 PM
So I've googled, and I've read release notes for 7.6.0.3, and I've read the forums; and I could be wrong, but I haven't seen the exact same problem we're having.
NBU Version: 7.6.0.2
Master & Media Servers: Linux RHEL
So a host will back up, and it will get a "network connection broken" message:
| 08/22/2014 22:40:39 - Info bpbrm (pid=15539) rchsp01 is the host to backup data from 08/22/2014 22:40:39 - Info bpbrm (pid=15539) reading file list for client 08/22/2014 22:40:39 - Info bpbrm (pid=15539) starting bpbkar on client 08/22/2014 22:40:39 - Info bpbkar (pid=15546) Backup started 08/22/2014 22:40:39 - Info bpbrm (pid=15539) bptm pid: 15547 08/22/2014 22:40:39 - Info bptm (pid=15547) start 08/22/2014 22:40:39 - Info bptm (pid=15547) using 524288 data buffer size 08/22/2014 22:40:39 - Info bptm (pid=15547) setting receive network buffer to 524288 bytes 08/22/2014 22:40:39 - Info bptm (pid=15547) using 64 data buffers 08/22/2014 23:51:44 - Info nbjm (pid=24060) starting backup job (jobid=851492) for client rchsp01, policy vm_prod, schedule daily_differential 08/22/2014 23:51:44 - Info nbjm (pid=24060) requesting STANDARD_RESOURCE resources from RB for backup job (jobid=851492, request id:{2E12BE56-2A81-11E4-BC68-6423C55F448A}) 08/22/2014 23:51:44 - requesting resource rtxdxip01-stg-itg 08/22/2014 23:51:44 - requesting resource kronos.NBU_CLIENT.MAXJOBS.rchsp01 08/22/2014 23:51:44 - requesting resource kronos.NBU_POLICY.MAXJOBS.vm_prod 08/22/2014 23:51:44 - awaiting resource rtxdxip01-stg-itg. Waiting for resources. Reason: Maximum I/O stream count has been reached for the disk volume., Media server: rchnbump2, Robot Type(Number): NONE(N/A), Media ID: N/A, Drive Name: N/A, Volume Pool: NetBackup, Storage Unit: rchnbump2-rtxdxip01, Drive Scan Host: N/A, Disk Pool: rtxdxip01-dp, Disk Volume: rtxdxip01-lsu 08/22/2014 23:52:26 - granted resource kronos.NBU_CLIENT.MAXJOBS.rchsp01 08/22/2014 23:52:26 - granted resource kronos.NBU_POLICY.MAXJOBS.vm_prod 08/22/2014 23:52:26 - granted resource MediaID=@aaaaj;DiskVolume=rtxdxip01-lsu;DiskPool=rtxdxip01-dp;Path=rtxdxip01-lsu;StorageServer=rtxdxip01-ss_167.254.103.89;MediaServer=rchnbump2 08/22/2014 23:52:26 - granted resource rchnbump2-rtxdxip01 08/22/2014 23:52:26 - estimated 2705020 kbytes needed 08/22/2014 23:52:26 - Info nbjm (pid=24060) started backup (backupid=rchsp01_1408769546) job for client rchsp01, policy vm_prod, schedule daily_differential on storage unit rchnbump2-rtxdxip01 08/22/2014 23:52:27 - Info bpbrm (pid=22162) rchsp01 is the host to backup data from 08/22/2014 23:52:27 - Info bpbrm (pid=22162) reading file list for client 08/22/2014 23:52:27 - Info bpbrm (pid=22162) starting bpbkar on client 08/22/2014 23:52:27 - Info bpbkar (pid=22180) Backup started 08/22/2014 23:52:27 - Info bpbrm (pid=22162) bptm pid: 22181 08/22/2014 23:52:27 - started process bpbrm (pid=22162) 08/22/2014 23:52:27 - connecting 08/22/2014 23:52:27 - connected; connect time: 0:00:00 08/22/2014 23:52:28 - Info bptm (pid=22181) start 08/22/2014 23:52:28 - Info bptm (pid=22181) using 524288 data buffer size 08/22/2014 23:52:28 - Info bptm (pid=22181) setting receive network buffer to 524288 bytes 08/22/2014 23:52:28 - Info bptm (pid=22181) using 64 data buffers 08/22/2014 23:52:28 - Info bptm (pid=22181) start backup 08/22/2014 23:52:32 - begin writing 08/22/2014 23:53:18 - Info bpbkar (pid=22180) INF - Transport Type = nbd 08/22/2014 23:57:21 - Info bpbkar (pid=22180) bpbkar waited 146 times for empty buffer, delayed 28237 times 08/22/2014 23:57:22 - Info bptm (pid=22181) waited for full buffer 583 times, delayed 7421 times 08/22/2014 23:57:40 - Info bptm (pid=22181) EXITING with status 0 <---------- 08/22/2014 23:57:41 - Info bpbrm (pid=22162) validating image for client rchsp01 08/22/2014 23:57:41 - Info bpbkar (pid=22180) done. status: 0: the requested operation was successfully completed 08/22/2014 23:57:41 - end writing; write time: 0:05:09 the requested operation was successfully completed (0) |
When I look in vSphere, I see the following messages:
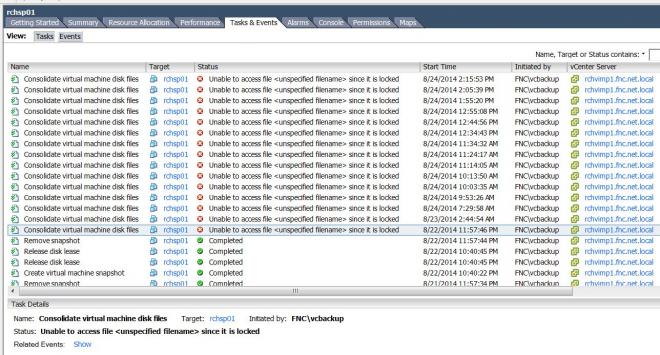
The next backup that runs fails, and from then on fails:
| 08/23/2014 00:00:00 - Info nbjm (pid=24060) starting backup job (jobid=851678) for client rchsp01, policy vm_prod, schedule daily_differential 08/23/2014 00:00:00 - Info nbjm (pid=24060) requesting STANDARD_RESOURCE resources from RB for backup job (jobid=851678, request id:{55F23DD8-2A82-11E4-800B-6FC1A04377BA}) 08/23/2014 00:00:00 - requesting resource rtxdxip01-stg-itg 08/23/2014 00:00:00 - requesting resource kronos.NBU_CLIENT.MAXJOBS.rchsp01 08/23/2014 00:00:00 - requesting resource kronos.NBU_POLICY.MAXJOBS.vm_prod 08/23/2014 00:00:01 - Info nbrb (pid=23985) Limit has been reached for the logical resource kronos.NBU_POLICY.MAXJOBS.vm_prod 08/23/2014 00:01:30 - awaiting resource rtxdxip01-stg-itg. Waiting for resources. Reason: Maximum I/O stream count has been reached for the disk volume., Media server: rchnbump1, Robot Type(Number): NONE(N/A), Media ID: N/A, Drive Name: N/A, Volume Pool: NetBackup, Storage Unit: rchnbump1-rtxdxip01, Drive Scan Host: N/A, Disk Pool: rtxdxip01-dp, Disk Volume: rtxdxip01-lsu 08/23/2014 01:57:23 - Info nbrb (pid=23985) Limit has been reached for the logical resource kronos.NBU_POLICY.MAXJOBS.vm_prod 08/23/2014 02:00:33 - awaiting resource rtxdxip01-stg-itg. Waiting for resources. Reason: Maximum I/O stream count has been reached for the disk volume., Media server: rchnbump1, Robot Type(Number): NONE(N/A), Media ID: N/A, Drive Name: N/A, Volume Pool: NetBackup, Storage Unit: rchnbump1-rtxdxip01, Drive Scan Host: N/A, Disk Pool: rtxdxip01-dp, Disk Volume: rtxdxip01-lsu 08/23/2014 02:04:18 - Info nbrb (pid=23985) Limit has been reached for the logical resource kronos.NBU_POLICY.MAXJOBS.vm_prod 08/23/2014 02:05:32 - awaiting resource rtxdxip01-stg-itg. Waiting for resources. Reason: Maximum I/O stream count has been reached for the disk volume., Media server: rchnbump1, Robot Type(Number): NONE(N/A), Media ID: N/A, Drive Name: N/A, Volume Pool: NetBackup, Storage Unit: rchnbump1-rtxdxip01, Drive Scan Host: N/A, Disk Pool: rtxdxip01-dp, Disk Volume: rtxdxip01-lsu 08/23/2014 02:06:37 - Info nbrb (pid=23985) Limit has been reached for the logical resource kronos.NBU_POLICY.MAXJOBS.vm_prod 08/23/2014 02:31:10 - awaiting resource rtxdxip01-stg-itg. Waiting for resources. Reason: Maximum I/O stream count has been reached for the disk volume., Media server: rchnbump2, Robot Type(Number): NONE(N/A), Media ID: N/A, Drive Name: N/A, Volume Pool: NetBackup, Storage Unit: rchnbump2-rtxdxip01, Drive Scan Host: N/A, Disk Pool: rtxdxip01-dp, Disk Volume: rtxdxip01-lsu 08/23/2014 02:31:17 - Info nbrb (pid=23985) Limit has been reached for the logical resource kronos.NBU_POLICY.MAXJOBS.vm_prod 08/23/2014 02:32:37 - awaiting resource rtxdxip01-stg-itg. Waiting for resources. Reason: Maximum I/O stream count has been reached for the disk volume., Media server: rchnbump1, Robot Type(Number): NONE(N/A), Media ID: N/A, Drive Name: N/A, Volume Pool: NetBackup, Storage Unit: rchnbump1-rtxdxip01, Drive Scan Host: N/A, Disk Pool: rtxdxip01-dp, Disk Volume: rtxdxip01-lsu 08/23/2014 02:35:41 - Info nbrb (pid=23985) Limit has been reached for the logical resource kronos.NBU_POLICY.MAXJOBS.vm_prod 08/23/2014 02:37:41 - awaiting resource rtxdxip01-stg-itg. Waiting for resources. Reason: Maximum I/O stream count has been reached for the disk volume., Media server: rchnbump2, Robot Type(Number): NONE(N/A), Media ID: N/A, Drive Name: N/A, Volume Pool: NetBackup, Storage Unit: rchnbump2-rtxdxip01, Drive Scan Host: N/A, Disk Pool: rtxdxip01-dp, Disk Volume: rtxdxip01-lsu 08/23/2014 02:38:40 - Info nbrb (pid=23985) Limit has been reached for the logical resource kronos.NBU_POLICY.MAXJOBS.vm_prod 08/23/2014 02:44:52 - granted resource kronos.NBU_CLIENT.MAXJOBS.rchsp01 08/23/2014 02:44:52 - granted resource kronos.NBU_POLICY.MAXJOBS.vm_prod 08/23/2014 02:44:52 - granted resource MediaID=@aaaaj;DiskVolume=rtxdxip01-lsu;DiskPool=rtxdxip01-dp;Path=rtxdxip01-lsu;StorageServer=rtxdxip01-ss_167.254.103.89;MediaServer=rchnbump2 08/23/2014 02:44:52 - granted resource rchnbump2-rtxdxip01 08/23/2014 02:44:52 - estimated 2705020 kbytes needed 08/23/2014 02:44:52 - begin Parent Job 08/23/2014 02:44:52 - begin VMware: Start Notify Script 08/23/2014 02:44:52 - Info RUNCMD (pid=19512) started 08/23/2014 02:44:52 - Info RUNCMD (pid=19512) exiting with status: 0 Operation Status: 0 08/23/2014 02:44:52 - end VMware: Start Notify Script; elapsed time 0:00:00 08/23/2014 02:44:52 - begin VMware: Step By Condition Operation Status: 0 08/23/2014 02:44:52 - end VMware: Step By Condition; elapsed time 0:00:00 08/23/2014 02:44:52 - begin VMware: Read File List Operation Status: 0 08/23/2014 02:44:52 - end VMware: Read File List; elapsed time 0:00:00 08/23/2014 02:44:52 - begin VMware: Create Snapshot 08/23/2014 02:44:52 - started process bpbrm (pid=10687) 08/23/2014 02:44:53 - Info bpbrm (pid=10687) rchsp01 is the host to backup data from 08/23/2014 02:44:53 - Info bpbrm (pid=10687) reading file list for client 08/23/2014 02:44:53 - Info bpbrm (pid=10687) start bpfis on client 08/23/2014 02:44:53 - Info bpbrm (pid=10687) Starting create snapshot processing 08/23/2014 02:44:53 - Info bpfis (pid=10698) Backup started 08/23/2014 02:44:53 - snapshot backup of client rchsp01 using method VMware_v2 08/23/2014 02:44:57 - Info bpbrm (pid=10687) INF - vmwareLogger: WaitForTaskCompleteEx: Unable to access file <unspecified filename> since it is locked <232> 08/23/2014 02:44:57 - Info bpbrm (pid=10687) INF - vmwareLogger: WaitForTaskCompleteEx: SYM_VMC_ERROR: TASK_REACHED_ERROR_STATE 08/23/2014 02:44:57 - Info bpbrm (pid=10687) INF - vmwareLogger: ConsolidateVMDisks: SYM_VMC_ERROR: TASK_REACHED_ERROR_STATE 08/23/2014 02:44:57 - Info bpbrm (pid=10687) INF - vmwareLogger: ConsolidateVMDisksAPI: SYM_VMC_ERROR: TASK_REACHED_ERROR_STATE 08/23/2014 02:45:00 - Critical bpbrm (pid=10687) from client rchsp01: FTL - VMware_freeze: VIXAPI freeze (VMware snapshot) failed with 36: SYM_VMC_TASK_REACHED_ERROR_STATE 08/23/2014 02:45:00 - Critical bpbrm (pid=10687) from client rchsp01: FTL - VMware error received: Unable to access file <unspecified filename> since it is locked 08/23/2014 02:45:01 - Info bpbrm (pid=10687) INF - vmwareLogger: RegisterExtensionAPI: SYM_VMC_ERROR: SOAP_ERROR 08/23/2014 02:45:01 - Info bpbrm (pid=10687) INF - vmwareLogger: SOAP 1.1 fault: "":ServerFaultCode [no subcode] 08/23/2014 02:45:01 - Critical bpbrm (pid=10687) from client rchsp01: FTL - vfm_freeze: method: VMware_v2, type: FIM, function: VMware_v2_freeze 08/23/2014 02:45:01 - Critical bpbrm (pid=10687) from client rchsp01: FTL - 08/23/2014 02:45:01 - Critical bpbrm (pid=10687) from client rchsp01: FTL - vfm_freeze: method: VMware_v2, type: FIM, function: VMware_v2_freeze 08/23/2014 02:45:01 - Critical bpbrm (pid=10687) from client rchsp01: FTL - 08/23/2014 02:45:01 - Critical bpbrm (pid=10687) from client rchsp01: FTL - snapshot processing failed, status 156 08/23/2014 02:45:01 - Critical bpbrm (pid=10687) from client rchsp01: FTL - snapshot creation failed, status 156 08/23/2014 02:45:01 - Warning bpbrm (pid=10687) from client rchsp01: WRN - ALL_LOCAL_DRIVES is not frozen 08/23/2014 02:45:01 - Info bpfis (pid=10698) done. status: 156 08/23/2014 02:45:01 - end VMware: Create Snapshot; elapsed time 0:00:09 08/23/2014 02:45:01 - Info bpfis (pid=10698) done. status: 156: snapshot error encountered 08/23/2014 02:45:01 - end writing Operation Status: 156 08/23/2014 02:45:01 - end Parent Job; elapsed time 0:00:09 08/23/2014 02:45:01 - begin VMware: Stop On Error Operation Status: 0 08/23/2014 02:45:01 - end VMware: Stop On Error; elapsed time 0:00:00 08/23/2014 02:45:01 - begin VMware: Delete Snapshot 08/23/2014 02:45:01 - started process bpbrm (pid=10733) 08/23/2014 02:45:01 - Info bpbrm (pid=10733) Starting delete snapshot processing 08/23/2014 02:45:02 - Info bpfis (pid=10777) Backup started 08/23/2014 02:45:02 - Critical bpbrm (pid=10733) from client rchsp01: cannot open /usr/openv/netbackup/online_util/fi_cntl/bpfis.fim.rchsp01_1408779892.1.0 08/23/2014 02:45:02 - Info bpfis (pid=10777) done. status: 4207 08/23/2014 02:45:02 - end VMware: Delete Snapshot; elapsed time 0:00:01 08/23/2014 02:45:02 - Info bpfis (pid=10777) done. status: 4207: Could not fetch snapshot metadata or state files 08/23/2014 02:45:02 - end writing Operation Status: 4207 Operation Status: 156 snapshot error encountered (156) |
The Windows admin says that snapshots end up being created each backup, but cannot deleted for this host... because of the "locked" file mentioned in the screenshot above.
Has anyone else seen this? I have opened a case as well but was just curious what others have seen...
This only started occuring a couple weeks ago; before that it was fine; about 2-3 fail per week, out of about 150, and they are never the same hosts...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-25-2014 03:25 PM
Hello,
There was an issue where vStorage snapshots are orphaned due to "Unable to access file since it is locked" error during snapshot deletion. TECH181118. Bpfis delete is getting called before bpbkar is done closing the VDDK connection. VMware also has a doc talking about this
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-26-2014 06:02 AM
Hi Terry,
Thank you for the tech note page and VMware doc. We have plans to upgrade from 7.6.0.2 to 7.6.0.3 (I think that's what you meant, grin) tomorrow. I have already upgraded our OpsCenter server (and ran into a CPU-pegged situation, which Symantec support sent me an EEB to fix).
...and what I have been trying to find out is if 7.6.0.3 will resolve this issue. Yours is the first reference directly to the lock-file situation that we have seen, and I appreciate it.
After our upgrade, I'll report back in the next week or so and let you know how it's going. You are appreciated!
Susan
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-26-2014 06:38 AM
...there is some concern at our end because this article says it was fixed in 7.6... while we are at 7.6.0.2. I'll talk to the support tech about this when he gets in, in a few hours...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-26-2014 03:30 PM
Glad to hear that your on the right track. :)
You have a great point. The article does reference an older version then your running. After the 7.6.0.3 upgrade, I would be curious to see if that resolves it. Even if it does not, adding the registry keys InfiniteWaitForBpbkar and WaitDiskLeaseRelease could still resolve this behavior.
Please let me know as we will want to get a support case open for engineering.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-27-2014 09:04 AM
I have the same issue on 1 of my 130 VM. I use a N5230 with OS 2.6.0.3 (=7.6.0.3)...
I'm waiting for Spitman news :)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-27-2014 09:21 AM
Ok, so hopefully some good news.
I have performed the 7.6.0.2 - 7.6.0.3 upgrade. Because I was trigger happy I called Symantec for support. (I had the server upgrade package un-tarred in the /tmp dir, but not the client one, and the install was erroring out because of this. Not explicitly spelled out in the installation instructions, at least not for me to see it...)
When I talked to a tech (already had a case open), the first thing he asked me is if my master/media servers are Linux. Interesting; this is the first time I'd been asked this; and I said yes.
He said, "There's a patch for that." (Insert Apple joke here)
Through a webex he passed me this: eebinstaller.3538035.1.linuxR_x86 which, if I remember correctly, he told me is for both 7.6.0.2 and 7.6.0.3--and is specifically for Linux servers, to address this issue; and it had to do with multi-threading (or lack thereof).
So after installing the patch, bringing up Netbackup on all master/media servers for good measure, shutting them all down (to include PBX), installing the EEB, and bringing everything gracefully back up, I am up and running.
Now I wait. (failures generally have been happening for me on Thursdays and Fridays, "heavy lifting" days.)
Side note: So my first name is Susan, and my last name is Pitman; so my username is, yes, spit man, "spitman." (On my kids school website, it's pitmasus, and I'm not sure which is worse...)
I'll check in after the weekend with news, good or bad.
- Susan
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-29-2014 09:22 AM
Yes that EEB is for "linux bpbkar is core dumping during vmware backups". I didn't see a coredump from the logs you posted, but that just might be it! Let us know.
I found your case, so I will be watching that as well.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-22-2014 06:54 AM
Sorry to take so long to get back to this, was at the customer forum last week...
The 156 errors appear to have gone away. At the customer forum, I found out that I was certainly not the only customer experiencing this error.
I was also told this update is going to be rolled into 7.6.0.4, which I believe is due out soon.
Hope this helps :)
Susan
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-26-2014 12:53 PM
FYI... I updated to 7.6.0.3 to fix this very problem. It was advertised that this was the fix. Unfortunately, I'm still seeing locked VM files. The only solution is to stop the services on the media server backing up VMWare stuff (in my case, it's an appliance... also updated to the same rev) and restart them. This releases the lock. Or, if you prefer, you can restart the management services on the ESX host for the VM in question.
Is this every going to be fixed? It's a pain in the back side. Given the maturity of VMWare, as well as the maturity of NetBackup software (and the years of experience/cynergy between these products), I'm scratching my head as to how the latest version of an enterprise backup software can still have this kind of issue.
Don't get me wrong, I like the product and have been using it for years, but this sort of problem shouldn't happen - especially after the "fix" was announced (causing me to spend a lot of time updating all the components). It's basic, and a killer in environments that are highly virtualized (like mine).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-30-2014 06:03 AM
@I like 3.14 - Did you just upgrade to 7.6.0.3? Or did you call support and install the EEB as well?
- WebUI does not update bp.conf on the offline node of the clustered Primary server in NetBackup
- Late Breaking News and Important Updates about NetBackup Flex Appliances Article in NetBackup Appliance
- **UPDATE UPDATE UPDATE** Alta Recovery Vault in NetBackup
- Late Breaking News and Important Updates about NetBackup Flex Appliances in NetBackup Appliance
- Netbackup incorrectly assigning MediaIDs at first but corrects when deleted & re-scanned. in NetBackup
